

 [Paper 리뷰] PeriodSinger: Integrating Periodic and Aperiodic Variational Autoencoders for Natural-Sounding End-to-End Singing Voice Synthesis
[Paper 리뷰] PeriodSinger: Integrating Periodic and Aperiodic Variational Autoencoders for Natural-Sounding End-to-End Singing Voice Synthesis
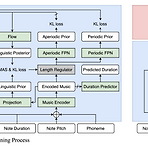
PeriodSinger: Integrating Periodic and Aperiodic Variational Autoencoders for Natural-Sounding End-to-End Singing Voice Synthesis자연스러운 waveform을 합성하기 위해서는 deterministic pitch conditioning으로 인한 one-to-many 문제를 해결해야 함PeriodSingerPeriodic/aperiodic component에 대한 variational autoencoder를 활용Note boundary 내에서 monotonic alignment search를 통해 phoneme alignment를 추정함으로써 external aligner에 대한 의존성을 제거논문 (INTE..
 [Paper 리뷰] MakeSinger: A Semi-Supervised Training Method for Data-Efficient Singing Voice Synthesis via Classifier-free Diffusion Guidance
[Paper 리뷰] MakeSinger: A Semi-Supervised Training Method for Data-Efficient Singing Voice Synthesis via Classifier-free Diffusion Guidance
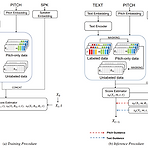
MakeSinger: A Semi-Supervised Training Method for Data-Efficient Singing Voice Synthesis via Classifier-free Diffusion GuidanceSinging voice synthesis를 위해 semi-supervised training을 활용할 수 있음MakeSingerLabeling에 관계없이 모든 speech, singing voice data에서 diffusion-based model을 trainingDual guiding mechanism을 통해 maske input의 score를 추정하여 reverse diffusion step에 대한 text/pitch guidance를 제공논문 (INTERSPEECH 202..
 [Paper 리뷰] TokSing: Singing Voice Synthesis based on Discrete Tokens
[Paper 리뷰] TokSing: Singing Voice Synthesis based on Discrete Tokens
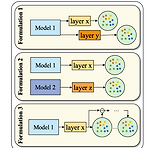
TokSing: Singing Voice Synthesis based on Discrete TokensSelf-supervised learning model에서 추출된 discrete token을 활용하여 singing voice synthesis의 성능을 향상할 수 있음TokSingFlexible token blending을 제공하는 token formulator를 갖춘 discrete-based singing voice synthesis modelMelody signal을 discrete token과 integrate 하고 musical encoder에 melody enhancement strategy를 도입논문 (INTERSPEECH 2024) : Paper Link1. IntroductionSin..
 [Paper 리뷰] Prompt-Singer: Controllable Singing-Voice-Synthesis with Natural Language Prompt
[Paper 리뷰] Prompt-Singer: Controllable Singing-Voice-Synthesis with Natural Language Prompt
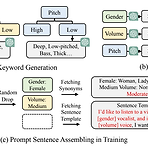
Prompt-Singer: Controllable Singing-Voice-Synthesis with Natural Language PromptSinging Voice Synthesis는 여전히 style attribute를 explicitly control 하는 것이 어려움Prompt-SingerGender, vocal range, volume 등을 natural language prompt로 control하는 singing voice synthesis 모델Multi-scale hierarchy를 가지는 decoder-only transformer를 기반으로 melodic accuracy를 유지하면서 text-conditioned vocal range control이 가능한 range-melody de..
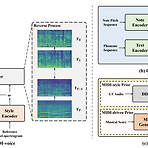 [Paper 리뷰] MIDI-Voice: Expressive Zero-Shot Singing Voice Synthesis via MIDI-Driven Priors
[Paper 리뷰] MIDI-Voice: Expressive Zero-Shot Singing Voice Synthesis via MIDI-Driven Priors
MIDI-Voice: Expressive Zero-Shot Singing Voice Synthesis via MIDI-Driven Priors기존의 Singing Voice Synthesis 모델은 unseen speaker와 fundamental frequency를 부정확하게 예측하므로 낮은 합성 품질을 보임MIDI-Voice더 나은 singing voice style adaptation을 위해 MIDI-based prior를 score-based diffusion model에 적용특히 MIDI-driven prior를 생성하여 note information을 반영하고 고품질의 style adaptation을 지원추가적으로 expressive synthesis를 위해 DDSP-based MIDI-sty..
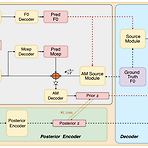 [Paper 리뷰] SiFiSinger: A High-Fidelity End-to-End Singing Voice Synthesizer based on Source-Filter Model
[Paper 리뷰] SiFiSinger: A High-Fidelity End-to-End Singing Voice Synthesizer based on Source-Filter Model
SiFiSinger: A High-Fidelity End-to-End Singing Voice Synthesizer based on Source-Filter ModelHigh-fidelity human-like singing voice synthesis를 위해 source-filter mechanism을 활용할 수 있음SiFiSingerVITS에서 확장된 training paradigm을 활용하고 fundamental pitch ($F0$) predictor, waveform decoder 등의 component를 통합Interwined mel-spectrogram과 $F0$ characteristic을 decouple하기 위해 mel-cepstrum feature를 활용Pitch nuance를 보다 정..