

티스토리 뷰
Paper/SVS
[Paper 리뷰] MakeSinger: A Semi-Supervised Training Method for Data-Efficient Singing Voice Synthesis via Classifier-free Diffusion Guidance
feVeRin 2024. 7. 15. 09:30반응형
MakeSinger: A Semi-Supervised Training Method for Data-Efficient Singing Voice Synthesis via Classifier-free Diffusion Guidance
- Singing voice synthesis를 위해 semi-supervised training을 활용할 수 있음
- MakeSinger
- Labeling에 관계없이 모든 speech, singing voice data에서 diffusion-based model을 training
- Dual guiding mechanism을 통해 maske input의 score를 추정하여 reverse diffusion step에 대한 text/pitch guidance를 제공
- 논문 (INTERSPEECH 2024) : Paper Link
1. Introduction
- Singing Voice Synthesis (SVS)는 일반적으로 text-to-speech (TTS)와 유사하게 2-stage pipeline으로 구성됨
- Acoustic model은 musical score로부터 mel-spectrogram과 같은 acoustic feature를 생성하고, vocoder는 해당 acoustic feature를 waveform으로 변환함
- BUT, 해당 model을 training 하기 위해서는 $(\text{text}, \text{pitch}, \text{audio})$ triplet이 precisely align 된 고품질 dataset이 필요함
- 이러한 dataset은 수집하기 어렵기 때문에 unlabeled data에서 추출된 pseudo label을 활용하는 semi-supervised approach를 고려해야 함
- 이를 위해 Harvest나 Parsel Mouth 등을 사용할 수 있지만, 여전히 $(\text{text}, \text{audio})$ pair가 필요하거나 singing voice에 적합한 auxiliary classifier가 요구됨
- 결과적으로 inaccurate labeling으로 인한 potential error propagation을 방지하기 위해 많은 양의 labeled data가 필요
- 한편으로 Guided-TTS와 같이 diffusion generative model에 text guidance를 제공하는 개별적인 phoneme classifier를 사용하면, unlabeled dataset에서도 효율적인 학습이 가능함
-> 그래서 labeling에 관계없이 모든 dataset을 활용할 수 있는 semi-supervised training 기반의 SVS model인 MakeSinger를 제안
- MakeSinger
- Classifier-free guidance를 채택하여 labeled/unlabeled data 모두에서 학습할 수 있는 joint model의 capability를 활용
- Reverse diffusion step에서 text와 pitch guidance 간의 balance를 adjust하는 dual guiding mechanism을 도입
< Overall of MakeSinger >
- Classifier-free guidance를 통해 data-efficiency를 향상한 SVS model
- 결과적으로 unlabeled, labeled data 모두를 사용하여 기존 보다 뛰어난 성능을 달성
2. Method
- MakeSinger는 base architecture로 score-based TTS model인 Grad-TTS를 기반으로 함
- Training process에서 MakeSinger는 labeling에 의존하지 않고 모든 audio에서 학습을 수행
- 이를 통해 paired data가 제한된 low-resource scenario에서도 robust 하게 활용할 수 있음 - 추론 시에는 적절한 pitch/text guidance를 제공하기 위해 dual guiding mechanisim을 적용
- Training process에서 MakeSinger는 labeling에 의존하지 않고 모든 audio에서 학습을 수행

- Architecture
- MakeSinger는 주어진 text, pitch, speaker에 대응하는 mel-spectrogram을 생성하도록 설계됨
- Labeled data를 통해 model을 학습하는 경우, mel-spectrogram과 함께 temporally aligned text와 pitch sequence를 input으로 사용
- Unlabeled data의 경우, $\langle \text{unknown} \rangle$ token sequence를 substituting label로 사용
- 이때 구조적으로 MakeSinger는 크게 encoder와 score estimator로 구성됨
- Encoder
- Encoder는 text, pitch, speaker information을 frame length mel-spectrogram sequence로 변환함
- 여기서 text encoder는 pre-net, 6개의 transformer, linear projection layr로 구성되고, 모든 feature sequence는 score estimator에 conditional information을 제공하기 위해 concatenate 됨 - Text와 pitch에서 추출된 feature sequence를 각각 $c,m$, $\langle \text{unknwon} \rangle$ text token에서 추출된 feature sequence를 $\emptyset_{c}$, $\langle \text{unknown} \rangle$ pitch token을 $\emptyset_{m}$이라고 하자
- 기존의 Grad-TTS와 달리 MakeSinger의 encoder는 prior noise distribution의 평균/분산을 추정하지 않고 conditional information encoding만 수행함
- 이는 strong piror information이 guiding process의 효과를 diminish 할 수 있기 때문
- Score Estimator
- U-Net architecture를 기반으로 score estimator $s_{\theta}$는 주어진 diffused mel-spectrogram $X_{t}$와 concatenated feature sequence로부터 score를 예측함
- $t$ : diffusion time step - Training 시에는 $[0,1]$에서 uniform 하게 $t$를 선택하고, forward diffusion process를 통해 ground-truth mel-spectrogram $X_{0}$를 diffused mel-spectrogram $X_{t}$로 변환함
- 추가적으로 score estimator를 training 하기 위해 $X_{t}$의 predicted score와 computed score 간의 $L2$ loss인 score-matching loss를 활용
- U-Net architecture를 기반으로 score estimator $s_{\theta}$는 주어진 diffused mel-spectrogram $X_{t}$와 concatenated feature sequence로부터 score를 예측함
- Encoder는 text, pitch, speaker information을 frame length mel-spectrogram sequence로 변환함
- Dual Guiding in Diffusion Generative Model
- 기존의 diffusion guiding mechanism은 Guided-TTS와 같이 충분한 labeled data를 요구하는 additional classifier를 사용함
- 논문에서는 low-resource 문제를 해결하기 위해 semi-supervised 방식으로 동작하는 classifier-free guiding을 채택함
- 이를 통해 각 reverse diffusion step에 guidiance를 제공하여 class-conditional generation을 향상 - SVS task를 위한 guiding shceme을 위해서는 underlying textual, pitch information을 효과적으로 manage 해야 함
- Naive approach로써 text, pitch에 대한 guidance를 modeling 할 수 있지만, 해당 방식은 text, pitch에 대한 개별적인 control을 방해하므로 flexibility가 저해됨
- 따라서 MakeSinger는 finer control을 위해 text, pitch에 대한 개별적인 guidance term을 활용하는 dual guidance approach를 채택함
- 해당 dual guidance를 formulate 하기 위해 diffused mel-spectrogram $X_{t}$, diffusion timestep $t$, conditional information $y$가 있다고 하자
- Score-based modeling에 따라 diffusion guiding formulation은:
(Eq. 1) $\nabla_{X_{t}}\log p_{t}(X_{t}|y)=\nabla_{X_{t}}\log p_{t}(X_{t})+\nabla_{X_{t}}\log p_{t}(y|X_{t})$ - $y$를 pitch condition $m$, text condition $c$로 split 한 다음, Bayes rule을 적용하면 두 label 모두에 대한 classifier-free guidance를 얻을 수 있음:
(Eq. 2) $\nabla_{X_{t}}\log p_{t}(m,c|X_{t})=\nabla_{X_{t}}\log p_{t}(X_{t}|m,c)-\nabla_{X_{t}}\log p_{t}(X_{t})$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,=(\nabla_{X_{t}}\log p_{t}(X_{t}|m,c)-\nabla_{X_{t}}\log p_{t}(X_{t}|m))+(\nabla_{X_{t}}\log p_{t}(X_{t}|m)-\nabla_{X_{t}}\log p_{t}(X_{t}))$ - 최종적으로 score는 scaling factor를 적용한 dual guiding을 통해 얻어짐:
(Eq. 3) $s_{t}=\nabla_{X_{t}} \log p_{t}(X_{t}|m,c)+w_{1}(\nabla_{X_{t}}\log p_{t}(X_{t}|m,c)-\nabla_{X_{t}}\log p_{t}(X_{t}|m))$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,+w_{2}(\nabla_{X_{t}}\log p_{t}(X_{t}|m)-\nabla_{X_{t}}\log p_{t}(X_{t}))$
- $s_{t}$ : reverse time process에 대한 time-dependent total score
- $w_{1}, w_{2}$ : text, pitch guidance에 대한 scaling factor - 비슷하게 conditional input에서 추정된 score에 대한 guidance는:
(Eq. 4) $s_{t}=\nabla_{X_{t}}\log p_{t}(X_{t}|m,c)+w_{1}(\nabla_{X_{t}}\log p_{t}(X_{t}|m,c)-\nabla_{X_{t}} \log p_{t}(X_{t}|c))$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,+w_{2}(\nabla_{X_{t}}\log p_{t}(X_{t}|c)-\nabla_{X_{t}}\log p_{t}(X_{t}))$
- Score-based modeling에 따라 diffusion guiding formulation은:
- 실질적인 구현을 위해 (Eq. 3)은 다음과 같이 express 됨:
(Eq. 5) $s_{t}=s_{\theta}(X_{t},m,c,t)+\alpha_{t}^{1}w_{1}(s_{\theta}(X_{t},m,c,t)-s_{\theta}(X_{t},m,\emptyset_{c},t))$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,+\alpha_{t}^{2}w_{2}(s_{\theta}(X_{t},m,\emptyset_{c},t)-s_{\theta}(X_{t},\emptyset_{m},\emptyset_{c},t))$
- $\alpha_{t}^{1}, \alpha_{t}^{2}$ : norm-based guidance의 normalizing factor - 결과적으로 MakeSinger는 conditional, unconditional data를 모두 사용하여 single joint model을 training 해 모든 score term을 추정할 수 있음
- 이때 original feature sequence를 pitch-only, unlabeled data sequence에 mask 하여 각 guidance를 추정함
- 추가적으로 norm-based guidance를 적용해 모든 diffusion timestep $t$에서 joint model score의 norm에 비례하여 guiding gradient의 각 norm을 scaling 하는 방식으로 control을 최적화함
- 논문에서는 low-resource 문제를 해결하기 위해 semi-supervised 방식으로 동작하는 classifier-free guiding을 채택함
3. Experiments
- Settings
- Dataset : Korean singing voice dataset
- Comparisons : MLP-Singer, VISinger
- Results
- 전체적인 성능 측면에서 semi-supervised learning을 사용한 MakeSinger가 가장 뛰어난 성능을 달성함

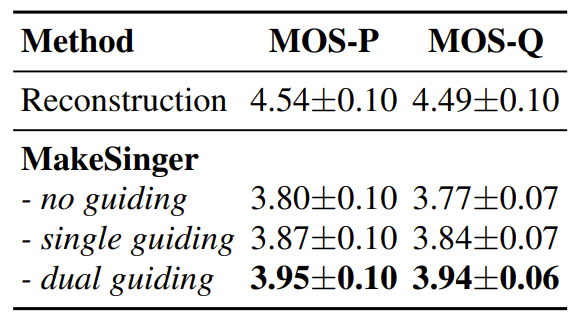
- Ablation Study
- Ablation study 측면에서 dual guiding, single guiding, no guiding을 각각 비교해 보면 논문에서 사용된 dual guiding이 가장 좋은 성능을 보임
- 이때 single guiding은 다음과 같이 정의됨:
(Eq. 6) $s_{t}=s_{\theta}(X_{t},m,c,t)+\alpha_{t}w(s_{\theta}(X_{t},m,c,t)-s_{\theta}(X_{t}, \emptyset_{m}\emptyset_{c},t))$
반응형
'Paper > SVS' 카테고리의 다른 글
댓글