

티스토리 뷰
Paper/TTS
[Paper 리뷰] PitchFlow: Adding Pitch Control to a Flow-Matching based TTS Model
feVeRin 2024. 11. 17. 12:44반응형
PitchFlow: Adding Pitch Control to a Flow-Matching based TTS Model
- Flow-matching Text-to-Speech model은 stability와 control 측면에서 한계가 있음
- PitchFlow
- Speaker scoring과 pitch guidance를 도입하여 생성된 speech의 timbre와 pitch contour를 control
- Prior에 대한 optimal choice를 통해 similarity를 개선하고 classifier guidance를 통해 fine-grained pitch contorl을 지원
- 논문 (INTERSPEECH 2024) : Paper Link
1. Introduction
- 최근의 Text-to-Speech (TTS) model은 VALL-E, Mega-TTS와 같이 LLM paradigm을 따르고 large decoder-only Transformer architecture에 의존함
- 한편으로 VoiceBox, Matcha-TTS, P-Flow와 같이 Denoising Diffusion Probabilistic Model이나 Flow-Matching framework를 활용할 수도 있음
- 해당 방식은 non-autoregressive 합성이 가능하고 content editing과 denoising을 지원 가능
- 특히 cross-lingual mode에서 speaker의 voice 뿐만 아니라 emotion, style 등을 copy 할 수도 있음
- BUT, stress, focus 등을 정확히 반영하기 위해서는 fine-grained pitch control이 요구됨
- 이를 위해 FastSpeech, YourTTS, Delightful-TTS 등은 pitch curve를 conditioning 하는 방법을 도입함
- BUT, 합성 품질 측면에서 한계가 있음
- 한편으로 VoiceBox, Matcha-TTS, P-Flow와 같이 Denoising Diffusion Probabilistic Model이나 Flow-Matching framework를 활용할 수도 있음
-> 그래서 flow-matching model에서 pitch control과 합성 품질을 향상할 수 있는 PitchFlow를 제안
- PitchFlow
- Prior distribution을 careful choosing하기 위해 speaker classifier를 사용하여 speaker similairty를 향상
- Pitch fildelity를 개선하는 pitch classifier를 도입
< Overall of PitchFlow >
- Pitch classifier와 pre-trained speaker classifier를 활용하여 flow-matching model을 guide
- 결과적으로 기존보다 뛰어난 합성 성능과 controllability를 달성
2. Flow Matching Speech Modeling
- 먼저 flow-matching network는 data distribution $\text{Law}(X_{1})$에 속하는 clean data sample $X_{1}$에 Gaussian noise가 추가된다고 가정함
- 따라서 noisy data sample $\text{Law}(X_{t}|X_{1})$의 conditional distribution은 평균 $\mu_{t}(X_{1})=tX_{1}$과 covariance matrix $\sigma^{2}_{t}(X_{1})I$를 가지는 Gaussian distribution이 됨
- $I$ : data $X_{1}$과 동일한 dimensionality를 가지는 identity matrix
- Small positive number $\sigma_{\min}$에 대해 $\sigma_{t}(X_{1})=1-(1-\sigma_{\min})t$ - $t\in [0,1]$에 대한 conditional density function $p_{t}(x|x_{1})$을 가지는 stochastic process는 다음 conditional vector field를 통해 생성될 수 있음:
(Eq. 1) $u_{t}(x|x_{1})=\frac{x_{1}-(1-\sigma_{\min})x}{1-(1-\sigma_{\min})t}$ - Flow mathcing neural network $v_{\theta}$는 Mean Squared Error (MSE)를 minimizing 하여 해당 vector field를 추정함:
(Eq. 2) $\mathcal{L}_{CFM}(\theta)=\mathbb{E}_{t,X_{1},X_{t}} \left|\left| v_{\theta}(X_{t},t)-u_{t}(X_{t}|X_{1})\right|\right|^{2}_{2}$- $t$ : $[0,1]$에서 uniformly sample, $X_{1}$ : data distribution $\text{Law}(X_{1})$에서 sample, $X_{t}$ : conditional distribution $\text{Law}(X_{t}|X_{1})$에서 sample
- (Eq. 2)의 conditonal flow matching objective를 최적화하는 것은 $v_{\theta}(X_{t},t)$와 unconditional vector field $u_{t}(X_{t})$ 간의 MSE error를 minimizing 하는 것과 같음
- 즉, prior distribution $\mathcal{N}(0,I)$를 $\text{Law}(X_{1})$에 close 한 distribution ($\text{Law}(X_{1})$을 $\mathcal{N}(0,\sigma^{2}_{\min})$으로 convolve 한 것)으로 mapping 하는 것과 같음
- 따라서 trained flow matching model에서 sampling 하는 것은 $t\in [0,1]$ interval에서 다음의 Ordinary Differential Equation (ODE)를 solve 하는 것과 같음:
(Eq. 3) $\dot{X}_{t}=v_{\theta}(X_{t},t)$- Time $t$에 대한 derivative를 $\dot{X}_{t}$라고 하면, 해당 ODE는 $X_{0}\sim\mathcal{N}(0,I)$에서 starting 하여 solve 됨
- 경험적으로 (Eq. 3)의 ODE는 Variance Exploding이나 Variance Preserving과 같은 diffusion model의 probability flow ODE보다 straight 하므로, 더 적은 step 만으로도 우수한 품질을 달성할 수 있음
- 대표적으로 VoiceBox는 해당 flow matching을 도입하여 TTS task를 수행함
- 구조적으로는 phoneme encoder, flow matching network, duration predictor로 구성되고, prompt mel-feature가 주어졌을 때 input speech prompt $X^{prompt}$의 mel-feature와 함께 target mel-feature $X_{1}$을 생성함
- VoiceBox의 flow matching network는 upsampled encoded phoneme sequence $z$로 condition 됨
- Prompt phoneme sequence는 ground-truth duration을 사용하여 upsample 되고, target phoneme sequence는 duration predictor output을 통해 upsample 됨
- Training 시 prompt conditioning $X^{prompt}$는 certain probability $\omega$로 대체되어 classifier-free guidance를 수행함 - 결과적으로 VoiceBox는 다음의 ODE를 solve 하여 sampling을 수행할 수 있음:
(Eq. 4) $\dot{X}_{t}=(1+\alpha)v_{\theta}(X_{t},X^{prompt},z,t)-\alpha v_{\theta}(X_{t},0,z,t)$
- $\alpha >0$ : classifier-free guidance weight
- 구조적으로는 phoneme encoder, flow matching network, duration predictor로 구성되고, prompt mel-feature가 주어졌을 때 input speech prompt $X^{prompt}$의 mel-feature와 함께 target mel-feature $X_{1}$을 생성함
- 따라서 noisy data sample $\text{Law}(X_{t}|X_{1})$의 conditional distribution은 평균 $\mu_{t}(X_{1})=tX_{1}$과 covariance matrix $\sigma^{2}_{t}(X_{1})I$를 가지는 Gaussian distribution이 됨
3. Pitch and Timbre Control
- $X_{t}$를 flow-matching time step $t$에서의 noisy mel-spectrogram이라고 하고, speech synthesis flow-matching model을 $v_{\theta}(X_{t},t)$라고 하자
- Speaker Scoring
- PitchFlow에서 prior sample $X_{0}\sim \mathcal{N}(0,I)$는 generated voice의 timbre에 큰 영향을 미침
- 즉, optimal prior sampel $X_{0}$를 choice 하여 generated speech와 prompt 간의 speaker similarity를 향상 가능
- 따라서 논문은 다음의 Speaker Scoring을 도입함
- 먼저 prior sample의 batch $\{X_{0}^{(j)}\}_{j=1}^{b}$를 취하고 batch mode에서 neural network $v_{\theta}$로 vector field를 추정하여 time $t=\tau\in (0,1)$까지의 ODE (Eq. 3)을 solve 함
- 이후 time $t=\tau$에서 모든 $j=1,..,b$에 대해 생성된 mel-spectrogram $e_{\theta}(X^{(j)}_{\tau},\tau)$의 approximiation을 계산하고, input speech와 prompt 간의 speaker similarity 측면에서 best approximiation을 choose 함
- i.g.) vocoder로 mel-estimation $e_{\theta}(X^{(j)}_{\tau},\tau)$를 raw audio로 변환하고, speaker verification network를 통해 speaker similarity를 구할 수 있음 - Optimal noisy sample $X^{(j*)}_{\tau}$가 선택되면, standard mode에서 initial condition $X_{\tau}=X^{(j*)}_{\tau}$ (batch size = $1$)을 사용하여 interval $[\tau,1]$에서 (Eq. 3)의 ODE를 continue solving 할 수 있음
- 해당 algorithm의 efficiency는 $\tau, b$에 따라 달라짐
- Batch mode에서는 neural network evaluation 수를 줄이기 위해 $\tau, b$를 작게 설정하는 것이 좋음
- Clean data estimation $e_{\theta}(X_{t},t)$의 경우, batch mode에서 다음의 formulation을 통해 하나의 neural network evaluation 만을 수행함:
(Eq. 5) $e_{\theta}(x,t)=(1-\sigma_{\min})x+(1-(1-\sigma_{\min})t)v_{\theta}(x,t)$ - 이때 (Eq. 1), (Eq. 2)는 optimally trained neural network $v_{\theta*}$에 대해:
(Eq. 6) $v_{\theta *}(x,t)=\mathbb{E}\left[\left. \frac{X_{1}-(1-\sigma_{\min})x}{1-(1-\sigma_{\min})t}\right| X_{t}=x \right]$ - 따라서:
(Eq. 7) $e_{\theta*}(x,t)=\mathbb{E}[X_{1}|X_{t}=x]$
- 결과적으로 PitchFlow는 (Eq. 5)를 사용하여 noisy $X_{t}=x$로부터 clean data $X_{1}$을 추정할 수 있음
- 특히 $\sigma_{\min}\approx 0$이므로 $e_{\theta}(x,t)\approx x+(1-t)v_{\theta}(x,t)$이므로 $e_{\theta}(x,t)$는 Euler method의 one step에서 initial condition $X_{t}=x$를 가지는 (Eq. 3)의 ODE solution으로 볼 수 있음
- 여기서 PitchFlow는 clean mel-spectrogram의 fair estimation $e_{\theta}(x,\tau)$를 $\tau=0.25$에서 early flow matching step으로 얻을 수 있음
- 즉, optimal prior sampel $X_{0}$를 choice 하여 generated speech와 prompt 간의 speaker similarity를 향상 가능

- Pitch Guidance
- Classifier guidance는 diffusion model에서 controllable generation을 지원함
- Pre-trained diffusion model의 controllability는 noisy sample $X_{t}$에서 target label을 예측하도록 training 된 classifier $p_{\phi_{t}}(y|X_{t})$를 통해 수행됨
- 이후 gradient $\nabla_{x}\log p_{\phi_{t}}(y|X_{t})$를 사용하여 diffusion backward pass를 class label $y$로 guide 함 - 이때 논문에서는 flow-based speech generation model에서 pitch control을 위해 해당 방식을 도입함
- 먼저 frame-level pitch를 log-scale로 frame 당 하나씩 50개의 bin으로 quantize 함
- Classifier $c_{\phi_{t}}(p|X_{t})$는 cross-entropy loss가 있는 noisy mel-spectrogram $X_{t}$에서 train 됨
- Ground-truth pitch value는 autocorrelation method를 사용하는 Praat partselmouth로 추출됨 - 이후 각 time step $t$에서 sampling 하는 동안 $X_{t}$는 target pitch contour $\hat{p}$와 match 할 probability를 계산하고, 다음의 ODE를 solve 함:
(Eq. 8) $\dot{X}_{t}=v_{\theta}(X_{t},t)+\alpha_{t}\nabla_{x}\log c_{\phi}(\hat{p}|X_{t})$
- $\alpha_{t}$ : weight
- 여기서 synthesized speech는 target과 close 한 pitch contour를 가지므로 fine-grained pitch manipulation을 지원 가능
- 추가적으로 해당 방식은 PitchFlow에 대한 voice conversion capability를 제공함:
- Source recording $S_{s}$에서 aligner를 통해 phoneme sequence $T_{s}$와 phoneme duration $D_{s}$를 얻음
- Source, target record $S_{s}, S_{t}$에서 pitch $P_{s}, P_{t}$를 추출하고 mean-variance statistics $(\mu_{s},\sigma^{2}_{s}), (\mu_{t},\sigma_{t}^{2})$를 계산함
- 그리고 source pitch를 $\hat{P}_{s}=\frac{P_{s}-\mu_{s}}{\sigma_{s}}\sigma_{t}+\mu_{t}$로 re-normalize 함 - 최종적으로 prompt $S_{t}$, duration $D_{s}$, target $\hat{P}_{s}$에 대한 pitch guidance를 사용하여 phoneme $T_{s}$에 대한 speech를 생성함
- BUT, 해당 pitch normalization은 pitch extraction algorithm의 inaccuracy와 short audio에서의 non-robustness로 인해 robust 하지 않음
- 따라서 논문은 추론 중에 optimal pitch shift를 find 하도록 앞선 speaker scoring과 유사한 방법을 도입함
- 먼저 target pitch value $\hat{P}_{s}^{(j)}=\{\hat{P}_{s}c_{j}\}_{j=1}^{7}$의 batch가 있다고 하자
- $c_{j}\in[0.85; 1,15]$ : step 0.05에 대한 coefficient - 그러면 (Eq. 8)의 ODE는 batch mode에서 time $t=\tau_{pg}$로 solve 되고 raw audio는 모든 $j$에 대해 mel-spectrogram $e_{\theta}(X^{(j)}_{\tau_{pg}},\tau_{pg})$의 approximation에서 합성됨
- 이때 speaker verification model에서 얻은 speaker similarity를 기반으로 further sampling을 수행하기 위해 하나의 target pitch variant $\hat{P}_{s}^{*}=\hat{P}_{s}^{(j*)}$만 select 됨
- 논문에서는 speaker similarity 개선을 위해 $\tau_{pg}=0.125$를 사용
- Pre-trained diffusion model의 controllability는 noisy sample $X_{t}$에서 target label을 예측하도록 training 된 classifier $p_{\phi_{t}}(y|X_{t})$를 통해 수행됨

4. Experiments
- Settings
- Results
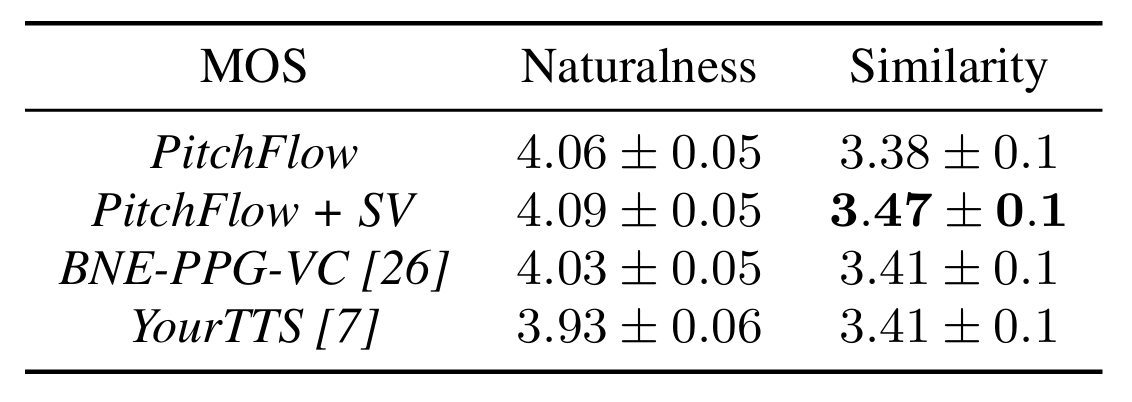
- Zero-Shot Voice Cloning with Speaker Scoring
- Voice Cloning 측면에서 PitchFlow의 성능이 가장 뛰어남

- Cosine Similarity, WER 측면에서도 우수한 성능을 달성

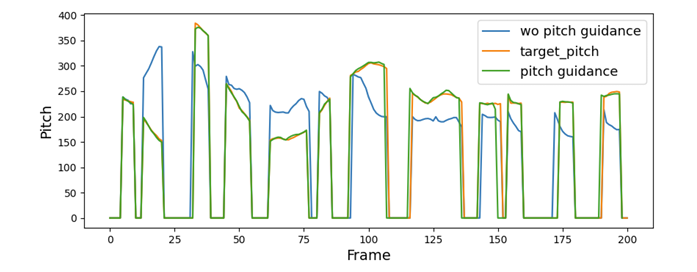
- Zero-Shot Voice Conversion with Pitch Guidance
- Voice Conversion에서도 PitchFlow는 높은 similairty를 보임
- Normalized Cross-Correlation 측면에서도 가장 우수한 성능을 달성함

- Pitch guidance를 통해 PitchFlow는 target pitch를 반영할 수 있음
반응형
'Paper > TTS' 카테고리의 다른 글
댓글