

반응형
 [Paper 리뷰] DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism
[Paper 리뷰] DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism
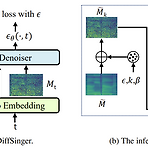
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism Singing Voice Synthesis (SVS)는 음향 feature 재구성을 위해 간단한 Loss나 GAN을 활용함 각각의 방식은 over-smoothing 문제와 불안정한 학습과정으로 인해 부자연스러운 음성을 만들어냄 DiffSinger Diffusion probabilistic 모델 기반의 SVS용 음향 모델 조건부 분포 하에서 노이즈를 mel-spectrogram으로 반복적으로 변환하는 parameterized Markov chain Variational bound를 최적화함으로써 안정적이고 자연스러운 음성을 합성 논문 (AAAI 2022) : Paper Link 1. I..
Paper/SVS
2023. 8. 15. 13:37
반응형