

티스토리 뷰
Paper/Conversion
[Paper 리뷰] Expressive-VC: Highly Expressive Voice Conversion with Attention Fusion of Bottleneck and Perturbation Features
feVeRin 2024. 12. 28. 09:59반응형
Expressive-VC: Highly Expressive Voice Conversion with Attention Fusion of Bottleneck and Perturbation Features
- Voice conversion은 speaker similarity, intelligibility, expressiveness 측면에서 한계가 있음
- Expressive-VC
- Neural bottleneck feature approach와 information perturbation approach를 결합한 end-to-end voice conversion model
- Bottleneck feature encoder와 perturbe wav encoder를 사용하여 linguistic, para-linguistic feature를 학습하는 content extractor를 구성
- Attention mechanism을 통해 linguistic, para-linguistic information을 fusion 하고, decoder는 integrated feature와 speaker-dependent prosody feature를 기반으로 converted speech를 생성
- 논문 (ICASSP 2023) : Paper Link
1. Introduction
- Human speech는 linguistic, para-linguistic, non-linguistic aspect로 나눠질 수 있고 각각 language, rhythmic-emotional, speaker identity를 represent 함
- 특히 Voice Conversion (VC)는 주어진 speech에서 speaker-related information을 변경하여 다른 speaker처럼 들리게 하는 것을 목표로 함
- 이를 위해서는 source audio에서 speaker-relevant, speaker-irrelevant information을 분리하고 speaker-irrelevant information을 target speaker에 전달해야 함
- BUT, component가 speech에 highly entangle 되어 있다는 어려움이 있음 - 따라서 대부분의 disentanglement approach는 specific module, loss 등을 통해 learned feature가 linguistic content나 speaker identity를 represent 하는 것을 constraint 함
- 대표적으로 VQMIVC는 vector quantization, AGAIN-VC는 adaptive instance normalization을 도입하여 speaker-related information을 제거한 pure linguistic-related feature를 얻음
- BUT, reasonable target speaker similarity를 유지하기 위해서는 transferred expressiveness에 대한 empirical compensation이 있어야 함
- 그렇지 않은 경우 source speaker timbre leakage가 발생할 수 있음
- 한편으로 VC model 외부에서 disentanglement를 수행할 수도 있음
- 대표적으로 Phonetic PosteriorGram (PPG)나 BottleNeck Feature (BNF)를 활용함
- BNF는 neural network bottleneck layer에서 time에 따른 node activation set로 얻어지고 PPG는 neural network에서 phonetic posterior probabilistic vector sequence를 stacking 하여 얻어짐 - 해당 BNF/PPG는 linguistic-rich, speaker-independent, noise-robust 하다는 장점이 있음
- BUT, BNF/PPG는 대부분 linguistic information 만을 포함하므로 expressiveness가 떨어짐
- 대표적으로 Phonetic PosteriorGram (PPG)나 BottleNeck Feature (BNF)를 활용함
- 최근에는 VC를 위해 information perturbation 방식이 도입되고 있음
- Information perturbation은 signal processing을 통해 unwanted information을 제거하여 essential information 만을 학습하도록 하는 방식
- Information perturbation은 target speaker에 대한 similarity를 유지하면서 source speech의 모든 expression을 transfer 할 수 있음
- BUT, perturbation parameter가 empirically select 되므로 intelligibility와 robustness 측면에서 한계가 있음
-> 그래서 highly expressive VC task를 위해 bottleneck feature approach와 information perturbation을 결합한 Expressive-VC를 제안
- Expressive-VC
- BNF encoder와 Perturbed-wav encoder를 사용하여 linguistic/para-linguistic feature를 학습하는 content extractor를 구성
- Scaled dot-product attention mechanism을 통해 linguistic/para-linguistic feature를 fuse
- 최종적으로 decoder는 fused feature와 speaker-dependent prosody feature를 기반으로 converted speech를 생성
< Overall of Expressive-VC >
- Bottleneck feature approach와 information perturbation을 결합한 end-to-end expressive VC model
- 결과적으로 기존보다 뛰어난 expressiveness와 speaker similarity를 달성
2. Method
- Expressive-VC는 Bottleneck Feature (BNF)에 포함된 robust linguistic information과 speaker-attribute-perturbed wave (Perturbed wave)에 포함된 rich para-linguistic information을 fusion 함
- 구조적으로는 Content Encoder, Prosody Encoder, Decoder, Discriminator로 구성됨

- Content Extractor
- Content extractor는 BNF encoder, Perturbed wav encoder, fusion module로 구성됨
- Encoder는 각각 source speech에서 linguistic, para-linguistic feature를 학습하는 역할
- Fusion module은 두 feature를 fuse 하여 더 나은 expressivity와 intelligibility를 제공하는 역할
- BNF & Perturbed-Wav Encoder
- BNF encoder는 BNF를 input/output linguistic embedding $H_{b}$로 사용하여 source speech에 대한 linguistic embedding을 생성함
- Perturbed-wav encoder는 perturbed wave를 input으로 하여 source speech의 para-linguistic embedding $H_{w}$를 생성함
- $H_{b}, H_{w}\in\mathbb{R}^{T\times F}$, $T$ : sequence length, $F$ : embedding dimension - BNF는 source waveform $Y$로부터 pre-trained ASR model을 통해 추출되고 perturbed wave는 pitch randomization $\text{pr}$, formant shifting $\text{fs}$, parametric equalizer 기반 random frequency shaping $\text{peq}$으로 perturbe됨
- $\text{pr}$은 pitch shift와 range scale을 수행하고 $\text{fs}$는 formant shift를 통해 source waveform의 speaker timbre를 변경함
- $\text{peq}$는 다양한 frequency band의 energy를 modifying 하여 speaker-relevant information을 제거함
- 결과적으로 source waveform $Y$에 대한 speaker perturbation process는:
(Eq. 1) $\text{Perturbed-wav} = \text{pr}(\text{fs}(\text{peq}(Y)))$
- 해당 perturbed wave는 speaker-irrelevant 하지만 general linguistic/para-linguistic information은 유지됨
- Feature Fusion Module
- VC를 위해서는 source speech에서 linguistic/para-lingusitc information을 모두 포함하는 robust, rich content representation을 얻어야 함
- 이때 앞선 BNF는 linguistic-rich 하지만 expressivity는 떨어지는 반면 speaker-perturbed wave에서 추출된 embedding은 rich expressive aspect를 가지고 있음
- 따라서 직관적으로 두 feature를 addition 하거나 concatentation 하여 활용할 수 있음
- BUT, linguistic/para-lingustic aspect의 contribution은 time에 따라 달라지므로 dynamic fusion이 수행되어야 함
- Dynamic fusion을 위해 논문은 linguistic feature $H_{w}$와 para-linguistic feature $H_{w}$를 combine 하는 attention-based fusion module을 채택함
- 먼저 $H_{b}, H_{w}$의 concatenation은 key $K\in \mathbb{R}^{T\times 2\times F}$, value $V\in \mathbb{R}^{T\times 2\times F}$로 사용됨
- Prosody encoder output $H_{p}$는 query $Q\in\mathbb{R}^{T\times F\times 1}$로 사용되어 $H_{b},H_{w}$의 linguistic/para-linguistic information을 integrate 함
- 즉, source speaker timbre가 제거된 general prosody pattern을 사용하여 fusion을 weight 함
- 결과적으로 scaled-dot product를 similarity measure로 사용하여 얻어지는 fusion module은:
(Eq. 2) $K=V=\text{concat}(H_{b},H_{w})$
(Eq. 3) $Q=H_{p}$
(Eq. 4) $\text{attention}(Q,K)=\text{softmax}\left(\frac{QK}{\sqrt{F}}\right)$
(Eq. 5) $H_{f}=\text{attention}(Q,K)V$
- Prosody Encoder
- Source speech의 prosody를 preserve 하고 target speech에 대한 high speaker similarity를 보장하기 위해 prosody encoder를 도입하여 speaker-related prosody representation을 학습함
- 먼저 source speech $Y$에서 pitch $f_{0}$와 energy $e$를 추출한 다음, pitch에 z-score normalization을 적용하여 source speaker timbre를 제거함
- 이를 통해 speaker-independent prosody를 얻음 - 이후 Conditional Layer Normalization (CLN)을 적용하여 target speaker embedding을 condition으로 target speaker-related prosody feature $H_{p}$를 생성함:
(Eq. 6) $H_{p}=\text{concat}\left(\gamma \frac{f_{0}-\mu(f_{0})}{\sigma(f_{0})}+\beta, e\right)$
- $\gamma, \beta$ : speaker embedding에 대한 scale/bias vector
- $\mu(f_{0}), \sigma(f_{0})$ : $f_{0}$에 대한 utterance level mean/variance - 결과적으로 $H_{p}$는 fusion module의 attention query로 사용되거나 content extractor output과 함께 decoder로 전달될 수 있음
- 먼저 source speech $Y$에서 pitch $f_{0}$와 energy $e$를 추출한 다음, pitch에 z-score normalization을 적용하여 source speaker timbre를 제거함
- Decoder and Discriminator
- Expressive-VC는 source speech와 target speaker identity를 input으로 하여 explicit vocoder 없이 waveform을 directly reconstruct 함
- 이때 decoder는 Multi-Period Discriminator (MPD), Multi-Scale Discriminator (MSD), Multi-Resolution Spectrogram Discriminator와 같은 multiple discriminator로 구성된 HiFi-GAN의 구조를 따름
- 해당 discriminator를 $D$라고 하고 expressive-vc의 나머지 부분을 generator $G$라고 했을 때, $G, D$의 loss function은:
(Eq. 7) $\mathcal{L}_{G}(Y, \hat{Y})=\mathcal{L}_{adv_{g}}(Y, \hat{Y})+\mathcal{L}_{fm}(Y, \hat{Y}) +\mathcal{L}_{stft}(Y, \hat{Y})$
(Eq. 8) $\mathcal{L}_{D}(Y, \hat{Y})=\mathcal{L}_{adv_{d}}(Y,\hat{Y})$
- $Y,\hat{Y}$ : ground-truth/predicted waveform
- $\mathcal{L}_{adv_{g}}, \mathcal{L}_{adv_{d}}$ : generator/discriminator adversarial loss
- $\mathcal{L}_{fm}$ : feature matching loss, $\mathcal{L}_{stft}$ : multi-resolution STFT loss - 이때 $H_{w}$는 fusion content $H_{f}$에서 waveform $Y_{f}$를 예측하는 것 외에도 waveform $Y_{w}$를 directly reconstruct 하기 위해 사용되므로, overall objective function은:
(Eq. 9) $\mathcal{L}_{total_{G}}(Y,\hat{Y}_{f},\hat{Y}_{w})=\mathcal{L}_{G}(Y,\hat{Y}_{f})+\mathcal{L}_{G}(Y,\hat{Y}_{w})$
(Eq. 10) $\mathcal{L}_{total_{D}}(Y,\hat{Y}_{f},\hat{Y}_{w})=\mathcal{L}_{D}(Y,\hat{Y}_{f})+\mathcal{L}_{D}(Y,\hat{Y}_{w})$
- Training Strategy for Forcing Feature Fusion
- Fusion module은 $H_{b}$에서 linguistic information을 학습하면서 $H_{w}$에서 $H_{b}$가 represent 할 수 없는 para-linguistic information을 추출할 수 있어야 함
- BUT, 실제로는 BNF가 perturbed waveform보다 linguistic information에 relate 되어 있음
- 따라서 BNF encoder에서 linguistic information을 학습하는 것이 perturbed wav encoder에서 linguistic information을 학습하는 것보다 훨씬 쉬움
- 결과적으로 fusion module은 BNF에서 추출한 linguistic information $H_{b}$에만 focus 하는 경향이 있으므로 fusion module과 perturbed wav encoder의 failure가 발생할 수 있음
- 더 나은 feature fusion을 달성하기 위해서는 training 중에 perturbed wav encoder의 convergence speed와 content extraction ability를 개선해야 함
- 이를 위해 논문은 fusion module을 bypass 하여 $H_{w}, H_{p}$를 directly add 한 다음, waveform reconstruction을 위한 decoder에 전달함
- 해당 auxiliary training을 통해 perturbed wav encoder는 waveform reconstruction에 의해 directly guide 되고 더 빠르게 optimize 됨
- 최종적으로 fusion module은 해당 training trick과 prosody encoder가 제공하는 query를 사용하여 $H_{b}, H_{w}$ 간의 reasonable fusion을 수행함
- BUT, 실제로는 BNF가 perturbed waveform보다 linguistic information에 relate 되어 있음
3. Experiments
- Settings
- Dataset : Mandarin Dataset (internal)
- Comparisons : BNF-VC, Perturb-VC, AGAIN-VC
- Results
- 전체적으로 Expressive-VC가 가장 뛰어난 conversion 품질을 보임

- Pitch 측면에서도 Expressive-VC는 높은 correlation을 보임

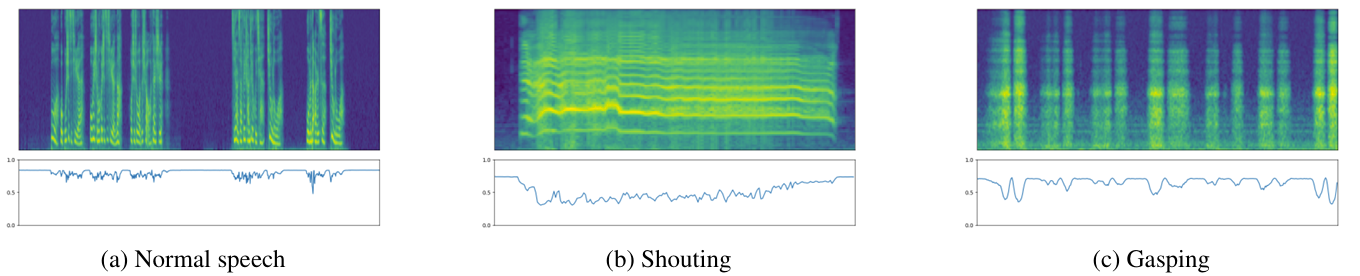
- Visualization on Fusion Process
- Normal speech, shouting, gasping을 source speech로 사용하여 mel-spectrum과 attention weight를 시각화
- (a)의 normal speech와 비교하여 (b), (c)의 weight curve는 perturbed waveform에서 추출된 $H_{w}$가 fusion process에 더 많이 involve 함을 의미함
- 결과적으로 BNF의 $H_{b}$는 linguistic formation을 포함하고 perturbed waveform의 $H_{w}$는 additional para-linguistic information을 포함함
반응형
'Paper > Conversion' 카테고리의 다른 글
댓글