

티스토리 뷰
Paper/SVS
[Paper 리뷰] StyleSinger: Style Transfer for Out-of-Domain Singing Voice Synthesis
feVeRin 2024. 3. 26. 10:49반응형
StyleSinger: Style Transfer for Out-of-Domain Singing Voice Synthesis
- Singing Voice Synthesis의 경우 높은 expressiveness를 요구하기 때문에 voice style을 모델링하는 것이 까다로움
- 특히 기존의 모델들은 training 단계에서 target vocal attribute를 discernible 한다는 가정에 기반하기 때문에 out-of-domain 환경으로 확장이 어려움
- StyleSinger
- Residual quantization module을 통해 다양한 style을 capture 하는 Residual Style Adaptor의 적용
- Style attribute를 perturb 하여 generalization을 향상하는 Uncertainty Modeling Layer Normalization
- 논문 (AAAI 2024) : Paper Link
1. Introduction
- Singing Voice Synthesis (SVS)는 가사와 musical note를 사용하여 고품질의 가창 음성을 합성하는 작업
- Out-of-Domain (OOD) style transfer는 reference sample에서 파생된 unseen style로 고품질의 sample을 생성하는 것을 목표로 함
- 특히 SVS 작업을 위한 가창 음성 style에는 timbre, emotion, pronunciation, articulation skill 등이 포함됨
- Timbre는 음성의 distinctive quality를 나타내고, emotion은 연주 중에 전달되는 expressiveness를 capture 함
- Pronunciation과 articulation skill에는 vibrato, pitch transition, enunciation skill 등이 포함됨 - BUT, 기존의 SVS 모델들은 training 단계에서 vocal attribute를 discernible 한다는 가정에 기초하기 때문에, OOD 설정에서 합성된 sample의 품질이 저하됨
- OOD SVS style transfer에 대한 주요 한계점은 다음과 같이 요약할 수 있음
- 가창 음성의 expressiveness를 반영하고 intricate nuance를 모델링할 수 있어야 함
- Pronunciation, articulation skill과 같은 detailed style을 모델링하는 방법이 필요함 - OOD reference sample과 training data 간의 차이로 인해 합성된 가창 음성의 품질이 저하되지 않아야 함
- 따라서 모델의 generalization을 위한 효과적인 방법이 필요함
- 가창 음성의 expressiveness를 반영하고 intricate nuance를 모델링할 수 있어야 함
-> 그래서 OOD reference style에 대해 zero-shot style transfer가 가능한 SVS 모델인 StyleSinger를 제안
- StyleSinger
- 다양한 style information을 capture 하기 위해 Residual Style Adaptor (RSA)를 도입
- RSA는 reference style에서 detailed style characteristic을 capture 하기 위해 residual quantization module을 활용함 - 모델 generalization을 개선하기 위해 Uncertainty Modeling Layer Normalization (UMLN)을 도입
- UMLN은 training 단계에서 content 내의 style attribute를 perturb 함으로써 unseen speaker에 대한 대응 능력을 향상 가능
- 다양한 style information을 capture 하기 위해 Residual Style Adaptor (RSA)를 도입
< Overall of StyleSinger >
- StyleSinger는 reference sample에서 파생된 unseen style로 고품질의 가창 음성을 생성하는 OOD zero-shot SVS 모델
- RSA를 통한 style characteristic 반영과 UMLN을 통한 generalization 향상
- 결과적으로 기존 모델들에 비해 뛰어난 audio 품질과 reference style에 대한 similarity를 달성
2. Method
- Problem Formulation
- Target 가사와 musical note가 주어졌을 때,
- OOD SVS를 위한 style transfer는 unseen style을 사용하여 고품질의 가창 음성을 생성하는 것을 목표로 함
- 이때 unseen style은 reference 가창 음성 sample에서 추출됨
- Overview
- StyleSinger의 architecture는
- 먼저 가사는 phoneme encoder를 통해 encode 되고 musical note는 note encoder를 통해 capture 됨
- Reference 가창 음성으로부터 timbre와 emotion을 추출하기 위해, pre-trained wav2vec 2.0을 사용함
- 이후 모델을 style-agnostic, style-specific part로 split 함
- 다음으로 duration prediction을 수행하고, Uncertainty Modeling Layer Normalization (UMLN)을 활용하여 content representation의 style information을 perturb 함
- 이를 통해 StyleSinger는 generalization이 향상되고 style-agnostic representation을 얻을 수 있음 - Residual Style Adaptor (RSA)는 reference 가창 음성으로부터 residaul quantization module을 사용하여 detailed style information을 capture 해 style-specific representation을 얻음
- Pitch diffusion predictor는 style-agnostic, style-specific representation 모두를 input으로 사용하여 $F0$와 UV를 생성
- 최종적으로 diffusion decoder는 mel-spectrogram을 생성하고, BigVGAN vocoder를 통해 target 가창 음성을 생성
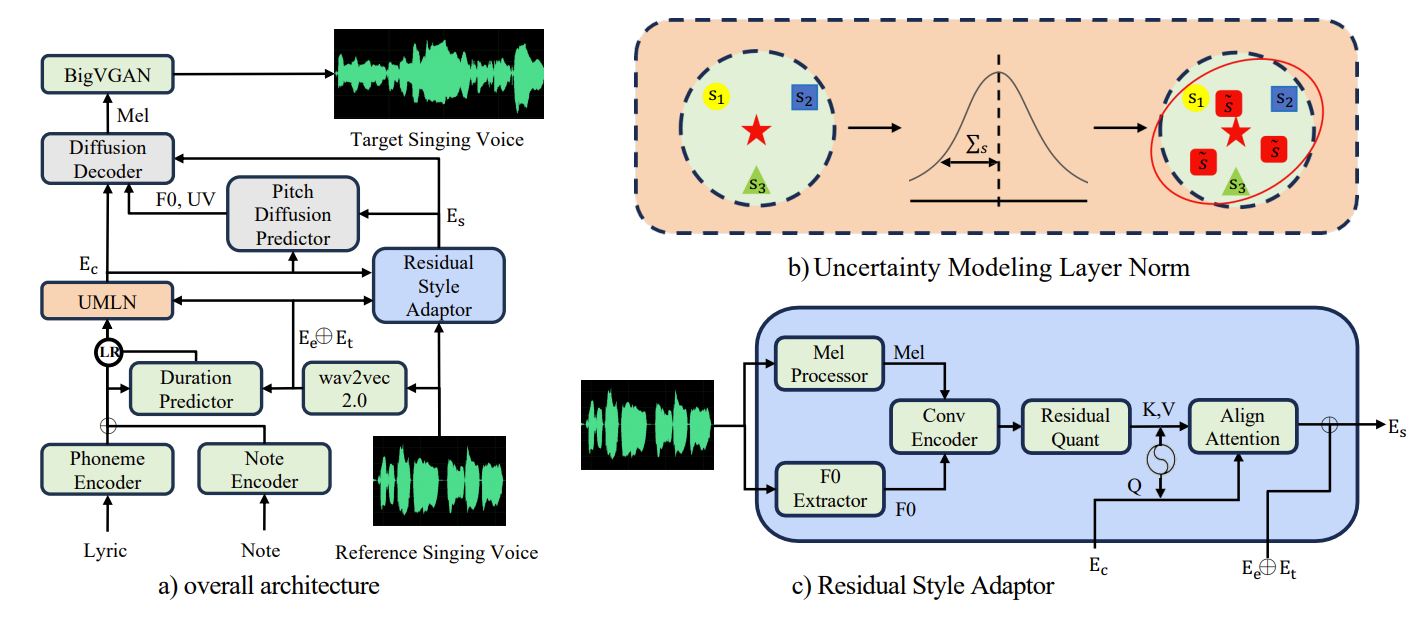
- Uncertainty Modeling Layer Normalization
- 일반적으로 style vector는 encoder output과 concatenating 되어 generator에 incorporate 되지만, 해당 방식은 OOD 설정에서 모델 성능을 저하시킴
- 이를 해결하기 위해 style adaptation을 위한 conditional layer normalization을 고려할 수 있음
- 따라서 style information에 perturbation을 제공하는 layer normalization을 통해 generalization 성능을 향상할 수 있는 Uncertainty Modeling Layer Noramlization (UMLN)을 제안함
- 먼저 hidden vector $x$를 사용하여 평균 $\mu$와 분산 $\delta$를 계산할 수 있음
- 이때 style vector $s$가 주어지면, 2개의 linear layer를 사용하여 vector를 bias vector $\beta(s)$와 scale vector $\gamma(s)$로 변환함
- 여기서 style information을 perturb 하기 위해 Gaussian 분포를 사용하여 style embedding의 uncertainty scope를 모델링함
- Uncertainty scope 내에서의 sampling을 통해 unseen speaker에 대한 style information을 효과적으로 simulation 하고, 나아가 모델이 style-consistent representation을 생성하는 것을 방지할 수 있음 - 이후 style embedding에 inherent 된 uncertainty를 capture 하기 위해 scale/bias vector의 분산을 계산:
(Eq. 1) $\Sigma_{\gamma}^{2}(s)=\frac{1}{B}\sum_{b=1}^{B}(\gamma(s)-\mathbb{E}_{b}[\gamma(s)])^{2}, \,\,\, \Sigma_{\beta}^{2}(s)=\frac{1}{B}\sum_{b=1}^{B}(\beta(s)-\mathbb{E}_{b}[\beta(s)])^{2}$
- $\Sigma_{\gamma}, \Sigma_{\beta}$ : style embedding $s$의 uncertainty estimation
- Uncertainty estimation의 magnitude는 style embedding 내에서 transpire 할 수 있는 potential transformation을 제공함
- UMLN은 style-agnostic representation을 foster 하기 위해 random sampling을 활용
- 이를 위해 scale/bias vector를 다음과 같이 update 함:
(Eq. 2) $\gamma_{um}(s)=\gamma(s)+\epsilon_{\gamma}\Sigma^{2}_{\gamma}(s), \,\,\, \beta_{um}(s)=\beta(s)+\epsilon_{\beta}\Sigma^{2}_{\beta}(s)$
- $\epsilon_{\gamma}, \epsilon_{\beta}$ : standard Gaussian $\mathcal{N}(0,1)$에서 얻어짐 - 위와 같이 scale/bias vector를 updating 했을 때 style-agnostic hidden representation은:
(Eq. 3) $UMLN(x,s)=\gamma_{um}(s)\frac{x-\mu(x)}{\delta(x)}+\beta_{um}(s)$
- 이를 위해 scale/bias vector를 다음과 같이 update 함:
- 최종적으로 StyleSinger은 input feature를 assiduously refine 하여 style-agnostic representation을 얻음
- 이때 해당 moduel 내에서 delicate balance를 위해, training 단계에서 UMLN을 사용할 확률을 나타내는 hyperparameter $p$를 도입하고, 아래 [Algorithm 1]과 같이 동작함

- Residual Style Adaptor
- 가창 음성 style을 intricately modeling 하기 위해 wav2vec 2.0을 사용하여 timbre와 emotion attribute를 capture 함
- 이때 pronunciation이나 articulation skill과 같은 추가적인 style information을 반영하기 위해 Residual Style Adaptor (RSA)를 제안
- 먼저 reference 가창 음성 sample에서 mel-spectrogram과 $F0$를 추출하고 encoding 함
- 이때 parselmouth를 활용하여 $F0$ informatino을 추출 - 다음으로 Residual Quantization (RQ) module을 통해 information bottleneck을 설정하고 non-style information을 제거하여 detailed style feature를 추출함
- Multiple layer의 information을 추출하는 RQ로 인해 다양한 hierarchical level에 걸쳐 style information에 대한 comprehensive, detailed modeling이 가능함
- 먼저 reference 가창 음성 sample에서 mel-spectrogram과 $F0$를 추출하고 encoding 함
- RSA의 conv encoder는 output $E$를 생성하고, 이때 quantization depth $N$을 사용하여 RQ module은 $E$를 $N$개의 ordered code sequence로 represent 함
- $RQ_{e}(E)$는 $E$를 code의 stacked map으로 represent 하고 code embedding을 추출하는 process라 하고, depth $n\in[N]$에서 RQ module의 $E$ representation을 $\hat{E}^{n}=\sum_{i=1}^{n}RQ_{e}(E)$라 하자
- 이때 input representation이 discrete embedding을 adhere 하는지 확인하기 위해 commitment loss가 사용됨:
(Eq. 4) $\mathcal{L}_{c}=\sum_{d=1}^{D}|| E-sg[\hat{E}^{n}]||_{2}^{2}$
- $sg$ : stop gradient operator - $\mathcal{L}_{c}$는 single term이 아니라 모든 $n$ iteration에 걸친 quantization error의 cumulative sum임
- 따라서 objective는 $n$이 증가함에 따라 $\hat{E}^{n}$이 $E$의 quantization error를 감소시켜야 함
- $RQ_{e}(E)$는 $E$를 code의 stacked map으로 represent 하고 code embedding을 추출하는 process라 하고, depth $n\in[N]$에서 RQ module의 $E$ representation을 $\hat{E}^{n}=\sum_{i=1}^{n}RQ_{e}(E)$라 하자
- RQ module에서 detailed style embedding을 생성한 다음, embedding을 content representation $E_{c}$와 align 해야 함
- 이를 위해 Scaled Dot-Product Attention mechanism을 채택한 Align Attention module을 도입함
- 먼저 attention module에 detailed style embedding을 제공하기 전에, positional encoding을 반영 - 이후 attention module에서 $E_{c}$는 query, detailed style embedding $E_{d}$는 key, value로 사용됨:
(Eq. 5) $Attention(Q,K,V)=Attention(E_{c},E_{d},E_{d})=Softmax\left(\frac{E_{c}E_{d}^{T}}{\sqrt{d}}\right)E_{d}$
- $d$ : key, query의 dimensionality
- 이를 위해 Scaled Dot-Product Attention mechanism을 채택한 Align Attention module을 도입함
- 최종적으로 content representation과 wav2vec 2.0에서 생성된 timbre, emotion embedding을 integrate 함
- 이러한 integration을 통해 StyleSinger는 style-specific representation을 획득할 수 있음
- 이때 pronunciation이나 articulation skill과 같은 추가적인 style information을 반영하기 위해 Residual Style Adaptor (RSA)를 제안
- Architectural Details
- Encoder
- Phoneme encoder와 note encoder로 구성됨
- Phoneme encoder는 phoneme을 input으로 하여 phoneme feature를 생성하는 FastSpeech2 architecture를 활용함
- Note encoder는 note pitch, note type, note duration을 input으로 하여 note feature를 생성함 - 이때 phoneme feature와 note feature를 결합하여 content representation을 생성함
- Phoneme encoder와 note encoder로 구성됨
- Pitch Diffusion Predictor
- 단순한 pitch predictor는 SVS 작업에 적합하지 않으므로, 가창 음성의 다양한 style을 capture 하기 위해 pitch diffusion predictor를 사용
- Pitch diffusion predictor는 style-specific/style-agnostic pitch diffusion predictor 두 가지로 구성됨
- 해당 predictor들의 output을 결합하여 $F0$와 UV에 대한 final prediction을 얻음 - Predictor module의 optimization은 Gaussian diffusion loss와 multinomial diffusion loss를 활용함
- Diffusion Decoder
- 가창 음성의 dynamic nature로 인해 기존의 mel-decoder로는 가창 음성의 nuance를 효과적으로 capture 하기 어려움
- 따라서 StyleSinger는 diffusion decoder를 채택하여 mel-spectrogram을 생성함
- 구조적으로는 4-step generator-based diffusion model인 ProDiff의 teacher model을 채택 - Diffusion decoder training을 위해 Mean Absolute Error (MAE) loss와 Structural Similarity Index (SSIM) loss를 사용

- Pre-Training, Training and Inference Procedures
- StyleSinger의 final loss term은 다음과 같이 구성됨
- Duration prediction loss $\mathcal{L}_{dur}$ : 예측값과 ground-truth phoneme-level duration 간의 log-scale MSE
- Pitch reconstruction loss $\mathcal{L}_{gdiff}, \mathcal{L}_{mdiff}$ : pitch diffusion predictor의 Gaussian diffusion loss, multinomial diffsuion loss
- RQ loss $\mathcal{L}_{c}$ : residual quantization layer에 대한 commitment loss
- Mel-reconstruction loss $\mathcal{L}_{mae}, \mathcal{L}_{ssim}$ : diffusion decoder의 MAE loss, SSIM loss
- Pre-training 단계에서는 AM softmax loss에 따라 timbre와 emotion을 classify 하도록 wav2vec 2.0 모델을 training 함
- StyleSinger training 시에는 reference, target 가창 음성은 변경되지 않음
- 추론 시에는 target 가창 음성의 가사와 musical note를 input 하고, unseen reference sample을 사용하여 target 가창 음성을 OOD reference style로 합성함
3. Experiments
- Settings
- Dataset : Chinese song corpus, M4Singer dataset
- Comparisons : STYLER, GenerSpeech, YourTTS, Multi-Style RMSSinger
- Results
- Parallel Style Transfer
- Reference voice가 변경되지 않은 OOD 환경에서, 모델의 성능을 비교해 보면
- StyleSinger는 정량적, 주관적 평가 모두에서 우수한 성능을 보임
- 특히 style similarity를 나타내는 SMOS도 가장 높아, 다양한 singing style을 정확하게 모델링하고 capture 할 수 있음을 보임

- Non-Parallel Style Transfer
- Unseen reference sample에 대한 합성 결과를 살펴보면
- 마찬가지로 StyleSinger로 합성된 sample이 가장 선호되는 것으로 나타남

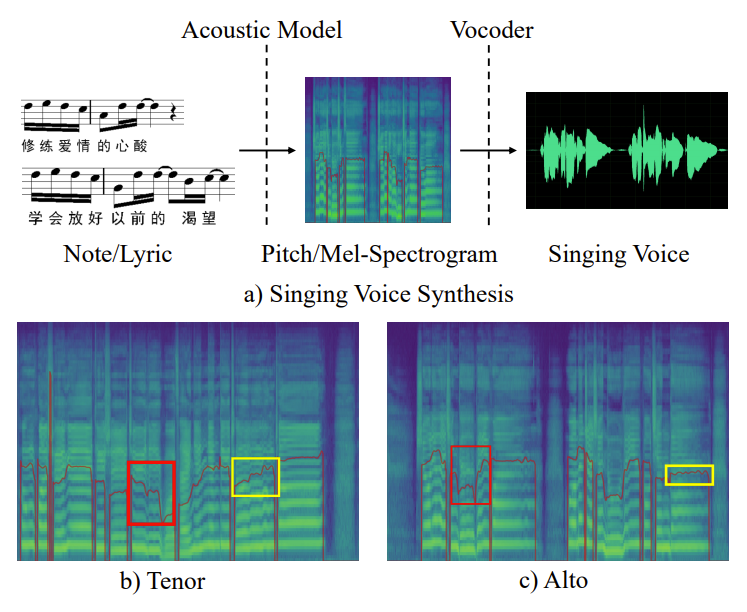
- Mel-spectrogram과 pitch contour 측면에서 합성된 sample을 비교해 보면
- StyleSinger의 pitch contour는 다양한 variation과 finer detail을 반영하여 reference style과 유사하게 나타남
- StyleSinger의 mel-spectrogram은 adjacent harmonics와 high-frequency component 간의 frequency bin에서 rich detail을 반영 가능하고, 결과적으로 뛰어난 합성 품질을 달성 가능

- Ablation Study
- StyleSinger에 대한 ablation study를 수행해 보면
- UMLN을 제거하는 경우, 합성 품질과 similarity가 저하되어 generalization 성능이 떨어지는 것으로 나타남
- RSA를 제거하는 경우, similarity가 크게 저하되는 것으로 나타남
- Pitch diffusion predictor와 diffusion decoder 역시 고품질 mel-spectrogram 생성에 중요한 역할을 함

반응형
'Paper > SVS' 카테고리의 다른 글
댓글