

티스토리 뷰
Paper/SVS
[Paper 리뷰] UniSyn: An End-to-End Unified Model for Text-to-Speech and Singing Voice Synthesis
feVeRin 2024. 1. 4. 09:58반응형
UniSyn: And End-to-End Unified Model for Text-to-Speech and Sining Voice Synthesis
- Text-to-Speech와 Singing Voice Synthesis를 단일 시스템으로 통합하는 기존의 방법들은, 동일한 화자로 제한되거나 cascaded model에 의존하는 한계가 있음
- UniSyn
- 음성 합성과 가창 합성을 통합한 end-to-end 모델
- Speaker와 style을 condition으로 사용하는 Multi-Conditional Variational AutoEncoder 구조
- Timbre와 style의 disentangle을 위한 supervised guided-VAE와 Wasserstein distance 기반 timbre perturbation
- 논문 (AAAI 2023) : Paper Link
1. Introduction
- Text-to-Speech (TTS)와 Singing Voice Synthesis (SVS)는 광범위하게 적용되고 있음
- TTS와 SVS 모델 모두 학습을 위해서 동일한 speaker의 고품질 음성/가창 음성을 필요로 함
- 특히 가창 음성 data를 얻는 것은 일반적인 음성 corpus 구축보다 어려움 - 이를 해결하기 위해 TTS와 Singing Voice Conversion (SVC)을 활용한 cascaded 모델을 적용해 볼 수 있음
- BUT, 파이프라인이 복잡하고 유연하지 않음
- TTS와 SVS 모델 모두 학습을 위해서 동일한 speaker의 고품질 음성/가창 음성을 필요로 함
- TTS와 SVS 모두 abstract information (text / 악보)으로부터 보컬을 생성하는 유사한 파이프라인을 공유함
- 음성/가창 음성 data 없이도 target speaker timbre을 활용할 수 있는 통합 모델을 생각해 볼 수 있음
- TTS와 SVS를 하나로 통합하기 위한 몇 가지 어려움이 존재함
- SVS의 입력인 악보는 TTS의 text와 상당히 다름
- TTS 음성과 SVS의 가창 음성은 동일한 조음 시스템으로 생성되지만, timbre와 prosody 측면에서 acoustic 특징의 상당한 차이가 있음
- Source audio의 speaker timbre와 style은 entangle 되어 있음
- 특히 학습 단계에서 entanglement로 인해 timbre leakage 문제가 발생
- 위의 어려움으로 인해 통합된 TTS-SVS 모델을 구축하기 위해서 주로 waveform에서 추출된 explicit feature (pitch contour, rhythm 등)을 입력으로 활용했음
- BUT, Reference signal이 추론 시에 항상 필요하기 때문에, 임의의 노래를 합성할 수 없는 단점
-> 그래서 TTS, SVS 작업을 위한 end-to-end 통합 모델인 UniSyn을 제안
- UniSyn
- Waveform을 latent space로 encoding 하는 Variational AutoEncoder
- Input linguistic representation에서 latent 분포를 추정하는 Prior model
- Sampled latent variable에서 waveform을 생성하는 Wave decoder
- 추가적으로 통합 모델링을 위해 TTS의 text와 SVS의 악보에 대한 unified linguistic representation을 제안
- 두 개의 독립적인 sub-space로 나누어 learned latent space를 해석하는 Multi-Conditional Variational AutoEncoder (MC-VAE)를 도입
- 하나의 sub-space는 speaker identity에 대한 speaker condtion
- 다른 하나는 나머지 input representation에 대한 voice condition - Timbre와 style의 disentanglement를 위해 speaker identity와 pitch contour를 supervision으로 채택하여 latent를 분리
- Wasserstein distance 제약을 적용한 timbre perturbation strategy를 도입
- 나머지 sub-space를 보조적으로 학습하여 disentangled speaker timbre의 robustness를 향상
- 두 개의 독립적인 sub-space로 나누어 learned latent space를 해석하는 Multi-Conditional Variational AutoEncoder (MC-VAE)를 도입
< Overall of UniSyn >
- TTS와 SVS를 위한 통합 end-to-end 합성 모델
- MC-VAE를 통해 interpretable latent space를 유연하게 제어하고, Guided-VAE, formant perturbation을 활용해 disentanglemenet를 확보
- 가창 data가 없는 경우에 대해서도 최신 end-to-end 모델보다 뛰어난 성능을 달성
2. UniSyn
- Unified Textual Features for TTS and SVS
- 일반 음성과 가창 음성은 동시에 rhythm, pitch, speaking style, text content와 같은 explicit acoustic feature로 분해될 수 있음
- 통합된 음성 합성을 위해서는 일반 대화와 가창에 대한 unified textual representation이 필요함
- TTS의 text information은 phoneme, tone, phoneme duration으로 factorize 될 수 있음
- SVS의 악보는 phoneme, note pitch ID, phoneme duration, note duration으로 factorize 될 수 있음 - Text와 악보 input 간의 공통점과 차이점을 잘 factorize 하는 것이 필요함
- 통합된 음성 합성을 위해서는 일반 대화와 가창에 대한 unified textual representation이 필요함
- 공통되는 부분의 경우,
- Linguisitc content는 대화와 가창 모두에 대한 phoneme attribute ($pho$)로 정의
- 대화와 가창에서 멜로디 변화는 악보의 note pitch ID와 input text의 tone을 merge 하여 정의 ($tp$)
- 두 특징 모두 멜로디의 acoustic feature를 결정하기 때문
- Phoneme duration $dur_{pho}$는 대화와 가창의 rhythm을 정의
- 가창 음성에 대한 phoneme duration은 악보에 대한 note duration $dur_{note}$에 의해 제한됨
- Unified representation을 위해 대화 음성에 대한 $dur_{note}$ placeholder를 설정
- Prosody rhythm을 통합하기 위해 shared duration predictor를 사용하여 대화와 가창 음성 모두에 대한 phoneme duration을 모델링 - $dur_{pho}$는 $pho, dur_{note}$와 style tag에 영향을 받음
- Duration model에서 phoneme duration을 더 정확하게 추정하기 위해 relative positional attribute $pos$를 도입
- 현재 악보의 음표나 speaking syllable에서 전체 phoneme 수와 현재 phoneme의 순위를 기반으로 구해짐
- 가창 음성에 대한 phoneme duration은 악보에 대한 note duration $dur_{note}$에 의해 제한됨
- Attribute set $Enc_{in} = \{ pho, tp \}$는 text encoder의 linguistic information을 모델링하는 데 사용됨
- Duration predictor는 $Dur_{in} = \{ pho, dur_{note}, pos, style \}$을 사용하여 일반 대화와 가창에 대한 phoneme duration을 예측함
- 이후 length regulator에 적용되어 acoustic latent feature의 time resolution을 matching 함
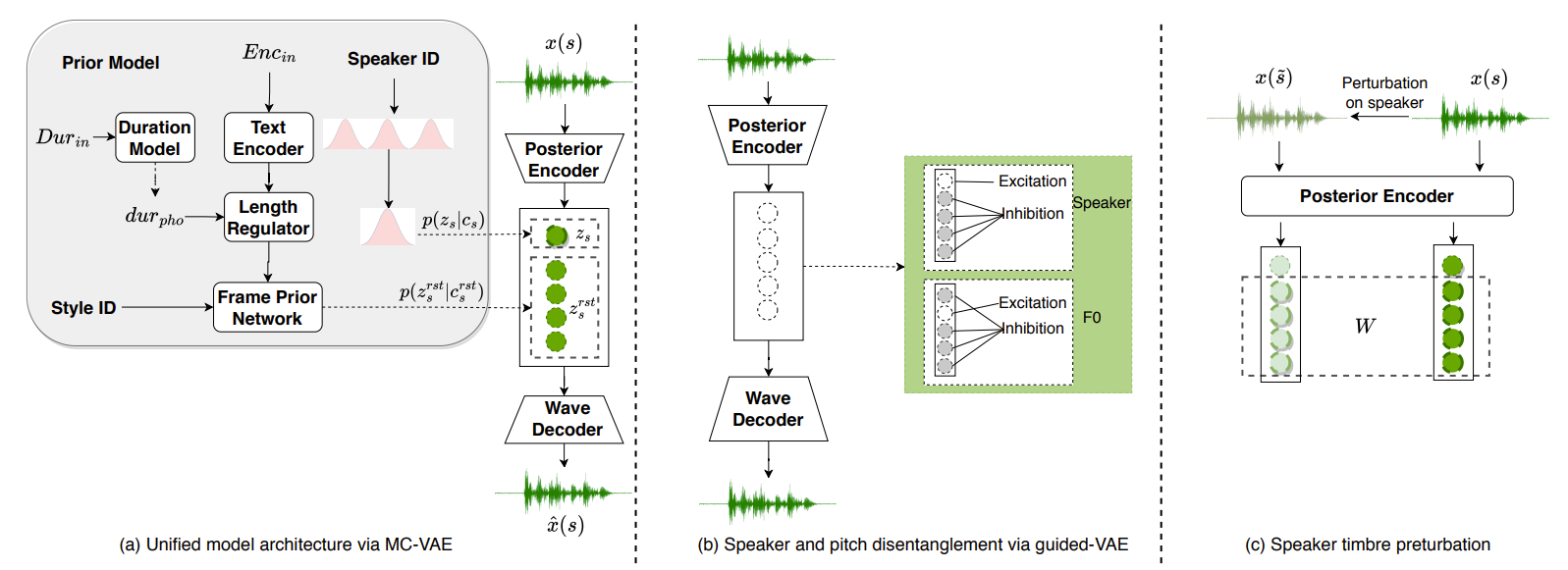
- MC-VAE for Voice Generation
- End-to-End 모델을 위해 VITS의 CVAE를 활용하여 latent variable로부터 waveform을 생성
- VAE로부터 학습된 latent variable을 더 쉽게 해석할 수 있도록 2개의 sub-space로 분리
- Audio signal을 speaker timbre와 나머지 attribute에 대한 두 가지의 독립적인 attribute로 분리함
- Sub-space 분리를 위해 Multi-Conditional Variational AutoEncoder (MC-VAE)를 제안
- VAE encoder는 주어진 input waveform $x$에 대한 latent 분포 $q(z|x)$를 학습함
- 이때 MC-VAE는 latent $z$를 2개의 독립적인 sub-space $z = (z_{s}, z_{s}^{rst})$로 분리
- $z_{s}$는 speaker sub-space만을 정의함
- $z_{s}^{rst}$는 linguistic content나 style 같은 waveform의 나머지 정보를 나타냄 - $z_{s}$와 $z_{s}^{rst}$를 독립으로 만들기 위해, 2개의 독립 condition $c=(c_{s}, c_{s}^{rst})$를 활용하여 sub-space를 제한
- $c_{s}$는 $z_{s}$ 모델링을 위한 categorical speaker label (speaker ID)
- $c_{s}^{rst}$는 $z_{s}^{rst}$ 모델링을 위한 frame-level speaker-independent prior network에서 생성된 나머지 정보
- Conditional Gaussian 분포 $p(z_{s}|c_{s}) = N(\mu_{c_{s}}, \sigma_{c_{s}})$를 따르는 speaker의 prior 분포를 정의하자
- 이때, $\mu_{c_{s}}, \sigma_{c_{s}}$는 각각 speaker ID에 의해 결정되는 prior 평균과 분산
- Audio의 나머지 정보 $z_{s}^{rst}$는 unified textual feature와 style embedding인 $c_{s}^{rst}$로부터 근사될 수 있음
- 독립 condtion $c = (c_{s}, c_{s}^{rst})$, 독립 latent variable $z = (z_{s}, z_{s}^{rst})$와 결합 확률 분포의 조건부 독립 property에 의해 MC-VAE의 variational lower bound는:
$ELBO (p,q;x,c) = \mathbb{E}_{q(z|x)} \left [ log \, p(x|z) - log \, \frac{q(z|x)}{p(z|c)} \right ]$
$= \mathbb{E}_{q(z|x)} [log \, p(x|z)] - \mathbb{E}_{q(z_{s}, z_{r}|x)} \left [ log \, \frac{q(z_{s}, z_{s}^{rst}|x)} {p(z_{s}, z_{s}^{rst}|c)} \right ]$
$= \mathbb{E}_{q(z|x)} [log \, p(x|z)] - \mathbb{E}_{q(z_{s}|x)q(z_{s}^{rst}|x)} \left [ log \, \frac { q(z_{s}|x) q(z_{s}^{rst}|x) } { p(z_{s}|c_{s}) p(z_{s}^{rst}|c_{s}^{rst}) } \right ]$
$= \mathbb{E}_{q(z|x)} [log \, p(x|z)] - KL (q(z_{s}|x) || p(z_{s} |c_{s})) - KL (q(z_{s}^{rst}|x) || p(z_{s}^{rst} | c_{s}^{rst}))$
- 첫 번째 항은 reconstruction loss $\mathcal{L}_{rec}$
- 두 번째, 세 번째 항은 각각 $\mathcal{L}_{kl}^{z_{s}}, \mathcal{L}_{kl}^{z_{s}^{rst}}$로 표현되는 KL divergence - Ground-truth waveform $x$의 mel-spectrogram $mel_{x}$와 frequency domain에서 예측된 waveform $\hat{x}$의 $mel_{\hat{x}}$ 간의 $L_{1}$ loss를 사용하여 $x$를 reconstruct 하면:
$\mathcal{L}_{rec} = ||mel_{x} - mel_{\hat{x}}||_{1}$ - $\mathcal{L}_{kl}^{z_{s}}$는 근사 분포 $q(z_{s}|x)$를 통해 실제 분포 $p(z_{s}|c_{s}) \sim N(\mu_{c_{s}}, \sigma_{c_{s}})$를 추정하는 reverse-KL divergence
- Reverse-KL divergence는 근사 분포 $q(z_{s}|x)$가 정확한 speaker를 찾고 정확하게 모방할 수 있도록 하는 objective mode seeking을 가능하게 함 - $\mathcal{L}_{kl}^{z_{s}^{rst}}$는 근사 prior 분포 $p(z_{s}^{rst}|c_{s}^{rst})$를 통해 posterior 분포 $q(z_{s}^{rst}|x)$를 추정하는 forward-KL divergence
- Timbre-independetn 나머지 정보를 학습할 수 있는 mode covering instance - Timbre는 시간이 지나도 거의 invariant 하기 때문에, speaker 분포의 분산은 상대적으로 작아야 함
- 따라서, speaker ID $c_{s}$를 $\mu_{c_{s}}$로, $\sigma_{c_{s}}$를 0.01로 설정
- 작은 분산은 speaker를 Gaussian 분포로 구별하는데 도움을 줌
- Supervised Guided-VAE for Disentanglement
- Speaker timbre를 latent variable $z$로부터 disentangle 하기 위해 supervised guided-VAE (GVAE)를 활용
- Waveform으로부터 disentangle 되는 attribute $f$를 위해, GVAE는 poseterior encoder의 latent variable을 $z = (z_{f}, z_{f}^{rst})$로 정의
- $z_{f}$ : 해당 attribute를 결정하는 scalar variable, $z_{f}^{rst}$ : 나머지 latent variable - GVAE의 objective는 adversarial excitation과 inhibition method를 포함함:
$\mathcal{L}_{excitation}^{f} = L_{pred}(Pred_{f}(z_{f}), f_{x})$
$\mathcal{L}_{inhibition}^{f} = L_{pred} (Pred_{f} (z_{f}^{rst}), f_{x})$
$\mathcal{L}_{gvae}^{f} = \mathcal{L}_{excitation}^{f} + 1 / \mathcal{L}_{inhibition}^{f}$
- $f_{x}$ : waveform $x$의 attribute $f$에 대한 ground-truth value
- $Pred_{f}$ : latent $z$로부터 attribute value를 예측하는 network
- $L_{pred}$ : 예측값을 최적화하는 loss function - Excitation process는 attribute 정보 $f$를 포함하도록 $z_{f}$를 encourage 하고, inhibition process는 $z_{f}^{rst}$를 $f$에 대해 uninformative 하도록 하는 adversarial term으로 볼 수 있음
- Waveform으로부터 disentangle 되는 attribute $f$를 위해, GVAE는 poseterior encoder의 latent variable을 $z = (z_{f}, z_{f}^{rst})$로 정의
- UniSyn은 GVAE를 활용하여 speaker timbre와 pitch information을 분리함
- 특히 pitch contour는 가창 data 없이 가창 음성을 생성하는데 유용함
- Latent $z$는 각각 $z = (z_{s}, z_{s}^{rst})$와 $z = (z_{p}, z_{p}^{rst})$로 표현될 수 있음
- Speaker disentanglement를 위해 MC-VAE는 shared latent variable $z = (z_{s}, z_{s}^{rst})$를 최적화함
- 이때, cross entropy $L_{pred}$를 통해 speaker identity를 예측 - Pitch disentanglement의 경우, $z = (z_{p}, z_{p}^{rst})$에서 $z_{p}$가 pitch-related information만 포함하도록 최적화됨
- 이때, MSE loss를 활용해 pitch value를 예측
- Speaker disentanglement를 위해 MC-VAE는 shared latent variable $z = (z_{s}, z_{s}^{rst})$를 최적화함
- Speaker Timbre Perturbation
- MC-VAE, GVAE를 사용하면 pitch contour와 timbre를 waveform에서 disentangle 할 수 있음
- Vocal timbre도 수동 label이나 reference audio sampling을 통해 유연하게 제어할 수 있음
- 위의 방법 대신, speaker-independent augmented training data를 얻을 수 있는 information perturbation을 도입
- Formant는 vocal timbre와 높은 관련이 있으므로, formant shifting function $fs$를 활용하여 audio timbre를 무작위 범위에서 distort 함
- Speaker $s$로부터 waveform $x(s)$가 주어지면, 각 training step에서 $fs$ function을 적용하여 $x(\tilde{s})$를 얻음
- 이때 formant만 무작위로 shift 되고 나머지 information을 보존됨 - 이에 따라, MC-VAE의 latent variable $z_{s}^{rst}$와 $z_{\tilde{s}}^{rst}$는 동일한 분포를 따라야 한다고 가정
- 이후 $z_{s}^{rst}, z_{\tilde{s}}^{rst}$ 사이의 Wasserstein distance를 제약조건으로 하여 speaker independent information을 학습:
$\mathcal{L}_{pert} = W (q ( z_{s}^{rst} | x(s) ) || q (z_{\tilde{s}}^{rst} | x(\tilde{s})))$
- $W$ : 두 분포의 Wasserstein distance
- Speaker $s$로부터 waveform $x(s)$가 주어지면, 각 training step에서 $fs$ function을 적용하여 $x(\tilde{s})$를 얻음
- Training
- Audio 품질을 향상하기 위해 학습 과정에서 adversarial training을 적용할 수 있음
- HiFi-GAN의 경우, Multi-Period Discriminator (MPD), Multi-Scale Discriminator (MSD)를 활용하여 서로 다른 scale로 waveform을 판별
- Feature mapping loss $\mathcal{L}_{fm}$은 discriminator의 hidden layer에서 output을 제한하기 위해 적용됨
- 따라서, MC-VAE, GVAE, speaker perturbation, adversarial training을 결합한 최종 loss는:
$\mathcal{L}_{G} = \alpha \mathcal{L}_{rec} + \beta \mathcal{L}_{kl}^{z_{s}} + \gamma \mathcal{L}_{kl}^{z_{s}^{rst}} + \lambda \mathcal{L}_{gvae} + \mu \mathcal{L}_{pert} + \eta \mathcal{L}_{fm} + \theta \mathcal{L}_{adv}(G) + \phi \mathcal{L}_{dur}$
- $\mathcal{L}_{gvae}$ : $\mathcal{L}_{gvae}^{s}, \mathcal{L}_{gvae}^{p}$의 합
- $\mathcal{L}_{dur}$ : log domain에서 예측된 duration과 ground-truth duration 간의 $L_{1}$ loss
- $\mathcal{L}_{adv}(G)$ : generator의 adversarial loss
- Hyperparameter : $\alpha = 60, \beta = 12, \gamma = 1.5, \lambda = 10, \mu = 0.02, \eta = 2, \theta = 2, \phi = 1.5$
- Inference
- UniSyn의 추론은 TTS와 SVS를 모두 지원
- Speaker-related latent variable $z_{s}$는 speaker ID를 condition으로 하는 prior 분포에서 sampling 됨
- Latent $z_{s}^{rst}$는 unified textual feature를 사용하여 prior model에서 encoding 됨
- $z = (z_{s}, z_{s}^{rst})$를 사용해 wave decoder는 target speaker에 대응하는 음성과 가창 음성을 생성함
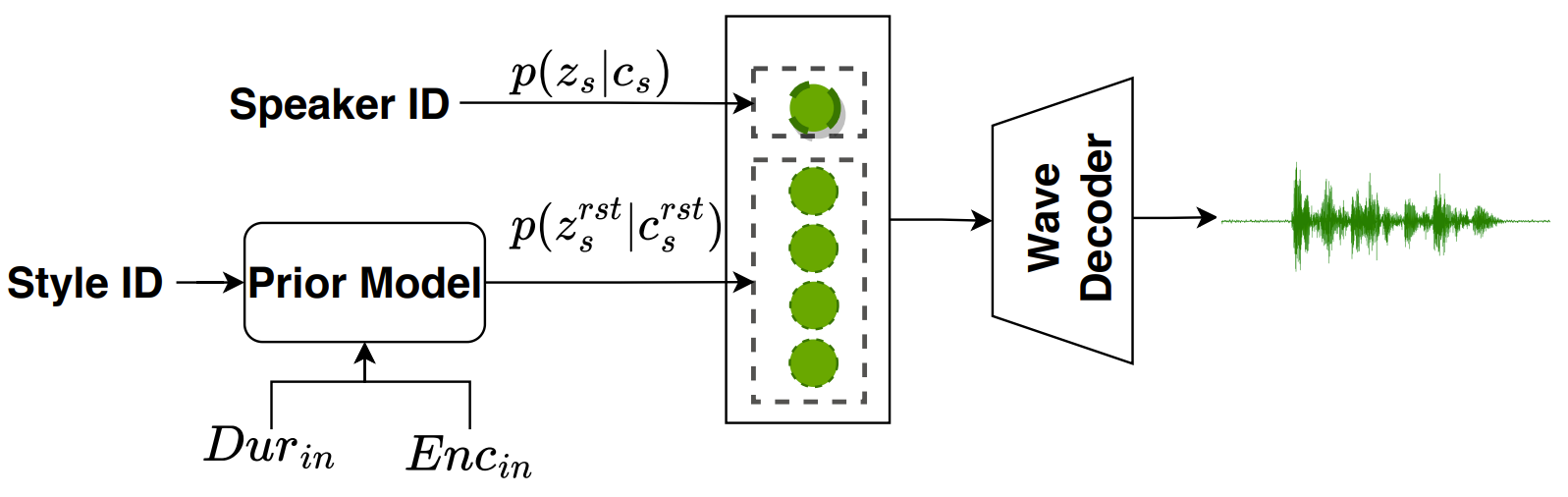
- Model Architecture
- Prior Model
- Prior model은 speaker와 나머지 prior 분포를 제공하는 것을 목표로 함
- Prior model의 구성
- Text Encoder
- Unified textual input을 frame-level representation으로 encoding 하기 위한 length regulator를 포함
- 6개의 Feed-Forward Transformer block으로 구성 - Duration Predictor
- 추론 시 각 phoneme duration을 제공하기 위해 3개의 convolution과 dropout으로 구성 - Frame Prior Network
- Frame-level prior latent variable $z_{s}^{rst}$를 생성하기 위해 6개의 transformer block으로 구성 - $p(z_{s}|c_{s})$를 생성하기 위한 speaker prior procedure
- Text Encoder
- Posterior Encoder
- Linear-spectrogram extractor, WaveNet residual block, linear projection layer로 구성
- Waveform으로부터 posterior 분포 $q(z|x)$의 평균과 분산을 추출하는 역할
- Wave Decoder
- Reparameterization trick을 사용하여 sampling 된 $z \sim p(z|x)$가 주어지면, Wave decoder는 $z$에서 $x$를 reconstruct
- 이때, $z$는 효율적인 학습을 위해 fixed length로 slice 됨 - Audio sample의 resolution과 일치시키기 위해 Multi Receptive field Fusion (MRF) module과 transposed convolution으로 구성됨
- Reparameterization trick을 사용하여 sampling 된 $z \sim p(z|x)$가 주어지면, Wave decoder는 $z$에서 $x$를 reconstruct
3. Experiments
- Settings
- SVS Dataset : Opencpop (Singer-1), internal singing corpus (Singer-2)
- TTS Dataset : Mandarin TTS (Speaker-1), internal Mandarin corpus (Speaker-2)
- Comparisons : VITS, Learn2Sing
- Results
- Evaluation on Text-to-Speech
- 주어진 target speech data에 대해 UniSyn은 naturalness와 similarity 측면에서 VITS와 유사한 성능을 달성
- 학습되지 않은 Singer data에 대해 UniSyn은 VITS 보다 뛰어난 합성 능력을 보임

- Evaluation on Singing Voice Synthesis
- Singer data에 대해 UniSyn은 naturalness와 similarity 측면에서 다른 모델들과 유사한 성능을 달성
- 학습되지 않은 Speaker data가 주어졌을 때, UniSyn이 가장 우수한 성능을 달성

- Objective Evaluation
- 가창 음성의 경우 pitch가 중요하므로 합성된 가창 음성의 pitch accuracy를 측정 및 비교
- UniSyn이 가장 낮은 RMSE와 Corr (Pearson Correlation)을 달성하여 실제 가창 음성과 비슷한 수준을 보임

- Ablation Study
- Perturbation이나 GVAE의 제거는 합성 품질에 크게 영향을 미치지 않음
- 제안된 MC-VAE 만으로도 충분히 효과적으로 음성 합성이 가능함을 의미 - Timbre perturbation은 speaker similarity에 영향을 주고, GVAE는 naturalness에 더 영향을 줌
- Perturbation이나 GVAE의 제거는 합성 품질에 크게 영향을 미치지 않음

반응형
'Paper > SVS' 카테고리의 다른 글
댓글