

티스토리 뷰
Paper/SVS
[Paper 리뷰] Prompt-Singer: Controllable Singing-Voice-Synthesis with Natural Language Prompt
feVeRin 2024. 6. 22. 12:44반응형
Prompt-Singer: Controllable Singing-Voice-Synthesis with Natural Language Prompt
- Singing Voice Synthesis는 여전히 style attribute를 explicitly control 하는 것이 어려움
- Prompt-Singer
- Gender, vocal range, volume 등을 natural language prompt로 control하는 singing voice synthesis 모델
- Multi-scale hierarchy를 가지는 decoder-only transformer를 기반으로 melodic accuracy를 유지하면서 text-conditioned vocal range control이 가능한 range-melody decoupled pitch representation을 설계
- 논문 (NAACL 2024) : Paper Link
1. Introduction
- Singing Voice Synthesis (SVS)는 주어진 lyrics와 pitch note를 기반으로 고품질의 singing voice를 생성하는 것을 목표로 함
- 이때 자연스러운 합성을 위해서는 speaker timbre, vocal range, energy 등의 style attribute를 반영할 수 있어야 함
- 이를 위해 대부분의 경우 reference speech/singing segment로부터 style attribute를 추출하는 방식을 사용함
- BUT, 해당 방식은 user-friendly하지 않고 acoustic attribute를 explicitly control 하는 것에 한계가 있음 - 한편으로 singing voice의 style controllability를 향상하기 위해 natural language instruction을 사용하는 방법을 고려할 수 있음
- 해당 style prompt를 통해 specific attribute를 정확하게 control할 수 있고, user interaction을 simplify 할 수 있기 때문 - BUT, SVS task에 natural language style prompt를 도입하기 위해서는 다음의 문제를 해결해야 함
- Decoupling Melody and Vocal Range
- 실생활에서는 서로 다른 speaker가 서로 다른 vocal range에서 동일한 노래를 부를 수 있음
- BUT, SVS data의 pitch annotation은 특정한 vocal range의 특정 singer와 coupling되어 있으므로, 주어진 pitch에 맞는 melody와 vocal range, timbre를 align 하는 것이 어려움 - Textual Representation
- Sining style description에 대응하는 text representation이 존재하지 않고, prompt representation에 대한 optimal choice 역시 알려지지 않음 - Data Scarcity
- 사용할 수 있는 SVS dataset은 크기가 매우 작으므로, 모델의 diversity가 제한되고 natural language description과 data distribution 간의 correlation을 학습하는 것이 어려울 수 있음
- Decoupling Melody and Vocal Range
-> 그래서 위 문제를 해결하면서, natural language prompt를 통해 style control이 가능한 SVS 모델인 Prompt-Singer를 제안
- Prompt-Singer
- AudioLM, VALL-E 등의 spoken LLM의 성공에서 영감을 받아 unit vocoder와 discrete codec unit의 conditional generation을 위한 multi-scale hierarchy를 가진 decoder-only transformer를 도입
- 추가적으로 앞서 언급된 문제들을 해결하기 위해,
- Vocal range factor와 speaker-independent melody sequence에 대한 decoupled pitch representation을 설계
- 이를 통해 melodic accuracy를 유지하면서 voice range controlling이 가능 - Prompt encoding을 위한 text encoder를 조사하고 최적의 text representation을 얻기 위해 encoder를 fine-tuning
- Data scarcity 문제를 해결하기 위해 speech data를 추가로 도입
- Vocal range factor와 speaker-independent melody sequence에 대한 decoupled pitch representation을 설계
< Overall of Prompt-Singer >
- Gender, vocal range, volume 등을 control하는 natural language prompt를 갖춘 SVS 모델
- Melody와 voice range를 decouple하는 pitch representation을 설계하여 melodic accuracy를 유지하면서 prompt-conditioned voice range manipulation을 지원
- 다양한 text encoder를 fine-tuning하여 prompt에 대한 최적의 text representation을 얻음
- 결과적으로 low-resource 환경에서도 기존 보다 뛰어난 controllalbility와 합성 성능을 달성
2. Prompt Generation and Fetching
- Prompt-Singer는 natural language prompt를 사용하여 SVS task에서 gender, vocal range, volume 등을 control 하는 것을 목표로 함
- BUT, 해당 task에 적합한 dataset이 존재하지 않으므로, 논문은 일반적인 SVS dataset을 기반으로 각 data item에 대한 prompt sentence를 생성하는 방식을 도입함
- 이때 manual annotation은 비용이 많이 소모되므로, LLM인 GPT 3.5-Turbo를 활용하여 다음의 3단계로 prompt sentence를 생성
- Attribute categorization
- Keyword and sentence template generation
- Prompt sentence assembling
- 먼저, 아래 그림의 (a)와 같이 다양한 attribute에 따라 audio를 categorize함
- Gender category는 male/female를 pre-annotate 하여 사용하고, volume은 low, medium, high에 대한 3가지 category를 구성하여 각각 $[0.02, 0.04], [0.07, 0.10], [0.16,0.20]$의 amplitude RMS range를 나타냄
- Vocal range는 high, low의 2가지 category를 설정한 다음, voiced part의 average $F0$를 기준으로 classify 함
- 이때 threshold는 남자 125Hz, 여자 305Hz
- Categorization 이후, (b)와 같이 LLM을 사용하여 각 category에 대한 4~7개의 synonyms set을 keyword로써 생성함
- 이때 LLM을 사용하여 각 single attribute에 대한 prompt sentence template를 생성하고, 추가적으로 specific category를 targeting 하는 소수의 prompt sentence도 생성함
- 각 template은 keyword로 replace 할 placeholder를 포함 - 결과적으로 manual selection 이후 각 attribute에 대해 50개의 setence template를 얻고, LLM을 prompting 하여 각 single-attribute template를 combine 해 multi-attribute template를 얻음
- 이때 LLM을 사용하여 각 single attribute에 대한 prompt sentence template를 생성하고, 추가적으로 specific category를 targeting 하는 소수의 prompt sentence도 생성함
- Prompt sentence assembling은 (c)와 같이 training 중에 dynamic 하게 발생함
- 먼저 prompt sentence를 fetching 하기 위해, data item에 대한 pre-annotated label을 얻은 다음
- 다양한 수의 attribute에 모델이 adapt 되도록 probability $p_{1}, p_{2}$에 따라 label이 randomly drop 됨
- 이후 pre-generated set에서 keyword와 sentence template를 radomly fetch 하고, placeholder를 keyword로 대체하여 final prompt sentence를 얻음

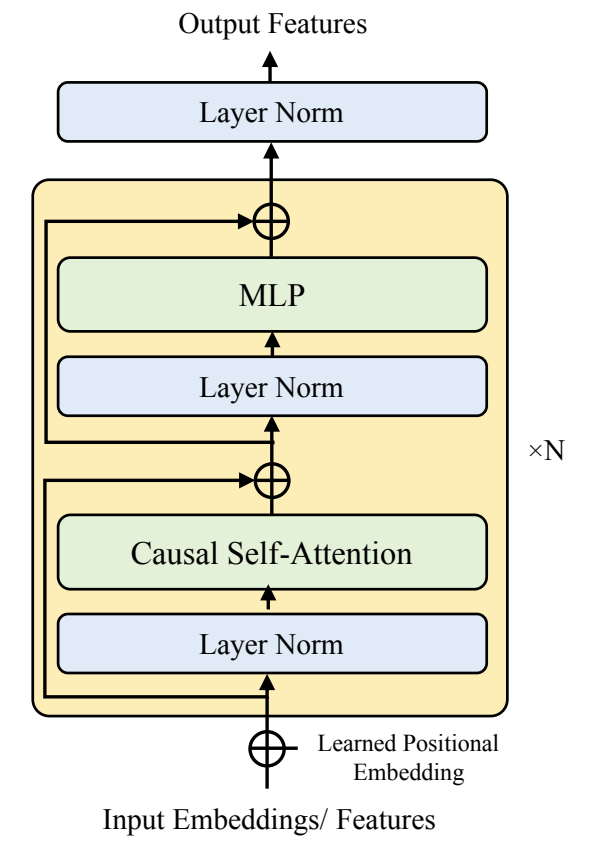
3. Prompt-Singer
- Prompt-Singer는 아래 그림과 같이 크게 2개의 sub-module로 구성됨
- Multi-scale transformer : natural language prompt, lyrics (duration 포함), pitch information의 input으로 condition 되어 discrete acoustic unit을 생성하는 역할
- Unit vocoder : 생성된 acoustic unit을 audio waveform으로 mapping 하는 역할

- Voice Representation
- Transformer의 prediction target으로 사용되는 acoustic unit은 encoder-decoder architecture와 Residual Vector Quantization (RVQ)를 갖춘 neural codec인 SoundStream을 통해 생성됨
- 해당 codec은 convolution encoder와 RVQ를 사용하여 audio의 discrete compressed representation을 생성할 수 있고, 해당 representation은 decoder로 waveform을 reconstruction 하는 데 사용됨
- 이때 acoustic unit sequence는 $\mathbf{a}=[a_{1}^{1},a_{1}^{2},...,a_{1}^{C},a_{2}^{1},...,a_{T}^{C}]$로 represent 됨
- $a_{i}^{j}\in\{0,1,...,K_{a}-1\}, \,\, \forall 1\leq i\leq T, 1\leq j\leq C$
- $T,C, K_{a}$ : 각각 frame 수, residual codebook 수, codebook size
- Textual Representation
- Prompt-Singer의 textual input은 lyrics와 style을 control 하는 natural language prompt의 2가지 component로 구성됨
- Lyrics의 경우, text를 phonemize 한 다음 dataset annotation이나 Forced-Alignment tool을 사용하여 해당하는 phoneme-level duration을 얻음
- 이후 duration을 preset frame rate를 기반으로 frame-level로 변환하고, phoneme을 duplicate 하여 해당 duration으로 phoneme sequence의 length를 regulate 함
- 이때 phoneme의 frame rate를 acoustic unit과 동일하게 설정하여 legnth alignment를 쉽게 학습하도록 함 - 최종적으로 regulated phoneme sequence는 look-up-table (LUT)에 embedding 되어 transformer로 전달됨
- 이후 duration을 preset frame rate를 기반으로 frame-level로 변환하고, phoneme을 duplicate 하여 해당 duration으로 phoneme sequence의 length를 regulate 함
- Natural language prompt는 parameter-frozen text encoder를 사용하여 semantic representation을 추출한 다음, transformer에 맞게 dimension을 mapping 하는 linear layer를 적용함
- 이때 style controlling에 대한 text representation의 영향력을 알아보기 위해, 다음의 3가지 encoder를 비교함
- BERT : masked language modeling, next sentence prediction으로 train 된 self-supervised text encoder
- FLAN-T5 : insturction으로 fine-tuning 된 unified text-to-text transformer encoder
- CLAP : natural language, audio에 대한 contrastive pretraining을 활용한 text encoder - 추가적으로 prompt와 해당 label을 사용하여 BERT-large와 FLAN-T5 Large를 fine-tuning 함
- Multi-label prediction으로 BERT를 fine-tuning 하고, FLAN-T5가 text-to-text 방식으로 prompt에 대응하는 label sequence를 예측하도록 함
- 이때 style controlling에 대한 text representation의 영향력을 알아보기 위해, 다음의 3가지 encoder를 비교함
- Lyrics의 경우, text를 phonemize 한 다음 dataset annotation이나 Forced-Alignment tool을 사용하여 해당하는 phoneme-level duration을 얻음
- Decoupled Pitch Representation
- Temperament theory에 따르면, musical interval에 대한 human perception은 frequency의 logarithmic distance에 해당함
- 따라서 logarithmic domain에서 offset을 추가하는 것과 동일하게, singing의 voiced part에 fundamental frequency $F0$를 multiply 하면 melody의 변경 없이 vocal range만 adjust 할 수 있음
- 이를 기반으로 논문은 $F0$를 다음과 같이 2가지 component로 decompose 함
- $\bar{f}_{0}$ : $F0$의 voiced part의 average value로써 vocal range를 의미
- $\tilde{\mathbf{f}_{0}} = [\tilde{f}_{0}^{1},\tilde{f}_{0}^{2},...,\tilde{f}_{0}^{T}]$ : vocal-range-invariant melody information을 의미
- 이때 original $F0$ sequence의 voiced part가 specific mean value (논문에서는 230Hz)를 가지도록 rescale 함
- 위의 representation을 통해 information bottleneck을 형성하고, 모델이 rescaled $F0$ sequence와 average $F0$ factor에서 melodic, vocal range information을 추출하도록 함
- 실제로는 $\tilde{\mathbf{f}_{0}},\bar{f}_{0}$를 integer로 반올림하고, LUT를 사용하여 transformer backbone 이전에 embed 함
- 이때 $\tilde{\mathbf{f}_{0}}, \bar{f}_{0}$는 동일한 embedding space를 share 함
- Alleviating Data Scarcity
- Speech와 singing은 다른 형태의 human voice이므로, style characteristic과 distribution 측면에서 commonality를 share 한다고 볼 수 있음
- 따라서 논문은 해당 직관을 기반으로 data scarcity를 alleviate 하기 위해 text-to-speech (TTS) data를 prompt SVS task에 incorporate 함
- 구체적으로 text를 phonemize 하고 prompt를 생성한 다음, off-the-shelft tool을 통해 speech에서 pitch를 추출하여 SVS data와 동일한 format의 data item을 얻음
- 이를 기반으로 low-resource scenario에서 singing data를 speech data로 대체할 수 있도록 함
- Multi-Scale Transformer Architecture
- End-to-End differentiable multi-scale transformer architecture는 audio 합성에서 뛰어난 relationship modeling 성능을 달성했고, sub-quadratic self-attention을 기반으로 long-sequence를 효과적으로 생성 가능함
- 이를 위해 논문에서는 Uni-Audio의 multi-scale transformer를 backbone으로 하여long sequence modeling을 위한 hierarchical structure를 갖춘 decoder-only transformer를 설계함
- 해당 module은 intermediate output인 vocal range factor와 함께 language prompt, lyrics, duration, melody representation으로 condition 되어 singing voice의 discrete acoustic unit을 생성함
- Training 중에 conditional input과 target sequence는 single sequence로 concatenate 되어 transformer에 전달되고, 해당 transformer는 cross-entropy loss와 next-token-prediction을 사용하여 correlation을 모델링함
- 추론 시에는 prefix input sequence에 따라 autoregressively condition 된 range factor와 acoustic unit을 예측함:
(Eq. 1) $P_{cond}(\mathbf{a})=P_{cond}(\bar{f}_{0})\cdot \prod_{t=1}^{T}\prod_{c=1}^{C}P_{AR}(\mathbf{a}^{c}_{t})$
(Eq. 2) $P_{cond}(*)=p\left(*|\mathbf{E}_{\mathcal{P}}(\mathcal{P}),L,\mathbf{d},\tilde{\mathbf{f}_{0}};\theta_{AR}\right)$
(Eq. 3) $P_{AR}(\mathbf{a}_{t}^{c})=p\left(\mathbf{a}_{t}^{c}|\mathbf{a}_{<t},\mathbf{a}_{t}^{<c},\mathbf{E}_{\mathcal{P}}(\mathcal{P}),L,\mathbf{d},\tilde{\mathbf{f}_{0}},\bar{f}_{0};\theta_{AR} \right)$
- $\mathbf{a},\mathbf{E}_{\mathcal{P}}, \mathcal{P}, L,\mathbf{d},\tilde{\mathbf{f}_{0}}, \bar{f}_{0}, \theta_{AR}$ : 각각 acoustic unit, prompt encoder, prompt, lyrics, duration, melody representation, vocal-range factor, model parameter
- $t, c$ : 각각 acoustic unit의 temporal index, codebook index
- 이때 vocal range factor를 예측하는 transformer는 다음과 같이 formulate 됨:
(Eq. 4) $P_{cond}(\bar{f}_{0})=p\left(\bar{f}_{0}|\mathbf{E}_{\mathcal{P}}(\mathcal{P}), L,\mathbf{d},\tilde{\mathbf{f}_{0}};\theta_{AR}\right)$
- 여기서 average $F0$ value는 lyrics, duration, melody와 independent 하다고 가정하므로, (Eq. 4)는 natural language prompt를 통해 vocal range를 control 하는 model capability를 의미함
- 추가적으로 예측된 vocal range information은 singing acoustic unit generation을 위한 condition으로 사용됨 - 구조적으로 hierarchical multi-scale transformer는 global, local decoder-only transformer로 구성됨
- Temporal position $t$의 경우, 서로 다른 codebook의 acoustic unit embedding $z_{t}^{1:n_{q}}$가 concatenate 된 다음 inter-frame correlation modeling을 위해 global transformer에 전달됨
- Output hidden feature $h_{t}$는 $h_{1:t-1}$을 condition으로 하여 autoregressive 하게 생성됨
- 이후 해당 hidden feature는 embedding의 original shape에 따라 split 되고 linear layer로 proejct 된 다음, frame-level context로 local transformer의 input embedding에 추가됨
- 최종적으로 local transformer는 frame 내의 다양한 codebook의 acoustic unit을 autoregressive 하게 예측함
- Non-acoustic modality의 경우, 각 item은 해당 modeling mechanism에 맞게 $n_{q}$번 repeat 됨
- $n_{q}$ : codebook size
- 이를 위해 논문에서는 Uni-Audio의 multi-scale transformer를 backbone으로 하여long sequence modeling을 위한 hierarchical structure를 갖춘 decoder-only transformer를 설계함
- Unit Vocoder
- Acoustic unit generation이 완료되면, 생성된 unit을 high-fidelity audio waveform에 mapping 해야 함
- 이때 codec의 compressive nature로 인해 decoder를 통해 단순히 limited codebook의 acoustic unit을 audio로 reconstruction 하면 perceptual quality가 저하될 수 있음
- 따라서 논문은 codec decoder 대신, GAN-based unit vocoder를 채택하여 richer detail의 high-fidelity audio를 생성함
- 구체적으로, BigVGAN vocoder를 기반으로 discrete unit을 embed 하는 LUT set와 transposed convolution으로 구성된 generator를 사용
- 여기서 multi-period discriminator (MPD)와 multi-resolution discriminator (MRD)는 adversarial training을 위해 사용됨
4. Experiments
- Settings
- Dataset
- SVS : M4Singer, OpenCPop, OpenSinger, PopCS
- TTS : AISHELL-3, Biaobei, THCHS-30, DidiSpeech - Comparisons : FFT-Singer, DiffSinger
- Results
- Evaluation on Text Representations
- Pre-trained Text Encoder의 경우, simpler distribution을 가지는 label과 text representation을 align 하는 것이 singing style에 대한 correlation을 학습하는데 유용함
- 결과적으로 FLAN-T5를 text encoder로 사용했을 때 Prompt-Singer는 가장 우수한 성능을 달성함

- Evaluation on Data Scarcity Alleviation
- Low-resource scenario에서 SVS data의 양이 줄어들수록 모델의 성능이 급격히 저하됨
- 즉, speech data를 도입하면 controllable SVS 성능을 향상할 수 있지만, 품질과 melody accuracy를 보장하려면 충분한 양의 singing data가 필요함

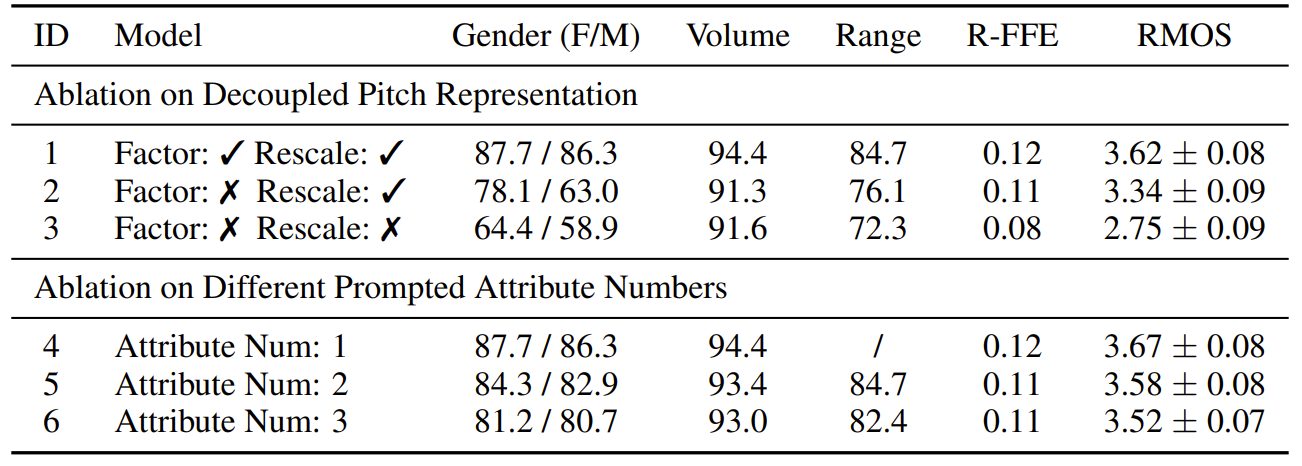
- Ablation Study
- Pitch representation 측면에서 vocal range factor와 $F0$에 대한 rescaling을 제거하는 경우, 성능 저하가 발생함
- Multi-attribute prompt 측면에서 attribute 수가 늘어날수록 약간의 RMOS의 저하가 발생했음
- BUT, Prompt-Singer는 single/multiple attribute prompt 모두에서 여전히 뛰어난 합성 성능을 보임
반응형
'Paper > SVS' 카테고리의 다른 글
댓글