

티스토리 뷰
Paper/TTS
[Paper 리뷰] AutoTTS: End-to-End Text-to-Speech Synthesis through Differentiable Duration Modeling
feVeRin 2024. 5. 30. 13:54반응형
AutoTTS: End-to-End Text-to-Speech through Differentiable Duration Modeling
- Text-to-Speech 모델은 일반적으로 external aligner가 필요하고, decoder와 jointly train 되지 않으므로 최적화의 한계가 있음
- AutoTTS
- Input, output sequence 간의 monotonic alignment를 학습하기 위해 differentiable duration method를 도입
- Expectation에서 stochastic process를 최적화하는 soft-duration mechanism을 기반으로 하여 direct text-to-waveform synthesis 모델을 구축
- 추가적으로 adversarial training과 ground-truth duration과의 matching을 통해 고품질 합성을 지원
- 논문 (ICASSP 2023) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 주어진 text를 음성으로 변환하는 것을 목표로 함
- 특히 soft attention mechanism을 활용하여 encoder-decoder model을 학습하는 autoregressive model은 우수한 합성 성능을 보이고 있음
- BUT, autoregressive model은 word repetition/skipping 같은 robustness 문제와 느린 추론 속도의 한계가 있음
- 따라서, TTS 추론 속도 향상을 위해 parallel, non-autoregressive model들이 제안됨 - BUT, non-autoregressive model에서 alignment는 다음의 기준들을 만족해야 하기 때문에 text와 mel-spectrogram 간의 alignment를 학습하는 것이 어려움:
- 각 character/phoneme token은 적어도 하나의 spectrogram frame과 align되어야 함
- Aligned spectrogram frame은 consecutive해야 함
- Alignment는 monotonic해야 함
- 이때 FastSpeech, FastSpeech2와 같은 일반적인 non-autoregressive model들은 alignment 문제를 해결하기 위해, autoregressive teacher model과 forced aligner를 활용함
- 즉, 해당 non-autoregressive model들은 teacher나 external aligner에 의존적이라는 한계가 있음 - 한편으로 기존의 TTS 모델은 주로 two-stage 방식으로 구성되고, acoustic model과 vocoder 간의 distribution mismatch로 인해 artifact가 발생함
- 따라서 two-stage 방식 대신 end-to-end TTS 모델을 채택하여 intermediate step에서 error propagation을 줄이고 pipeline의 complexity를 줄여야 함
- 특히 soft attention mechanism을 활용하여 encoder-decoder model을 학습하는 autoregressive model은 우수한 합성 성능을 보이고 있음
-> 그래서 data로부터 alignment를 직접적으로 학습하는 end-to-end TTS 모델인 AutoTTS를 제안
- AutoTTS
- Differentiable duration modeling을 통해 전체 network에 대한 gradient back-propagation을 허용
- 결과적으로 external aligner 없이 phoneme sequence와 audio waveform 간의 alignmet를 학습 가능 - End-to-End 방식으로 adversarial training을 적용하여 perceptual quality를 향상
- Differentiable duration modeling을 통해 전체 network에 대한 gradient back-propagation을 허용
< Overall of AutoTTS >
- Input, output sequence 간의 monotonic alignment를 학습하기 위해 differentiable duration method를 도입
- End-to-End 방식으로 모델을 training하고 ground-truth duration과 matching 시킴
- 결과적으로 기존보다 우수한 TTS 성능을 달성
2. Method
- AutoTTS는 phoneme sequence에서 raw audio waveform을 예측하는 것을 목표로 함
- 구조적으로 AutoTTS는 encoder, aligner, decoder로 구성됨
- Encoder는 phoneme sequence를 hidden embedding에 mapping 하는 역할
- Aligner는 해당 hidden embedding을 audio output과 align되면서 lower resolution을 가지는 embedding에 mapping 함
- Decoder는 aligner의 output embedding을 raw audio waveform으로 upsampling 하는 역할
- AutoTTS에서는 supervised duration signal을 사용하지 않고 back-propagation-based training을 수행함
- 구조적으로 AutoTTS는 encoder, aligner, decoder로 구성됨

- Duration Modeling
- Phoneme sequence와 mel-spectrogram output 간의 length mismatch를 해결하기 위해 FastSpeech의 length regulator를 활용할 수 있음
- 먼저 $N$개의 phoneme에 대한 sequence $x=\{x_{1},...,x_{N}\}$이 주어지면, encoder는 hidden state sequence $H=\{\mathbf{h}_{1},...,\mathbf{h}_{N}\}$을 output 함
- $i=1,...,N$에 대해 $\mathbf{h}_{i}\in\mathbb{R}^{D}$ - 이후 decoder는 주어진 hidden state sequence에 대한 mel-spectrogram sequence를 output 함
- 이때, phoneme sequence의 length는 mel-spectrogram length 보다 훨씬 작으므로, length regulator를 도입하여 해당하는 duration에 따라 각 hidden state를 upsampling 함
- 여기서 duration은 phoneme에 해당하는 mel-spectrogram frame 수로 정의됨 - 일반적으로 TTS 모델은 training 중에 external aligner나 teacher-student distillation을 사용해 duration을 추출하지만, 해당 length regulator는 non-differentiable function이므로 gradient-based method를 통해 최적화할 수 없음
- 먼저 $N$개의 phoneme에 대한 sequence $x=\{x_{1},...,x_{N}\}$이 주어지면, encoder는 hidden state sequence $H=\{\mathbf{h}_{1},...,\mathbf{h}_{N}\}$을 output 함
- 따라서 AutoTTS는 end-to-end training을 가능하게 하는 stochastic duration model을 도입함
- 먼저 duration을 stochastic process로 formulate 하기 위해, phoneme duration이 $[0,M]$ range의 discrete integer라고 가정함
- 그리고 $w_{i}$를 $i$-th phoneme의 duration을 나타내는 random variable이라고 하고, $\mathbf{p}_{i}\in[0,1]^{M}$을 $w_{i}$를 characterize 하는 distribution의 parameter를 포함하는 vector (i.e., $w_{i}\sim P(w_{i}|\mathbf{p}_{i})$)라고 하자
- 그러면 $i$-th phoneme에 대해 duration이 $m\in\{1,...,M\}$일 probability는:
(Eq. 1) $l_{i,m}=p_{i,m}\prod_{k=1}^{m-1}(1-p_{i,k})=p_{i,m}\mathrm{cumprod}(1-\mathbf{p}_{i,:})_{m-1}$
- $\mathrm{cumprod}(v)=\left[v_{1},v_{1}v_{2},...,\prod_{i=1}^{|v|}v_{i}\right]$ : cumulative product operation
- $l$ : length probability - 이때 parameter $\mathbf{p}_{i}$가 주어지면, $m=1$부터 시작하여 $\mathrm{Bernoulli}(p_{i,m})$ distribution의 sequence를 따라 duration을 sampling 할 수 있음
- 결과적으로 어떤 $m$에 대해 outcome이 1이면 stop 하고, 해당 duration을 $m$으로 설정함
- $M$ trial 이후에도 outcome이 없는 경우, duration은 0으로 설정되고 다음의 probability를 가짐:
$l_{i,0}=\prod_{k=1}^{M}(1-p_{i,k})=\mathrm{cumprod}(1-\mathbf{p}_{i,:})_{M}$
- 특히, 모든 $i\in\{1,...,N\}$에 대해 $\sum_{m=0}^{M}l_{i,m}=1$이므로, length probability는 valid distribution을 가짐
- 그러면 $i$-th phoneme에 대해 duration이 $m\in\{1,...,M\}$일 probability는:
- 한편으로 phoneme duration은 각 individual phoneme의 duration에 걸쳐 summation 될 수 있음
- 먼저 $q_{i,j}$를 first $i$ phoneme의 sequence가 $j\in\{0,...,M\}$의 duration을 가질 probability를 나타낸다고 하자
- 이때 first phoneme의 경우, 이는 legnth probability와 동일함 (i.e., $q_{1,:}=l_{1,:}$)
- $i>1$인 경우, $q_{i,:}$는 $i$-th phoneme의 모든 possible duration을 고려하여 다음의 (Eq. 2)와 같이 $q_{i-1,:}, l_{i,:}$로 recursively formualte 됨:
(Eq. 2) $q_{i,j}=\sum_{m=0}^{j}q_{i-1,m}l_{i,j-m}$
- Phoneme sequence의 duration probability를 구한 다음, attention이나 alignment probability를 계산해야 함
- $s_{i,j}$를 $j$-th output frame이 $i$-th input token과 align 될 probability를 나타낸다고 하자
- 그러면 $\mathbf{h}_{i,:}$와 $y_{j,:}$ 간의 alignment는 first $i$ phoneme의 total duration이 $j$보다 크거나 같을 때 수행됨
- 따라서, first phoneme에서 $s_{1,j}=\sum_{m=j}^{M}l_{i,m}$으로 계산할 수 있고, $i>1$인 경우 $s_{i,:}$는 $q_{i-1,:}, l_{i,:}$에 대해:
(Eq. 3) $s_{i,j}=\sum_{m=0}^{j-1}q_{i-1,m}\sum_{k=j-m}^{M}l_{i,k}=\sum_{m=0}^{j-1}q_{i-1,m}\mathrm{cumsum}^{*}(l_{i,:})_{j-m}$
- $\mathrm{cumsum}^{*}(v)=\left[\sum_{i=1}^{|v|}v_{i},\sum_{i=2}^{|v|}v_{i},...,v_{|v|}\right]$ : reverse cumulative sum operation
- 결과적으로 AutoTTS는 $i$-th phoneme이 $j$-th output frame을 align 할 수 있는 모든 possibility를 고려함
- 즉, 아래 그림과 같이 length probability $l$에 대한 attention probability $s$를 얻을 수 있음
- 앞선 cumulative summation을 통해 duration을 모델링함으로써, monotonic alignment를 implicitly enforce 함 - Attention probability $s$를 계산한 다음, $j=\{1,...,M\}$에 대해 hidden state를 expected output $\mathbb{E}[y_{j,:}]=\sum_{i=1}^{N}s_{i,j}\mathbf{h}_{i,:}$로 upsampling 할 수 있음
- 즉, 아래 그림과 같이 length probability $l$에 대한 attention probability $s$를 얻을 수 있음

- Training Procedure
- AutoTTS는 adversarial training을 통해 학습됨
- Discriminator $D$는 real waveform $z$와 network $G(x)$에서 생성된 waveform을 distinguish 하는 데 사용됨
- 이때 AutoTTS의 loss function은:
(Eq. 4) $\mathcal{L}=\mathcal{L}_{\text{adv-G}}+\lambda_{\text{length}}\mathcal{L}_{\text{length}}+\lambda_{\text{duration}}\mathcal{L}_{\text{duration}}+\lambda_{\text{recon}}\mathcal{L}_{\text{recon}}$
- $\mathcal{L}_{\text{adv-G}}, \mathcal{L}_{\text{length}}, \mathcal{L}_{\text{duration}}, \mathcal{L}_{\text{recon}}$ : 각각 adversarial, length, duration, reconstruction loss
- $\lambda_{\text{length}}, \lambda_{\text{duration}}, \lambda_{\text{recon}}$ : weighting term - Discriminator는 adversarial loss $\mathcal{L}_{\text{adv-D}}$를 통해 simultaneously train 되고, 이때 각 loss function은 다음과 같이 정의됨
- Adversarial Loss
- Adversarial training을 위한 least-square loss로써:
(Eq. 5) $\mathcal{L}_{\text{adv-D}}=\mathbb{E}_{(x,z)}[(D(z)-1)^{2}+D(G(x))^{2}]$
(Eq. 6) $\mathcal{L}_{\text{adv-G}}=\mathbb{E}_{x}[(D(G(x))-1)^{2}]$
- 여기서 discriminator는 real sample의 output을 1로 만들고, 합성된 sample의 output을 0으로 만듦
- 반면 generator는 real sample로 classifiy 될 sample을 생성하여 discriminator를 속이도록 training 됨 - Legnth Loss
- Length probability에 따라, $i$-th phoneme의 duration은:
(Eq. 7) $\mathbb{E}_{w_{i}\sim P(w_{i}|\mathbf{p}_{i})}[w_{i}]=\sum_{m=1}^{M}ml_{i,m}$
- 이때 전체 utterance의 expected length는 모든 phoneme duration prediction을 summing 하여 계산됨
- 결과적으로, 다음의 loss를 최소화하여 expected length가 ground-truth length $M_{\text{total}}$에 가까워지도록 함:
(Eq. 8) $\mathcal{L}_{\text{length}}=\frac{1}{N}\left| M_{\text{total}}-\sum_{i=1}^{N}\mathbb{E}_{w_{i}\sim P(w_{i}|\mathbf{p}_{i})}[w_{i}]\right|$ - Duration Loss
- 추론 속도를 향상하기 위해, duration predictor $f$를 사용하여 phoneme duration을 예측함
- 구체적으로, duration predictor는 phoneme hidden sequence $\mathbf{h}_{i}$를 input으로 사용하고, aligner에서 추출된 duration을 target으로 사용함
- Training 시에는 다음의 loss와 같이 duration predictor에서 encoder, aligner로의 gradient propagation을 막음:
(Eq. 9) $\mathcal{L}_{\text{duration}}=\frac{1}{N}\sum_{i=1}^{N}\left|f(\mathrm{sg}[\mathbf{h}_{i}])-\mathrm{sg}\left[\mathbb{E}_{w_{i}\sim P(w_{i}|\mathbf{p}_{i})}[w_{i}]\right] \right|$
- $\mathrm{sg}[.]$은 stop gradient operator이고, duration predictor의 output은 closest frame으로 discretize 됨
- 이때 duration predictor와 aligner가 유사한 output으로 수렴하도록 aligner는 discrete output을 encourage 하도록 training 됨 - Reconstruction Loss
- Phoneme sequence가 주어지면, network는 해당하는 음성을 합성할 수 있어야 하므로, feature matching loss와 spectral loss를 도입함:
(Eq. 10) $\mathcal{L}_{\text{recon}}=\mathbb{E}_{(x,z)}\left[\sum_{t=1}^{T}|| D^{(t)}(G(x))-D^{(t)}(z) ||_{1}\right]+\lambda_{\text{mel}}\mathbb{E}_{(x,z)}[|| \phi(G(x))-\phi(z)||_{1}]$
- $D^{(t)}$ : discriminator $D$의 $t$-th layer feature map, $\phi$ : mel-spectrogram의 log-magnitude, $\lambda_{\text{mel}}$ : weighting term
- Adversarial Loss
- Network Architecture and Efficient Implementation
- 먼저 AutoTTS의 encoder network는 transformer를 기반으로 구성됨
- 이때 FastSpeech와 같이 6개의 Feed-Forward Transformer (FFT) block stack을 활용
- 각 FFT block에는 9 kernel size의 1D convolution layer, self-attention이 포함되고, self-attention mechanism으로는 relative positional representation을 사용 - Decoder network는 2개의 FFT block과 upsampler network로 구성되어, raw audio waveform의 temporal resolution과 match 되도록 aligner의 output sequence를 upsampling 함
- 이때 upsampler는 HiFi-GAN의 fully-convolutional neural network를 활용하고, FFT block은 data의 long-term dependency를 capture 하기 위해 사용됨 - Aligner network는 ReLU activation, layer normalization, dropout이 포함된 5 kernel size의 3개 convolution layer로 구성됨
- 여기서 $w_{i}$를 characterize 하는 distribution의 parameter를 포함하는 size $M$의 vector에 hidden state를 projection 하는 linear layer가 추가됨
- Duration predictor는 last linear layer가 phoneme duration에 대한 single scalar를 output 한다는 점을 제외하면 aligner와 유사한 architecture를 따름 - 한편으로 AutoTTS는 training을 위해 HiFi-GAN의 multi-period discriminator와 multi-scale discriminator를 채택함
- 이때 FastSpeech와 같이 6개의 Feed-Forward Transformer (FFT) block stack을 활용
- AutoTTS는 보다 stable 하고 efficient 한 training을 위해 다음의 방식을 적용함:
- 먼저, (Eq. 1)의 cumulative product는 gradient computation에 대해 numerically unstable 함
- 따라서 log-space에서 해당 product를 계산하여 unstable 문제를 해결 - (Eq. 2)의 probability matrix $q$와 (Eq. 3)의 $s$ 계산은 compuationally expensive 함
- Convolution operation에 대한 parallel computing을 적용하여 cost를 줄임 - 추가적으로 length probability는 soft output을 생성하므로 attention proability matrix $s$가 hard alignment를 생성하지 못할 수 있음
- 이상적으로는, 추론 시 length regulator에 대한 alignment를 가능하게 하는 discrete duration을 가져야 함
- 따라서 discreteness를 위해 $l$을 생성하는 sigmoid function 이전에 zero-mean, unit-variance의 Gaussian noise를 추가함
- 먼저, (Eq. 1)의 cumulative product는 gradient computation에 대해 numerically unstable 함
3. Experiments
- Settings
- Dataset : LJSpeech
- Comparisons : FastSpeech2, Tacotron2
- Results
- MOS 측면에서 제안된 AutoTTS는 가장 우수한 성능을 보임

- 추론 속도 측면에서도 AutoTTS는 가장 빠른 것으로 나타남

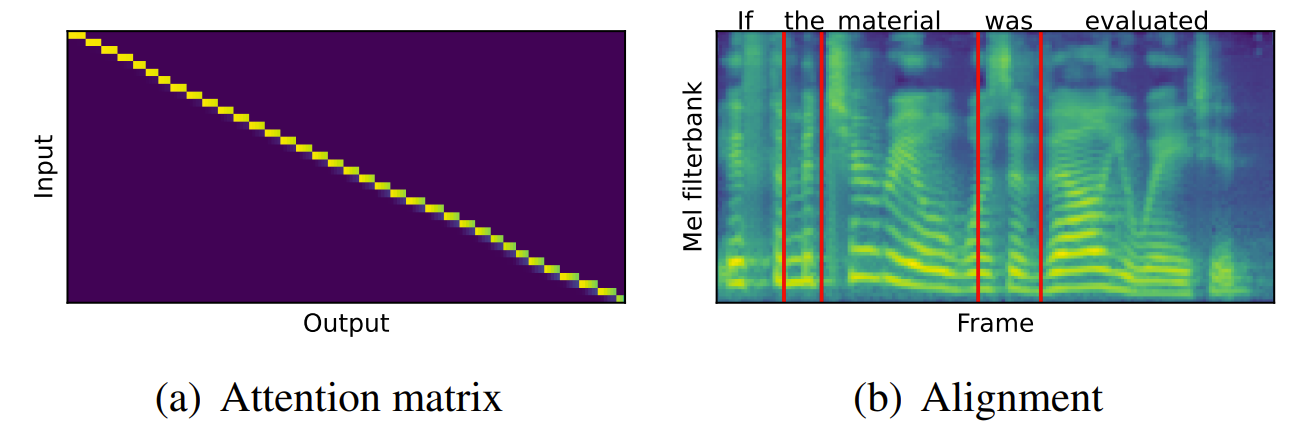
- Utterance에 대한 alignment matrix를 시각화해 보면, 아래 그림의 (a)와 같이 hard, monotonic alignment로 수렴하는 것을 확인할 수 있음
- 특히 (b)와 같이, AutoTTS는 word level의 duration을 추출할 수 있음
반응형
'Paper > TTS' 카테고리의 다른 글
댓글