
티스토리 뷰
Paper/Conversion
[Paper 리뷰] DualVC3: Leveraging Language Model Generated Pseudo Context for End-to-End Low Latency Streaming Voice Conversion
feVeRin 2024. 12. 25. 10:45반응형
DualVC3: Leveraging Language Model Generated Pseudo Context for End-to-End Low Latency Streaming Voice Conversion
- 최근의 DualVC2는 180ms의 latency로 streaming voice conversion이 가능함
- BUT, recognition-synthesis framework로 인해 end-to-end optimization이 어렵고 short chunk를 사용하는 경우 instability가 증가함 - DualVC3
- Speaker-independent semantic token을 사용하여 content encoder training을 guide
- Language model을 content encoder output으로 training 하여 future frame을 iteratively predict
- 이를 통해 pseudo context를 생성하고 decoder에 풍부한 contextual information을 제공
- 논문 (INTERSPEECH 2024) : Paper Link
1. Introduction
- Voice Conversion (VC)는 semantic information의 변경 없이 speaker timbre를 다른 speaker timbre로 변환함
- FreeVC, ACE-VC, VQMIVC과 같은 일반적인 VC model은 전체 utterance를 input으로 사용하여 한번에 converted speech를 생성함
- BUT, 해당 방식은 real-time application에 적합하지 않음 - 반면 streaming VC model은 frame/chunk로 input을 처리하고 future information에 대해 causal 하게 동작함
- 이때 future context가 없는 경우 합성 품질이 저하되므로 knowledge distillation을 도입하여 문제를 해결함
- 한편으로 pseudo future context를 예측하는 방법을 사용할 수도 있음
- 해당 방식은 future step을 예측하여 training 되는 language model과 개념적으로 유사함
- 특히 DualVC, DualVC2와 같은 최신 streaming VC model은 대부분 recognition-synthesis framework를 기반으로 함
- 해당 framework는 ASR model을 활용하여 robust semantic information을 추출할 수 있다는 장점이 있음 - BUT, recognition-synthesis framework는 다음의 제한점을 가짐:
- ASR encoder, acoustic model, vocoder로 구성된 multi-level cascaded model 구조로 인해 cascading error가 발생할 수 있음
- Streaming ASR model은 large data chunk가 필요하므로 downstream streaming VC model은 data chunk size를 줄이는데 한계가 있음
- FreeVC, ACE-VC, VQMIVC과 같은 일반적인 VC model은 전체 utterance를 input으로 사용하여 한번에 converted speech를 생성함
-> 그래서 low-latency streaming VC를 위해 DualVC2를 개선한 DualVC3를 제안
- DualVC3
- ASR model을 통해 semantic information을 추출하지 않고 pre-trained semantic token extractor인 Wav2Vec 2.0의 guidance를 활용
- Future context absent의 영향을 줄이기 위해 language model을 사용하여 decoder에 대한 pseudo context를 생성
- DualVC2의 dual-mode training을 따라 conformer-based encoder/decoder를 dynamic chunk mask로 training 하고 Hybrid Predictive Coding (HPC) module, quiet attention을 도입
< Overall of DualVC3 >
- DualVC2를 기반으로 Wav2Vec 2.0 guidance, pseudo context generation을 적용한 streaming VC model
- 결과적으로 기존 DualVC2 수준의 품질을 유지하면서 single core CPU에서 50ms의 low-latency를 달성
2. Method
- System Architecture
- DualVC3는 mel-spectrogram을 input/output으로 사용하는 end-to-end streaming voice conversion model
- 구조적으로 Content Encoder, Decoder, Language Model (LM)으로 구성됨 - Content Encoder
- Content Encoder는 stacked conformer block으로 구성되어 mel-spectrogram을 input으로 사용해 speaker-independent semantic representation을 추출함
- 이때 SSL representation의 $K$-means clustering으로 얻어진 semantic token은 content encoder에 대한 semantic distillation을 위해 사용됨 - 특히 논문은 conformer를 streamable 하게 만들기 위해 Dynamic Chunk Training (DCT)를 도입함
- DCT는 각 self-attention layer에 대한 attention score matrix에 dynamic chunk mask를 적용하여 chunk size를 dynamically varying 함 - 추가적으로 encoder가 추출한 semantic information은 language model과 decoder를 위해 discretize 됨
- Content Encoder는 stacked conformer block으로 구성되어 mel-spectrogram을 input으로 사용해 speaker-independent semantic representation을 추출함
- Language Model
- Language Model은 next-token-prediction 방식으로 discrete semantic information에 대해 training 됨
- 추론 시에는 더 나은 conversion quality를 위해 decoder에 대한 pseudo context를 iteratively generate 함
- Decoder
- Decoder는 content encoder와 동일한 구조를 가짐
- Decoder는 embedded discrete semantic information과 pre-trained speaker encoder에서 추출한 global speaker embedding을 input으로 concatenate 하여 converted speaker timbre를 가진 mel-spectrogram을 생성함
- Hybrid Predictive Coding
- DualVC의 Hybird Predictive Coding (HPC)는 unsupervised representation learning method로써 CPC와 APC를 조합하여 동작함
- 여기서 논문은 content encoder의 intermediate representation에 대한 HPC loss를 계산하여 encoder의 context feature extraction을 향상함

- Semantic Distillation
- Voice conversion은 speech의 semantic information과 speaker timbre 간의 decoupling, recombination으로 볼 수 있음
- 여기서 decoupling process는 VC model 외부에서 수행되거나 model 자체의 fine-grained design을 활용할 수 있음
- 특히 DualVC2는 recognition-synthesis framework를 기반으로 VC model 외부에서 decoupling을 수행함
- BUT, 해당 방식은 pre-trained ASR model을 통해 speaker-independent semantic information을 효과적으로 추출할 수 있지만, 개별적인 ASR system으로 인해 pipeline이 복잡해지고 cascading error가 발생함
- 결과적으로 ASR model로 인해 streaming VC의 latency를 줄이는데 한계가 존재
- 따라서 DualVC3는 external ASR encoder에 대한 dependency를 제거하고 대신 semantic distillation을 위해 Self-Supervised Learning (SSL) model을 도입함
- SSL feature에 대한 $K$-means clustering으로 얻어진 discrete semantic token은 speaker-independent property를 가짐
- 논문은 해당 semantic token을 사용하여 semantic distillation을 수행하고 content encoder training을 guide 함 - Semantic token $S=\{s_{1},s_{2},...,s_{T}\}, s_{i}\in\{1,2,...,N\}$을 input audio signal에서 추출한 integer sequence, $T$를 sequence length, $N$을 $K$-means에 대한 clustering center 수라고 하자
- 그러면 $T_{m}$ frame과 $F$ mel bin을 가지는 input mel-spectrogram $M\in\mathbb{R}^{T_{m}\times F}$로부터 content encoder는 $D$-dimensional intermediate representation $Z\in\mathbb{R}^{T_{m}\times D}$를 추출함
- 이후 $Z$는 semantic token length와 match 하도록 downsampling 되고 $N$-dimension으로 linearly project 되어 $Z'\in\mathbb{R}^{T\times N}$을 얻고, $Z',S$ 간에 Cross-Entropy loss를 계산하여 semantic distillation을 수행함:
(Eq. 1) $\mathcal{L}_{CE}=\text{CrossEntropy}(Z',S)$
- SSL feature에 대한 $K$-means clustering으로 얻어진 discrete semantic token은 speaker-independent property를 가짐
- Residual speaker timbre를 further remove 하기 위해 $Z'$은 discretize 되어 $ZQ=\{zq_{1},zq_{2},...,zq_{T}\}, zq_{i}\in\{1,2,...,N\}$과 같은 information bottleneck을 형성함
- Discretization은 decoder에서 encoder로 gradient를 pass 하는 Gumbel Softmax에 의해 수행됨 - 한편으로 discrete intermediate representation은 streaming VC model에 codec-like capability를 제공할 수 있음
- 실제 client-server 간의 direct audio transfer에는 high network bandwidth가 필요하므로 상당한 latency가 발생함
- BUT, discrete intermediate representation의 경우 bit rate를 크게 줄일 수 있으므로 network overhead와 latency를 절감할 수 있음
- 여기서 decoupling process는 VC model 외부에서 수행되거나 model 자체의 fine-grained design을 활용할 수 있음
- Language Model for Pseudo Context Generation
- 구조와 관계없이 모든 streaming model은 context size로 인해 non-streaming counterpart에 비해 성능이 떨어짐
- 특히 streaming model은 future context에 access 할 수 없으므로 optimal performance를 달성하는 것이 어려움
- 따라서 DualVC3는 input size를 늘리지 않고 20ms의 small context size로도 성능을 보장하기 위해 language model을 활용함
- 아래 그림과 같이 pseudo context generation을 위한 language model은 next-token-prediction 방식으로 discrete intermediate representation $ZQ$로부터 training 됨
- 추론 시 encoder로 encoding 된 chunk $ZQ$가 주어지면, language model은 conditional probability로부터 pseudo context sequence $ZQ'=\{zq'_{1},zq'_{2},...,zq'_{n}\}$을 iteratively sampling 함:
(Eq. 2) $p_{\theta}(ZQ')=\prod_{i=2}^{n}p_{\theta}(zq'_{i}|zq'_{i-1},...,zq'_{1},ZQ)$
- $n$ : 예측할 pseudo context frame, $\theta$ : language model parameter
- 이후 concatenation $\{ZQ,ZQ'\}$이 deocoder에 전달되어 conversion을 수행함
- Pseudo context를 predicting 하는 것은 unconditional continuation process에 해당함
- 따라서 predicted frame 수가 증가할수록 feature는 ground-truth에서 deviate 됨
- BUT, DualVC3는 conformer backbone을 training 하기 위해 DCT를 채택하므로 future context에 decreasing weight를 할당하여 language model prediction error로 인한 intelligibility 문제를 해결할 수 있음
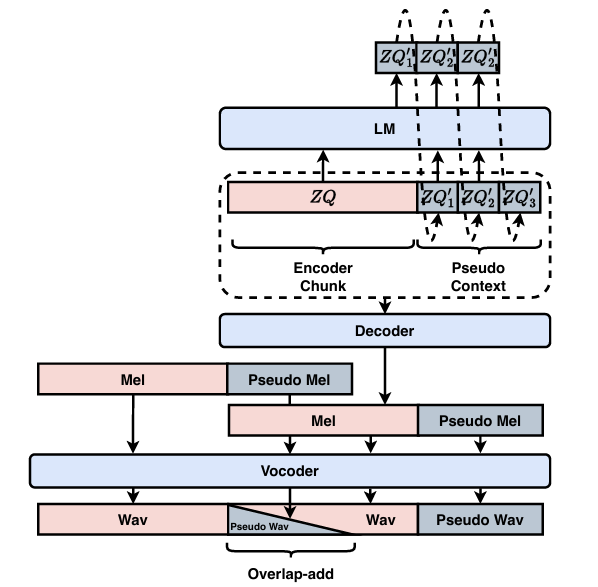
- Training & Inference Procedure
- Training
- Encoder, Decoder를 포함한 acoustic model은 language model과 개별적으로 training 됨
- Acoustic model training objective에는 reconstruction loss, HPC loss, Cross-Entropy loss가 포함됨:
(Eq. 3) $\mathcal{L}_{acoustic}=\alpha\mathcal{L}_{rec}+\beta\mathcal{L}_{HPC}+\gamma \mathcal{L}_{CE}$
- $\alpha=45, \beta=1, \gamma=10$ : weighting term - Reconstruction loss는 ground-truth mel-spectrogram $M$과 generated mel-spectrogram $\hat{M}$간의 MSE loss로 계산됨:
(Eq. 4) $\mathcal{L}_{rec}=\text{MSE}(M,\hat{M})$ - Acoustic model이 수렴되면, DualVC3는 language model training을 위해 discrete intermediate representation $ZQ$를 추출함:
(Eq. 5) $\mathcal{L}_{LM}=-\sum_{i=2}^{T}\log p_{\theta}(zq_{i}|zq_{i-1},...,zq_{1})$
- Streaming Inference
- 추론 시에 HPC와 Wav2Vec 2.0은 discard 되고, DualVC3는 full mode 또는 language model이 제거된 stand-alone mode로 동작할 수 있음
- Full Mode
- 먼저 input mel-spectrogram이 content encoder에 의해 encoding 되고 discretize 되어 $ZQ$를 얻음
- 이후 $ZQ$는 language model에서 예측된 pseudo context, pre-extracted target speaker embedding과 함께 decoder에 전달되어 chunked mel을 output 함
- Decoder에서 생성된 pseudo mel은 vocoder에 전달되어 additional pseudo waveform을 생성하고, chunk 간 smoothing을 위한 overlap-add를 지원함
- Stand-Alone Mode
- Stand-Alone mode에서는 content encoder, decoder를 포함한 acoustic model만 preserve 됨
- Language model의 discard로 인해 computational cost의 이점을 얻을 수 있지만 conversion quality가 다소 저하될 수 있음
3. Experiments
- Settings
- Results
- DualVC3는 20ms chunk size로도 VQMIVC보다 뛰어난 MOS를 달성할 수 있음
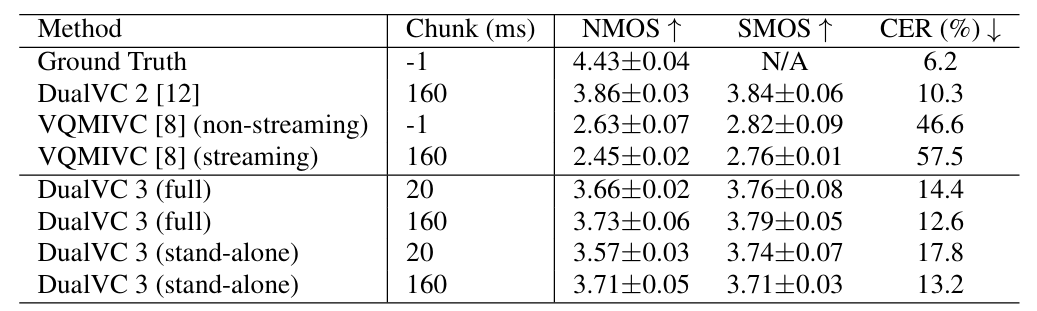
- DualVC3의 overall latency는 stand-alone mode의 경우 43.58ms, full-mode의 경우 55.94ms로 측정됨

- Encoder output에 $t$-SNE를 적용해 보면, discrete semantic token guidance로 인해 speaker-independent semantic information이 성공적으로 추출됨

반응형
'Paper > Conversion' 카테고리의 다른 글
댓글