

 [Paper 리뷰] CoMoSpeech: One-Step Speech and Singing Voice Synthesis via Consistency Model
[Paper 리뷰] CoMoSpeech: One-Step Speech and Singing Voice Synthesis via Consistency Model
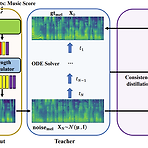
CoMoSpeech: One-Step Speech and Singing Voice Synthesis via Consistency ModelDenoising Diffusion Probabilistic Model은 음성 합성에서 우수한 성능을 보이고 있지만, 고품질의 sample을 얻기 위해서는 많은 iterative step이 필요함- 결과적으로 추론 속도 저하로 이어짐CoMoSpeechSingle diffusion sampling step만으로 고품질의 합성을 수행하는 Consistency model-based 음성 합성 모델Consistency constraint는 diffusion-based teacher model에서 consistency model을 distill 하기 위해 사용됨논문 (MM 20..
 [Paper 리뷰] StyleSinger: Style Transfer for Out-of-Domain Singing Voice Synthesis
[Paper 리뷰] StyleSinger: Style Transfer for Out-of-Domain Singing Voice Synthesis
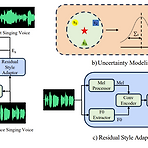
StyleSinger: Style Transfer for Out-of-Domain Singing Voice SynthesisSinging Voice Synthesis의 경우 높은 expressiveness를 요구하기 때문에 voice style을 모델링하는 것이 까다로움특히 기존의 모델들은 training 단계에서 target vocal attribute를 discernible 한다는 가정에 기반하기 때문에 out-of-domain 환경으로 확장이 어려움StyleSingerResidual quantization module을 통해 다양한 style을 capture 하는 Residual Style Adaptor의 적용Style attribute를 perturb 하여 generalization을 향상하는 U..
 [Paper 리뷰] Singing Voice Synthesis based on a Musical Note Position-aware Attention Mechanism
[Paper 리뷰] Singing Voice Synthesis based on a Musical Note Position-aware Attention Mechanism
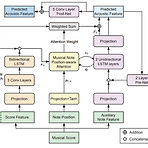
Singing Voice Synthesis based on a Musical Note Position-aware Attention Mechanism Singing Voice Synthesis를 위해 acoustic, temporal 모델링을 동시에 수행할 수 있는 sequence-to-sequence 모델을 활용할 수 있음 Musical Note Position-aware Attention Musical score가 주는 rhythm을 고려하여 attention weight를 추정 제안하는 attention mechanism을 활용하여 sequence-to-sequence 모델에서 simultaneous 모델링을 수행하고 temporal 모델링에 대한 robustness를 향상 논문 (ICASSP 202..
 [Paper 리뷰] Singing Voice Synthesis Using Differentiable LPC and Glottal-Flow-Inspired Wavetables
[Paper 리뷰] Singing Voice Synthesis Using Differentiable LPC and Glottal-Flow-Inspired Wavetables
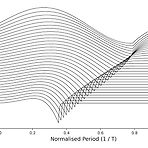
Singing Voice Synthesis Using Differentiable LPC and Glottal-Flow-Inspired Wavetables Singing Voice Synthesis를 위해 human voice의 physical characteristic을 활용할 수 있음 Glottal-Flow LPC Filter (GOLF) Harmonic source로써 glottal model을 사용하고, vocal tract를 simulate 하기 위해 IIR filter를 활용 GOLF는 더 적은 parameter와 memory를 사용함으로써 빠른 추론이 가능함 GOLF는 singing voice를 다양화할 수 있는 phase component를 modelling할 수 있음 논문 (ISMIR 20..
 [Paper 리뷰] LiteSing: Towards Fast, Lightweight and Expressive Singing Voice Synthesis
[Paper 리뷰] LiteSing: Towards Fast, Lightweight and Expressive Singing Voice Synthesis
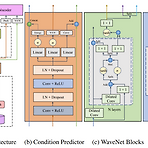
LiteSing: Towards Fast, Lightweight and Expressive Singing Voice Synthesis 경량화된 고품질의 Singing Voice Synthesis 시스템이 필요함 LiteSing Generative Adversarial Network architecture 하에서 악보의 full condition을 예측하고, 해당 condition에서 acoustic feature를 생성 Dynamic spectrogram energy, Voiced/Unvoiced decision, Dynamic pitch curve를 구성해 expressiveness를 향상 Pitch와 timbre를 개별적으로 예측하여 두 feature의 interdependence를 회피 논문 (IC..
 [Paper 리뷰] UniSyn: An End-to-End Unified Model for Text-to-Speech and Singing Voice Synthesis
[Paper 리뷰] UniSyn: An End-to-End Unified Model for Text-to-Speech and Singing Voice Synthesis
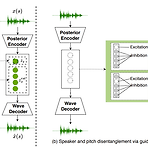
UniSyn: And End-to-End Unified Model for Text-to-Speech and Sining Voice Synthesis Text-to-Speech와 Singing Voice Synthesis를 단일 시스템으로 통합하는 기존의 방법들은, 동일한 화자로 제한되거나 cascaded model에 의존하는 한계가 있음 UniSyn 음성 합성과 가창 합성을 통합한 end-to-end 모델 Speaker와 style을 condition으로 사용하는 Multi-Conditional Variational AutoEncoder 구조 Timbre와 style의 disentangle을 위한 supervised guided-VAE와 Wasserstein distance 기반 timbre pertur..