

티스토리 뷰
Paper/Vocoder
[Paper 리뷰] MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis
feVeRin 2024. 2. 24. 13:17반응형
MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis
- Generative Adversarial Network (GAN)를 사용하여 안정적이고 고품질의 waveform을 합성할 수 있음
- MelGAN
- Mel-spectrogram inversion을 위해 GAN에 대한 architecture 수정과 간단한 training technique을 도입
- 더 적은 parameter 수와 빠른 추론 속도를 가지는 non-autoregressive 하고 fully convolutional 한 neural vocoder
- Conditional sequence 합성을 위한 general purpose discriminator 설계로 확장 가능
- 논문 (NeurIPS 2019) : Paper Link
1. Introduction
- Raw audio를 모델링하는 것은 data의 high temporal resolution과 short/long-term dependency로 인해 어려움
- 따라서 일반적으로 raw temporal audio를 직접 모델링하는 대신, raw temporal signal에서 계산되는 lower-resolution representation을 활용함
- 해당 representation은 audio로 쉽게 inversion back 될 수 있어야 함
- 음성 작업에서는 mel-spectrogram과 aligned linguistic feature가 대표적인 intermediate representation - 이때 audio 모델링 과정은 주로 two-stage로 수행됨
- 첫 번째 stage는 input으로 주어진 text에 대해 해당 intermediate representation을 모델링
- 두 번째 stage는 intermediate representation을 audio로 변환
- 따라서 일반적으로 raw temporal audio를 직접 모델링하는 대신, raw temporal signal에서 계산되는 lower-resolution representation을 활용함
- Intermediate representation을 audio로 변환하는 vocoder는 크게 pure signal processing, autoregressive, non-autoregressive 방식으로 나눌 수 있음
- Pure Signal Processing
- 대표적으로 Griffin-Lim을 사용하여 STFT sequence를 temporal signal로 decoding 함
- WORLD vocoder는 mel-spectrogram과 유사한 mel-spectrogram-like feature를 활용하여 음성 모델링을 수행
- Char2Wav와 같이 attention-based recurrent network와 결합되어 text-to-speech (TTS) 작업으로 확장 가능 - BUT, pure signal processing은 intermediate feature를 audio로 mapping 할 때 noticable artifact가 발생함
- Autoregressive Neural-network-based Model
- WaveNet은 raw audio와 temporally align 된 linguistic feature를 활용하여 음성 합성을 수행하는 fully-convolutional autoregressive sequence 모델
- SampleRNN은 multi-scale recurrent network를 사용하여 unconditional waveform을 합성
- BUT, autoregressive 방식은 추론 시 audio sample을 sequential 하게 생성해야 하므로 느리고 비효율적임
- Non-autoregressive Model
- Non-autoregressive 모델은 parallelizable 하기 때문에 autoregressive 방식보다 빠른 추론 속도를 가짐
- 이를 위해 Parallel WaveNet, ClariNet은 trained autoregressive decoder를 student 모델로 distil 함
- WaveGlow는 flow-based generation을 도입 - BUT, non-autoregressive 모델은 빠른 추론 속도를 달성할 수는 있지만 모델 size로 인해 memory 제약 환경에서는 사용하기 어려움
- Non-autoregressive 모델은 parallelizable 하기 때문에 autoregressive 방식보다 빠른 추론 속도를 가짐
- GANs for Audio
- GAN을 활용하여 audio 모델링을 수행할 수도 있음
- 특히 GAN은 computer vision 분야에서 큰 성공을 보임 - BUT, 지금까지 제시된 GAN 기반의 audio 모델링 방식들은 만족할만한 성능을 달성하지 못함
- GAN을 활용하여 audio 모델링을 수행할 수도 있음
- Pure Signal Processing
-> 그래서 GAN 기반 audio 모델링의 성능을 크게 개선한 neural vocoder인 MelGAN을 제안
- MelGAN
- GAN을 통한 audio waveform 생성을 위해 non-autoregressive feed-forward convolution architecture를 도입
- 추가적인 distillation이나 perceptual loss 없이 고품질의 음성 합성을 수행
- Music translation, TTS 등 다양한 작업으로 MelGAN을 확장
< Overall of MelGAN >
- Mel-spectrogram inversion을 위해 GAN에 대한 non-autoregressive convolution architecture를 도입하고 간단한 training technique을 도입
- 결과적으로 더 적은 parameter 수와 빠른 추론 속도를 가지면서도 고품질의 합성이 가능

2. MelGAN
- Mel-spectrogram inversion을 위해 generator, discriminator architecture를 활용

- Generator
- Architecture
- MelGAN의 Generator는 mel-sepctrogram $s$를 input으로 하여 raw waveform $x$를 output 하는 fully convolutional feed-forward network
- 이때 mel-spectrogram은 256배 더 낮은 temporal resolution을 가지기 때문에 input sequence를 upsampling 하기 위해 transposed convolution layer의 stack을 사용
- 각 transposed convolution layer 다음에는 dilated convolution이 있는 residual block의 stack이 사용됨
- 이때 generator는 기존과 달리 global noise vector를 input으로 사용하지 않음 - Generator에 additional noise가 제공되더라도 perceptual difference는 크게 나타나지 않음
- 이는 $s\rightarrow x$의 inversion은 $s$가 $x$의 lossy-compression이므로 one-to-many mapping을 포함하므로 counter-intuitive 한 결과라고 할 수 있음
- BUT, conditioning information이 상당히 strong 한 경우, 이러한 noise input은 중요하지 않음
- MelGAN의 Generator는 mel-sepctrogram $s$를 input으로 하여 raw waveform $x$를 output 하는 fully convolutional feed-forward network
- Induced Receptive Field
- CNN 기반의 generator에는 induced receptive field 간의 high overlap으로 인해 spatially close 한 pixel이 correlate 되어 있는 inductive bias가 존재
- 따라서 audio timestep 사이에 long-range correlation이 있다는 inductive bias를 활용할 수 있도록 generator architecture를 설계해야 함
- 이를 위해, 각 upsampling layer 다음에 dilation이 포함된 residual block을 추가하여 각 subsequent layer의 temporally far output activation이 상당한 overlapping input을 가지도록 함- Dilated convolution layer의 receptive field는 layer 수에 따라 exponentially increase 하게 됨 - 따라서 이를 generator에 incorporate 하면 각 output timestep의 induced receptive field는 효율적으로 증가됨
- 멀리 떨어진 timestep의 induced receptive field에서 large overlap은 더 나은 long-range correlation으로 이어짐
- Checkerboard Artifacts
- Transposed convolution layer의 kernel size와 stride를 신중하게 선택하지 않으면, checkerboard pattern을 생성
- 이러한 pattern은 audible high frequency hissing noise로 이어짐 - 따라서 kernel size를 stride의 배수로 선택하여 transposed convolution layer를 구성
- Stack의 receptive field가 kernel size를 branching factor로 사용하여 fully-balanced, symmetric tree처럼 보이도록 함
- Transposed convolution layer의 kernel size와 stride를 신중하게 선택하지 않으면, checkerboard pattern을 생성
- Normalization Technique
- Normalization 역시 generator의 sample 품질을 향상하는데 중요함
- 이미지 생성에는 일반적으로 instance normalization을 사용하지만, audio의 경우 instance normalization은 중요한 pitch information을 wash 하여 metallic sound를 만들어냄
- Weight Normalization은 discriminator의 capacity를 limit 하거나 activation을 normalize 하지 않으므로 가장 적합
- 더 나은 training을 위해, weight vector의 scale을 direction에서 decoupling 하여 weight matrix를 reparameterize 함 - 따라서 이를 기반으로 generator의 모든 layer에서 weight normalization을 수행
- Discriminator
- Multi-Scale Architecture
- 동일한 network 구조를 가지지만 서로 다른 audio scale에서 동작하는 3개의 discriminator $D_{1}, D_{2},D_{3}$를 가지는 multi-scale architecture를 채택
- $D_{1}$은 raw audio scale에서 동작하고, $D_{2}, D_{3}$는 각각 2배, 4배로 downsampling 된 raw audio에서 동작
- 이때 downsampling은 kernel size 4의 strided avearge pooling으로 수행됨 - Multi-scale discriminator는 audio가 다양한 level의 구조를 가지고 있다는 점을 활용
- 각 구조에는 각 discriminator가 audio의 다양한 frequency range에 대한 feature를 학습할 수 있는 inductive bias가 존재하기 때문
- i.g.) Downsample audio에 대한 discriminator는 high-frequency component에 access 할 수 없으므로, low-frequency component 만으로 discriminative feature를 학습하도록 bias 됨
- 동일한 network 구조를 가지지만 서로 다른 audio scale에서 동작하는 3개의 discriminator $D_{1}, D_{2},D_{3}$를 가지는 multi-scale architecture를 채택
- Window-based Objective
- 각 discriminator는 큰 kernel size를 가지는 strided convolution layer로 구성된 Markovian window-based discriminator
- 이때 parameter 수를 작게 유지하면서 더 큰 kernel size를 사용할 수 있도록 grouped convolution을 사용함 - 일반적인 GAN discriminator는 전체 audio sequence의 분포에 대한 classify를 학습하지만, window-based discriminator는 작은 audio chunk 분포 간의 classify를 학습
- Discriminator loss는 매우 큰 overlapping window에 대해 계산되므로 MelGAN은 patch 전체에 대해 coherence를 유지하는 방법을 학습함 - 따라서 window-based discriminator는 essential high-frequency 구조를 capture 하고, 더 빠르면서 적은 수의 parameter를 가지고, variable length audio sequence에 적용 가능함
- Generator와 유사하게 discriminator의 모든 layer에서도 weight normalization이 사용됨
- 각 discriminator는 큰 kernel size를 가지는 strided convolution layer로 구성된 Markovian window-based discriminator
- Training Objective
- GAN을 학습시키기 위해 GAN objective에 대한 hinge loss를 활용:
- 추가적으로 least-square (LSGAN)을 활용하면 hinge loss를 좀 더 개선할 수 있음
(Eq. 1) $\min_{D_{k}}\mathbb{E}_{x}\left[ \min(0,1-D_{k}(x))\right]+\mathbb{E}_{s,z}\left[\min(0,1+D_{k}(G(s,z)))\right], \,\,\, \forall k=1,2,3$
(Eq. 2) $\min_{G}\mathbb{E}_{s,z}\left[ \sum_{k=1,2,3}-D_{k}(G(s,z))\right]$
- $x$ : raw waveform, $s$ : mel-spectrogram과 같은 conditioning information, $z$ : Gaussian noise vector - Feature Matching Loss
- Discriminator의 signal 외에도 feature matching objective를 도입하여 generator를 학습함
- 실제와 합성 audio의 discriminator feature map 간의 $L1$ distance를 최소화
- Discriminator가 실제와 합성 data를 discriminate 하는 feature space를 학습하도록 하는 similarity metric - 이때 raw audio space에서는 어떤 loss도 사용되지 않음
- Audio space에 $L1$ loss를 추가하는 경우, audio 품질을 저하시키는 audible noise가 발생하기 때문 - 따라서 feature matching loss는:
(Eq. 3) $\mathcal{L}_{FM}(G,D_{k})=\mathbb{E}_{x,s\sim p_{data}}\left[ \sum_{i=1}^{T}\frac{1}{N_{i}}|| D_{k}^{(i)}(x)-D_{k}^{(i)}(G(s))||_{1}\right]$
- $D_{k}^{(i)}$ : $k$-th discriminator block의 $i$-th layer feature map, $N_{i}$ : 각 layer의 unit 수
- 이때 모든 discriminator block의 각 intermediate layer에서 feature matching loss를 적용 - 결과적으로 generator에 대한 최종 objective는:
(Eq. 4) $\min_{G}\left(\mathbb{E}_{s,z}\left[ \sum_{k=1,2,3}-D_{k}(G(s,z))\right]+\lambda \sum_{k=1}^{3}\mathcal{L}_{FM}(G,D_{k})\right)$
- $\lambda=10$으로 설정
- Discriminator의 signal 외에도 feature matching objective를 도입하여 generator를 학습함
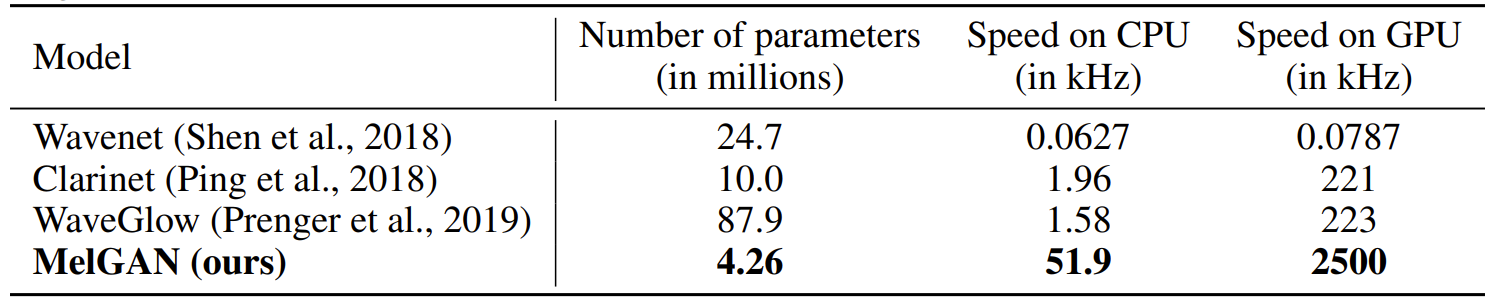
- Number of Parameters and Inference Speed
- MelGAN에 incorporate 된 inductive bias는 기존 모델들보다 parameter 수 측면에서 더 효율적
- 특히 non-autoregressive, fully convolutional 구성으로 인해 MelGAN은 GPU에서 기존 보다 10배 이상 빠르고 CPU에서 25배 이상 빠른 것으로 나타남
3. Experiments
- Settings
- Dataset : LJSpeech, VCTK
- Comparisons : Griffin-Lim, WaveNet, ClariNet, WaveGlow
- Results
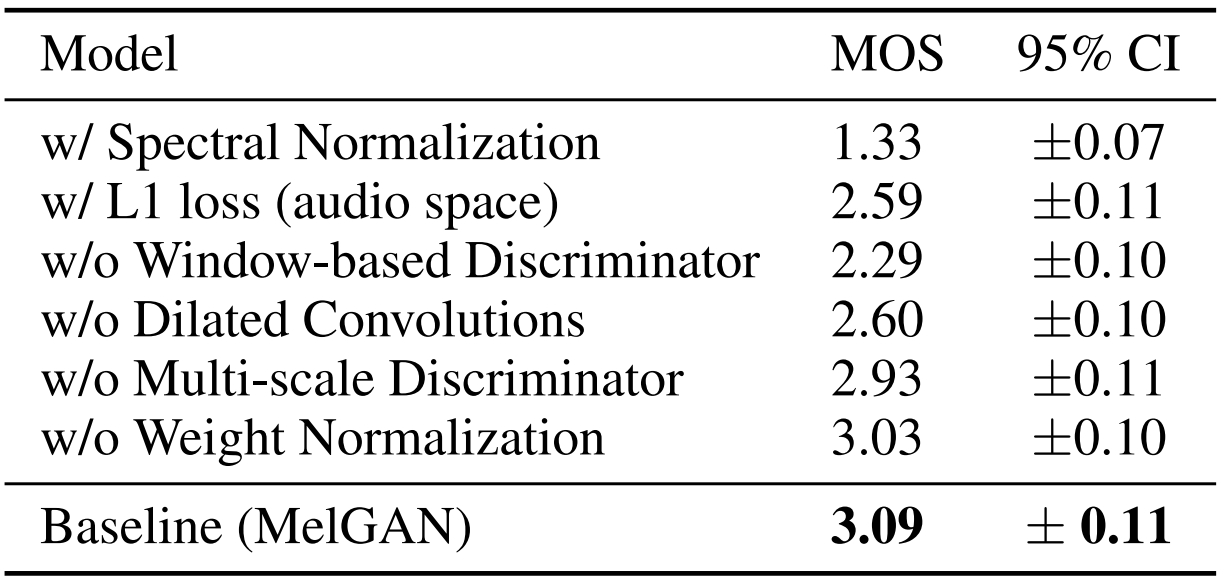
- Ablation Study
- Mel-spectrogram inversion을 위해 reconstruct 된 audio에 대한 evaluation을 수행해 보면
- Generator에서 dilated convolution이 없거나 weight normalization을 제거하는 경우 high-frequency artifact가 발생
- 특히 multi-scale discriminator를 사용하지 않으면 metallic audio가 생성됨 - Spectral normalization을 사용하거나 window-based discriminator loss를 제거하면, sharp high-frequency pattern을 학습하기 어려워지므로, noisy sound가 생성됨
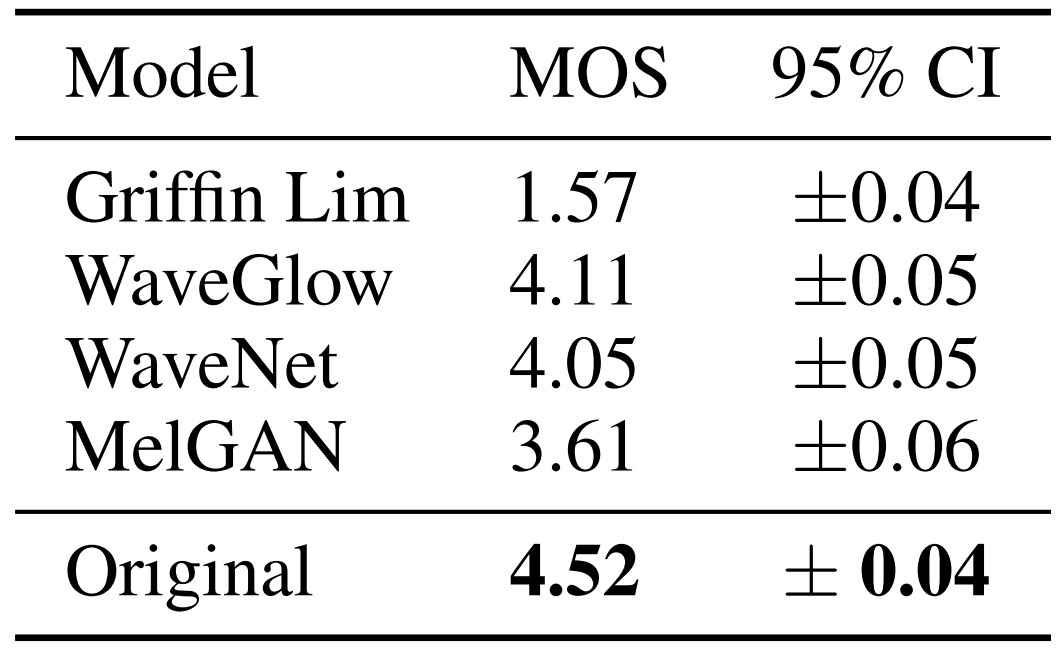
- Benchmarking Competing Models
- MOS 측면에서 기존 모델들과 합성 품질을 비교해 보면, MelGAN이 가장 우수한 성능을 보이는 것으로 나타남
- Generation to Unseen Speakers
- Unseen speaker에 대한 합성 품질을 비교해 보면, 마찬가지로 MelGAN이 가장 우수한 것으로 나타남
- MelGAN은 raw waveform에 대한 mel-spectrogram의 speaker-invariant mapping을 학습할 수 있기 때문

- End-to-End Speech Synthesis
- End-to-End TTS 모델과 MelGAN을 결합하여 합성 품질을 비교
- Tacotron2와 Text2Mel을 기반으로 실험했을 때, MelGAN이 가장 우수한 성능을 보임

- Non-autoregressive Decoder for Music Translation
- 음성 합성 외에 music translation으로 MelGAN을 확장해 보면,
- MelGAN을 사용한 music translation network는 target domain으로 적절한 품질로 music translation을 수행함
- 모델은 GPU에서 1초 길이의 input audio를 변환하는데 160ms를 소모하는데, 이는 기존 보다 2500배 빠른 속도임
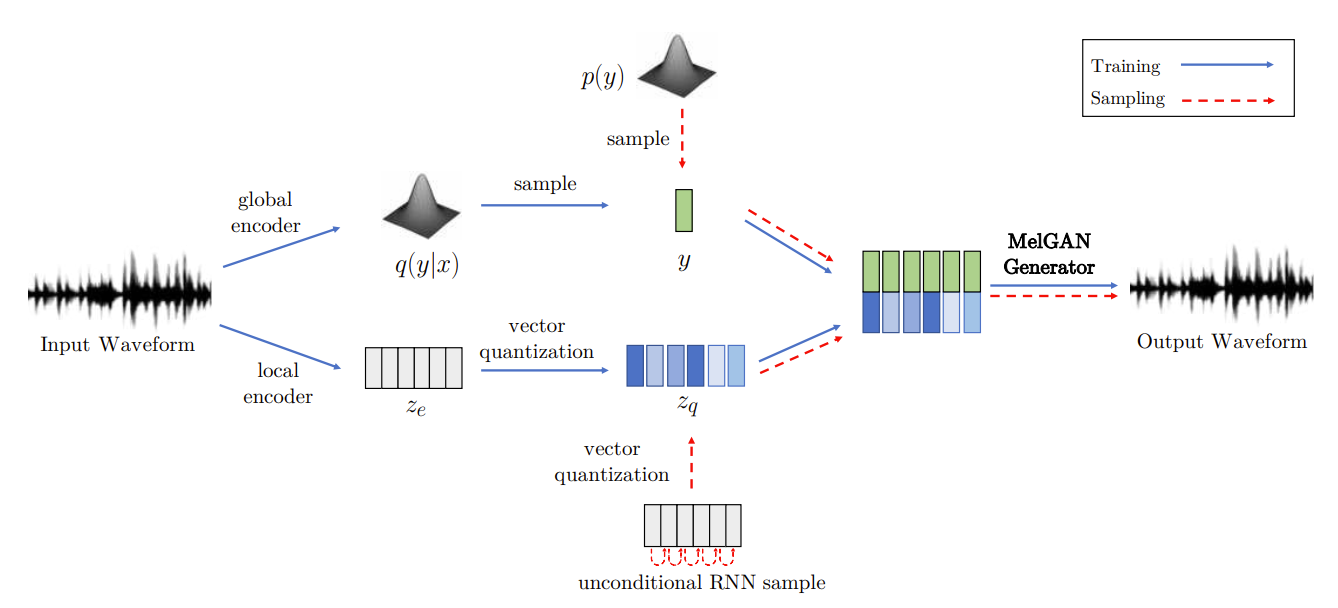
- Non-autoregressive Decoder for VQ-VAE
- 음악 생성을 위한 VQ-VAE에 MelGAN을 적용해 보면, global latent가 reconstruction 품질을 향상하는데 필수적임
- Local encoder를 통해 학습된 discrete latent information이 highly compresse 되기 때문
반응형
'Paper > Vocoder' 카테고리의 다른 글
댓글