

티스토리 뷰
Paper/SVS
[Paper 리뷰] TokSing: Singing Voice Synthesis based on Discrete Tokens
feVeRin 2024. 7. 11. 09:09반응형
TokSing: Singing Voice Synthesis based on Discrete Tokens
- Self-supervised learning model에서 추출된 discrete token을 활용하여 singing voice synthesis의 성능을 향상할 수 있음
- TokSing
- Flexible token blending을 제공하는 token formulator를 갖춘 discrete-based singing voice synthesis model
- Melody signal을 discrete token과 integrate 하고 musical encoder에 melody enhancement strategy를 도입
- 논문 (INTERSPEECH 2024) : Paper Link
1. Introduction
- Singing Voice Synthesis (SVS)는 melody와 lyrics가 포함된 music score를 기반으로 vocal sound를 생성하는 것을 목표로 함
- DiffSinger와 같은 대부분의 SVS model은 acoustic model을 통해 score에서 mel-spectrogram을 생성한 다음, vocoder를 통해 waveform으로 변환하는 방식을 활용함
- 한편으로 discrete token은 speech understanding과 generation task에서 뛰어난 storage efficiency와 controllability를 보이고 있음
- 여기서 discrete token은 vector quantization이나 large pre-trained Self-Supervised Learning (SSL) model의 hidden embedding을 clustering 하여 얻어짐 - 해당 discrete token을 SVS task에 적용하기 위해서는 다음의 문제점을 해결해야 함
- 기존 SSL model에는 singing data가 부족하므로 SVS에 적합한 token을 생성하는 것이 어려움
- Melody를 위한 refined expression이 필요함
- 동일한 note의 fundamental frequency는 frame 별로 달라질 수 있고, high pitch, vibrato 등을 적절히 표현할 수 있어야 함
- BUT, melody의 acoustic detail은 discretization 과정에서 손실될 수 있음
-> 그래서 위 문제점들을 해결한 discrete token-based SVS model인 TokSing을 제안
- TokSing
- SVS task에 적합한 token을 얻기 위한 flexible formulation strategy를 설계
- 다양한 model과 layer에 걸쳐 token blending을 허용하는 token formulator를 도입 - Melody expression을 향상하기 위해 melody control signal을 incorporate
- 최종적으로 melody-oriented signal과 discrete token sequence를 활용하여 TokSing을 구성
- SVS task에 적합한 token을 얻기 위한 flexible formulation strategy를 설계
< Overall of TokSing >
- Singing에 적합한 token formulation을 구성하고 melody expression demand를 충족하는 discete token-based SVS model
- 결과적으로 기존 방식들보다 뛰어난 합성 성능을 달성
2. Method
- TokSing은 아래 component들로 구성됨
- Token formulator는 SSL model의 hidden embedding을 추출하고, clustering을 통해 token으로 quantize 함
- 이때 더 나은 prediction을 위해 enhancement strategy를 적용 - Musical encoder는 music score를 input으로 하여 target token과 melody signal을 예측함
- Vocoder는 token과 melody signal을 singing waveform으로 변환하는 역할
- Token formulator는 SSL model의 hidden embedding을 추출하고, clustering을 통해 token으로 quantize 함

- Token Formulation
- Discrete token을 formulate 하기 위해,
- 일반적으로 다음의 2가지 방법을 고려할 수 있음
- Vector Quantized-Variational AutoEncoder (VQ-VAE)를 사용하여 raw audio에서 discrete representation을 얻는 방법
- 대표적으로 SoundStream은 Residual Vector Quantizer (RVQ)와 codec decoder를 사용하여 multi-layer codec token을 reconstruct 함 - SSL model의 hidden representation을 clustering 하여 token을 quanitze 하는 방법
- 이때 pre-training과 사용되는 corpus가 token generation에 직접적인 영향을 미칠 수 있음
- Vector Quantized-Variational AutoEncoder (VQ-VAE)를 사용하여 raw audio에서 discrete representation을 얻는 방법
- BUT, 해당 token들은 intermediate representation 역할을 할 수 있지만, single token으로 전달되는 information은 제한적임
- 따라서 논문은 아래 그림과 같이 3가지 type으로 categorize 되는 blending token에 기반한 flexible token formulation을 활용
- Formulation 1 : 동일한 SSL model의 서로 다른 layer에서 token을 select 함
- Formulation 2 : 다양한 pre-training corpora와 task에 대한 서로 다른 SSL model의 token을 활용
- Formulation 3 : RVQ를 통해 SSL model의 hidden embedding에서 residual manner로 multi-layer token을 얻음
- 이때 EnCodec과 같은 pre-trained audio encoder를 활용 가능
- 결과적으로 TokSing은 위의 basic type들을 개별적으로 사용하거나 서로 결합하여 flexibility와 interpretability를 향상함
- 일반적으로 다음의 2가지 방법을 고려할 수 있음

- Musical Encoder
- Musical encoder는 music score에서 intermediate representation으로의 transition에 대한 acoustic modeling을 수행
- 이때 lyrics와 해당 pitch/duration information이 포함된 note squence를 input으로 하여 frame-level에서 intermediate representation을 output 함
- 특히 SVS의 경우, 주어진 musical score에 대한 specified timing variation을 따라야 하므로 더 정확한 duration prediction이 필요함 - 따라서 TokSing은 FastSpeech와 같이 explicit duration prediction module을 갖춘 non-autoregressive (NAR) model을 도입함
- 한편으로 앞선 discretization process는 singining의 pitch variation을 저하할 수 있음
- 이러한 손실을 compensate 하기 위해, fundamental frequency의 logarithm을 계산하여 token에 melody signal을 반영함
- 이때 input pitch를 encoding 하는 melody encoder와 pitch prediction을 수행하는 melody predictor를 사용
- 결과적으로 melody loss function $\mathcal{L}_{m}$은 raw audio에서 추출된 $m_{i}$와 예측된 $\hat{m}_{i}$ 간의 Euclidean distance로 정의됨:
(Eq. 1) $\mathcal{L}_{m} =\frac{1}{N}\sum_{i=1}^{N}|m_{i}-\hat{m}_{i}|$
- $N$ : frame 수 - Musical encoder에 의해 생성된 token은 특정 pitch-related detail을 encapsulate 할 수 있음
- 따라서 더 정확한 예측을 위해 score decoder의 output은 token predictor에 jointly pass 된 $\hat {m}_{i}$를 사용하여 enhance 됨
- 이때 token prediction loss $\mathcal{L}_{tok}$는 cross-entropy loss로 얻어짐:
(Eq. 2) $\mathcal{L}_{tok}=-\frac{1}{N}\sum_{i=1}^{N}\sum_{j=1}^{M}(d_{i}^{j}) \log (\hat{d}_{i}^{j})$
- $d_{i}^{j}$ : ground-truth token $\hat{d}_{i}^{j}$ : predicted token
- $M$ : token layer 수
- 이때 lyrics와 해당 pitch/duration information이 포함된 note squence를 input으로 하여 frame-level에서 intermediate representation을 output 함
- Vocoder
- Vocoder는 HiFi-GAN의 adversarial network를 기반으로 generator와 Multi-Period Discriminator (MPD), Multi-Scale Discriminator (MSD)로 구성됨
- 대신 TokSing은 mel-spectrogram을 discrete token으로 대체하여 사용함
- 이때 token은 extra embedding layer로 encoding 된 후, melody signal과 concatenate 되어 upsampling layer로 전달됨
3. Experiments
- Settings
- Dataset : OpenCPop, ACE-OpenCPop
- Comparisons : Xiaoicesing (mel-spectrogram), VISinger (latent variance)
- Results
- Comparison Experiments
- 전체적인 성능 측면에서 discrete token을 사용한 TokSing이 가장 우수한 성능을 달성함

- TokSing은 ground-truth와 가장 비슷한 audio segment를 생성할 수 있음

- 수렴 속도 측면에서도 TokSing은 mel-based model보다 빠르게 수렴함

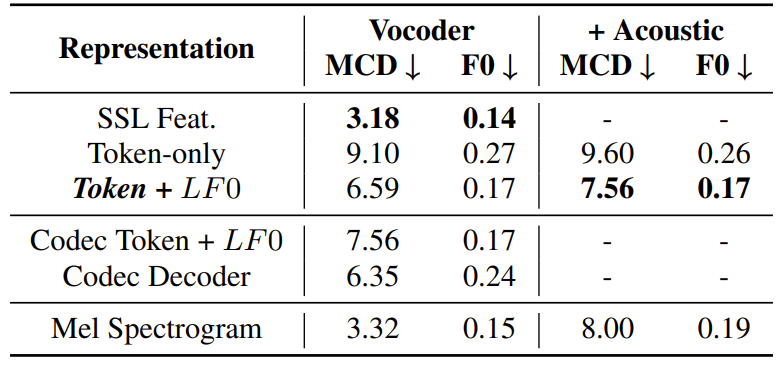
- Ablation of the Reconstruction in Vocoder
- Vocoder 측면에서 token만 사용하는 경우 성능 저하가 발생할 수 있음
- 결과적으로 melody signal을 추가적으로 사용하는 경우, discretization의 한계를 보완할 수 있음
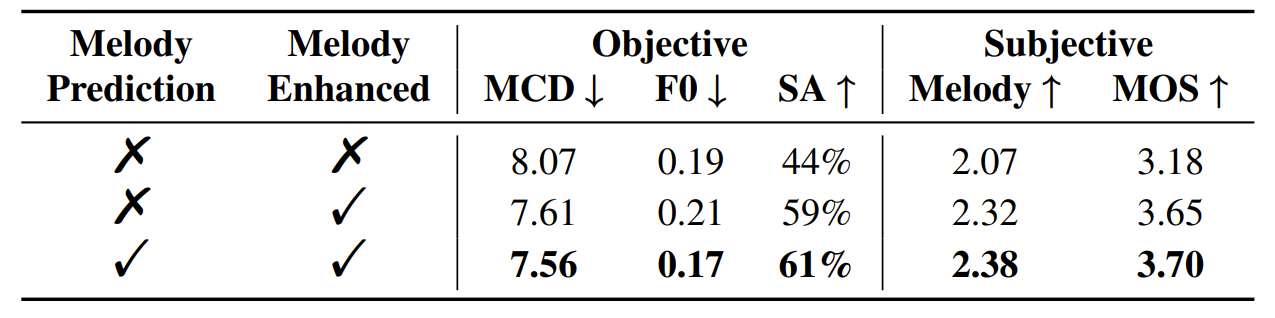
- Ablation of Musical Encoder
- Melody predictor, Melody enhancement를 모두 사용하는 경우 합성 성능을 크게 향상할 수 있음
- Ablation of Token Formulations
- 모든 multi-layer formulation은 성능 향상에 큰 역할을 함
- 특히 Formulation 3의 residual clustering은 더 많은 detail을 encoding 하여 vocoder의 성능을 향상할 수 있음
- BUT, Musical encoder의 prediction difficulty도 같이 증가시키므로 prediction accuracy가 저하될 수 있음

- Transfer Learning
- Transfer learning을 적용하는 경우에도 TokSing은 안정적인 성능을 유지함

반응형
'Paper > SVS' 카테고리의 다른 글
댓글