

티스토리 뷰
Paper/TTS
[Paper 리뷰] Mixer-TTS: Non-autoregressive, Fast and Compact Text-to-Speech Model Conditioned on Language Model Embeddings
feVeRin 2024. 2. 26. 10:08반응형
Mixer-TTS: Non-autoregressive, Fast and Compact Text-to-Speech Model Conditioned on Language Model Embeddings
- Mel-spectrogram generation에서는 non-autoregressive 모델이 유용함
- Mixer-TTS
- MLP-Mixer architecture를 기반으로 pitch/duration predictor를 활용
- Pre-trained language model의 token embedding을 추가적으로 도입하여 Mixer-TTS를 extend
- 논문 (ICASSP 2022) : Paper Link
1. Introduction
- Text-to-Speech (TTS)에서는 속도 향상을 위해서는 non-autoregressive 모델을 활용해야 함
- 대표적으로 FastPitch는 Tacotron2보다 60배 빠른 mel-spectrogram 생성이 가능
- 이때 word skipping, repeating을 제거하는 duration predictor의 도입으로 TTS 모델의 robustness는 크게 향상됨 - Duration predictor를 포함하는 TTS 모델은 external ground-truth alignment를 통한 supervised 방식으로 학습됨
- TalkNet의 경우 auxiliary ASR 모델을 사용하고, FastSpeech는 teacher TTS 모델을 활용
- 이와 달리 Glow-TTS는 unsupervised alignment 방식을 도입하여 TTS pipeline을 크게 단순화 - 추가적으로 non-autoregressive TTS 품질을 향상하기 위해 다양한 방식을 고려할 수 있음
- FastPitch는 fundamental frequency $F0$에 대한 pitch predictor를 도입
- Pre-trained BERT와 같은 Language Model (LM)을 input representation으로 활용하여 TTS 모델을 augment 가능
- 특히 text embedding에는 각 word에 대한 importance가 포함되어 있어 prosody와 pronunciation을 크게 향상 가능
- 대표적으로 FastPitch는 Tacotron2보다 60배 빠른 mel-spectrogram 생성이 가능
-> 그래서 LM의 token embedding을 활용하는 non-autoregressive TTS 모델인 Mixer-TTS를 제안
- Mixer-TTS
- MLP-Mixer architecture를 기반으로 unsupervised alignment framework로 학습된 explicit duration predictor를 도입
- 이때 생성된 음성의 prosody를 개선하기 위해 2가지 방법을 결합
- Explicit pitch predictor를 적용한 basic Mixer-TTS를 구성
- External pre-trained LM의 token embedding을 추가하여 Mixer-TTS를 extend
- Token embedding을 사용하는 것은 BERT output을 추론하는 것보다 훨씬 저렴하다는 장점이 있음
< Overall of Mixer-TTS >
- MLP-Mixer architecture를 기반으로 pitch/duration predictor를 활용
- Pre-trained language model의 token embedding을 추가적으로 도입하여 Mixer-TTS를 extend
- 결과적으로 기존보다 빠른 추론 속도와 개선된 음성 품질을 달성
2. Model Architecture
- Mixer-TTS의 pipeline은:
- Text를 encoding 하고 separate module의 audio feature를 통해 align 하여 ground-truth duration을 얻음
- 이후 character-/phoneme-level pitch 값을 계산하고 length regulator module에 제공하여, 해당 duration과 함께 각 characeter/phoneme을 expand 함
- Decoder는 encoded representation으로부터 mel-spectrogram을 생성
- Basic Mixer-TTS는 FastPitch를 기반으로 함
- 이때 아래 2가지 수정 사항을 반영
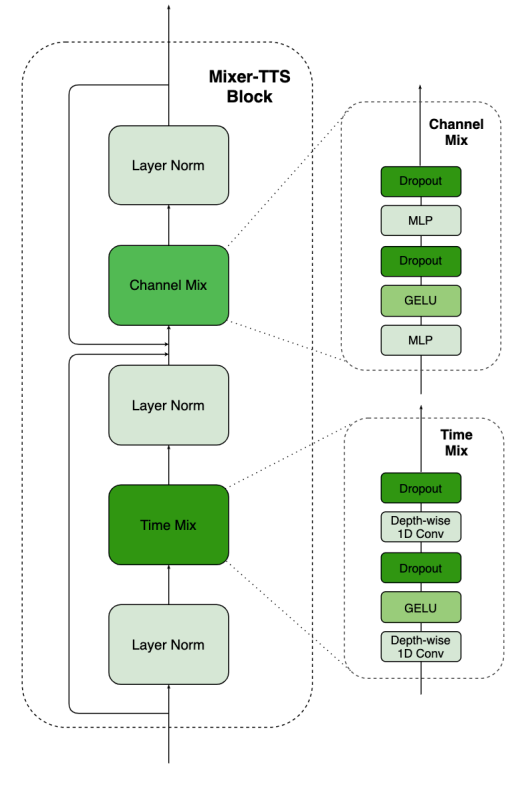
- Encoder와 Decoder의 모든 feed-forward transformer block을 Mixer-TTS block으로 대체
- Duration predictor를 training 하기 위해 unsupervised speech-to-text alignment framework를 적용
- Extended Mixer-TTS의 경우, pre-trained LM의 embedding에 대한 conditioning을 추가로 활용
- Mixer-TTS의 학습은 mel-spectrogram, duration, pitch에 대한 ground-truth와 예측값 사이의 aligner loss와 mean-squared error를 결합한 loss function을 사용:
$L=L_{aligner}+L_{mel}+0.1 \cdot L_{durs} +0.1 \cdot L_{pitch}$
- 이때 아래 2가지 수정 사항을 반영

- Mixer-TTS Block
- MLP-Mixer architecture는 multi-layer perceptron (MLP)을 활용함
- 이때 MLP-Mixer는 input에 대해 2가지 key action을 수행함:
- Per-location feature에 대한 mixing
- Spatial information에 대한 mixing
- Per-location feature에 대한 mixing
- 위 두 operation 모두 MLP layer stack으로 구성됨
- 첫 번째 MLP layer는 expansion factor 만큼 channel 수를 늘리고, 두 번째 MLP layer는 channel을 기존 크기로 줄임
-> BUT, 이러한 방식은 input size가 모든 dimension에 대해 fix 된 경우에만 가능함 - Input dimension이 dynamic size를 가지는 TTS에서의 적용을 위해,
- Time-mixing을 사용하여 MLP를 depth-wise 1D convolution으로 대체
- 그 외의 layer noramlization, residual connection 등의 기존 MLP-Mixer 구조는 그대로 유지됨 - Mini-batch 학습/추론 시에 batch의 sequence가 가장 긴 sequence와 match 되도록 padding 하기 위해, MLP와 depth-wise 1D convolution 다음에 sequence masking을 수행
- 이때 MLP-Mixer는 input에 대해 2가지 key action을 수행함:
- Encoder는
- $11$에서 $21$까지 lineary growing 하는 time-mix convolution kernel을 가지는 $6$-stacked Mixer-TTS block으로 구성됨
- 비슷하게 Decoder는 kernel size가 $15$에서 $31$로 증가하는 $9$-stacked Mixer-TTS block으로 구성됨
- 모든 block에 대해 feature dimension은 $384$, channel-mix expansion은 $4$를 사용
- 추가적으로 각 block에 $0.15$의 dropout이 적용됨
- Speech-to-Text Alignment Framework
- Duration prediction을 활용하는 대부분의 non-autoregressive TTS 모델은 external source에서 추출된 duration에 의존함
- Mixer-TTS는 FastPitch에서 제안된 unsupervised alignment algorithm을 적용하여 decoder와 함께 speech-to-text alignment를 jointly training 함
- 해당 aligner는 1D convolution을 사용하여 text와 mel-spectrogram을 encoding 하고, 동일한 dimensionality의 space에 projection 함 - Soft alignment는 encoded text와 mel-representation의 pairwise $L2$ distance를 사용하여 계산된 다음, Connectionist Temporal Classification (CTC) loss를 통해 해당 alignment를 학습함
- 이때 monotonic binarized alignment를 얻기 위해 Viterbi algorithm을 사용하여 가장 가능성이 높은 monotonic path를 탐색
- Mixer-TTS는 FastPitch에서 제안된 unsupervised alignment algorithm을 적용하여 decoder와 함께 speech-to-text alignment를 jointly training 함
- Extended Mixer-TTS
- Extended 모델은 external LM의 token embedding을 활용함
- 이를 위해 large English text corpus에 대해 pre-train 된 ALBERT를 사용함
- LM tokenization은 유지하고 input token에 frozen embedding을 도입
- 이때 external LM의 original / tokenized text length는 서로 다른 tokenizer에서 생성되므로 동일하지 않음 - 두 sequence를 align 하기 위해, LM embedding $lm_{emb}$와 encoder output $t_{e}$에 적용된 single head self-attention block을 사용
- 이를 통해 basic text embedding length를 유지하면서 해당 feature를 mixing
- Self-attention aligning을 위한 text feature는 positional embedding layer 다음의 convolution layer로부터 추출됨
3. Experiments
- Settings
- Dataset : LJSpeech
- Comparisons : FastPitch, Tacotron2, TalkNet2
- Results
- LM Embedding Conditioning and Tokenization
- Mixer-TTS에서 phonetic input representation은 basic 모델보다 뛰어난 성능을 보임
- Extended 모델의 경우, character-based tokenization과 LM embedding 조합이 가장 좋은 성능을 보임

- Speech Quality Evaluation
- 합성 품질 측면에서 basic Mixer-TTS 만으로도 FastPitch와 비슷한 품질을 보임
- Extended Mixer-TTS-X는 가장 우수한 합성 품질을 달성

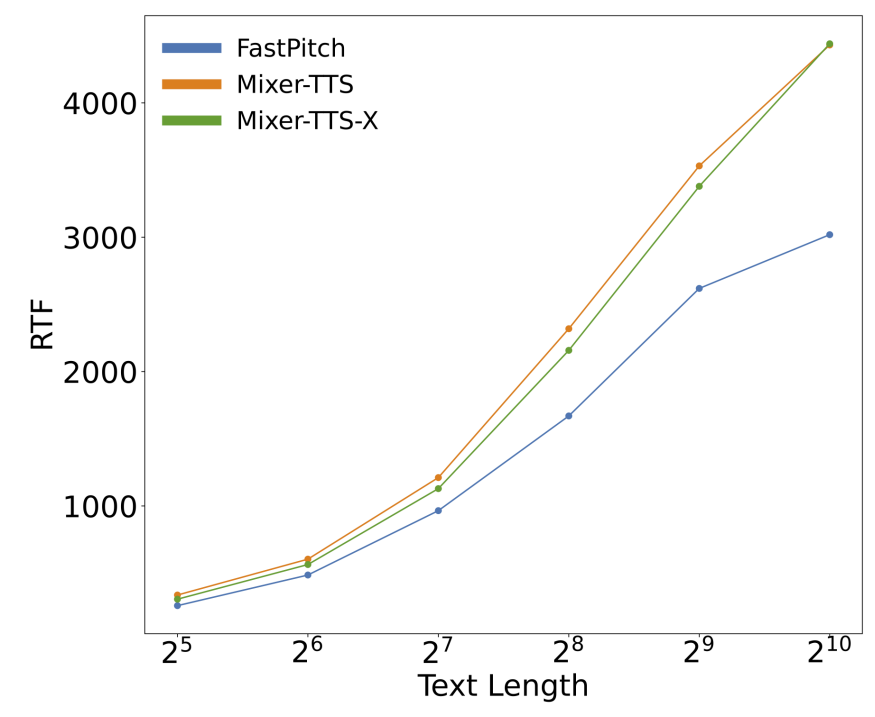
- Inference Performance
- 추론 속도 측면에서 Mixer-TTS는 FastPitch 보다 빠르고, input length가 늘어날수록 뛰어난 scaling을 보임
- Parameter 수 측면에서 Mixer-TTS는 24M을 필요로 하지만, FastPitch는 45M이 필요함
반응형
'Paper > TTS' 카테고리의 다른 글
댓글