
 [Paper 리뷰] BDDM: Bilateral Denoising Diffusion Models for Fast and High-Quality Speech Synthesis
[Paper 리뷰] BDDM: Bilateral Denoising Diffusion Models for Fast and High-Quality Speech Synthesis
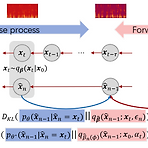
BDDM: Bilateral Denoising Diffusion Models for Fast and High-Quality Speech SynthesisDiffusion model은 우수한 합성 품질을 보이고 있지만 효율적인 sampling의 어려움이 있음Bilateral Denoising Diffusion Model (BDDM)Bilateral modeling objective로 train 할 수 있는 schedule network와 score network를 사용하여 forward/reverse process를 parameterize 하는 bilateral denoising diffusion model제안된 surrogate objective는 기존 surrogate보다 tighter 한 log ma..
 [Paper 리뷰] InstructTTS: Modelling Expressive TTS in Discrete Latent Space with Natural Language Style Prompt
[Paper 리뷰] InstructTTS: Modelling Expressive TTS in Discrete Latent Space with Natural Language Style Prompt
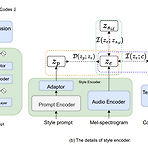
InstructTTS: Modelling Expressive TTS in Discrete Latent Space with Natural Language Style Prompt Expressive Text-to-Speech는 다양한 speech pattern을 반영하는 것을 목표로 하고, 이때 style을 control 하는 style prompt로 natural language를 활용할 수 있음 InstructTTS Self-supervised learning과 cross-modal metric learning을 활용하고 robust sentence embedding model을 얻기 위해 3-stage training을 제시 일반적인 mel-spectrogram 대신 vector-quantized ac..
 [Paper 리뷰] SuperCodec: A Neural Speech Codec with Selective Back-Projection Network
[Paper 리뷰] SuperCodec: A Neural Speech Codec with Selective Back-Projection Network
SuperCodec: A Neural Speech Codec with Selective Back-Projection Network Neural speech coding은 우수한 compression 성능을 보여주지만, low bitrate에서 fine detail reconstruction의 한계가 있음 SuperCodec Low bitrate에서도 뛰어난 성능을 달성하기 위해 selective feature fusion을 가지는 back-projection method를 활용한 neural speech codec 특히 encoder, decoder의 standard up-/down-sampling layer를 대체하기 위해 Selective Up-sampling Back Projection, Selec..
 [Paper 리뷰] PromptStyle: Controllable Style Transfer for Text-to-Speech with Natural Language Descriptions
[Paper 리뷰] PromptStyle: Controllable Style Transfer for Text-to-Speech with Natural Language Descriptions
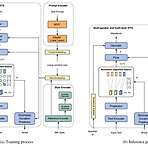
PromptStyle: Controllable Style Transfer for Text-to-Speech with Natural Language Descriptions Text-to-Speech에서 style control을 위해서는 개별적인 style category가 있는 expressive speech recording이 필요함 BUT, 실적용에서는 target style에 대한 referecne speech 없이 desired style에 대한 text description을 활용하는 것이 더 적합하다고 볼 수 있음 PromptStyle Text prompt-guided cross-speaker style transfer를 목표로 VITS와 cross-modal style encoder를 활용 ..
 [Paper 리뷰] PromptTTS++: Controlling Speaker Identity in Prompt-based Text-to-Speech using Natural Language Descriptions
[Paper 리뷰] PromptTTS++: Controlling Speaker Identity in Prompt-based Text-to-Speech using Natural Language Descriptions
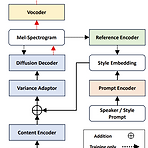
PromptTTS++: Controlling Speaker Identity in Prompt-based Text-to-Speech using Natural Language Descriptions Natural language description을 사용하여 speaker identity를 control 하는 prompt-based text-to-speech를 수행할 수 있음 PromptTTS++ Speaker identity를 control 하기 위해, speaking style과 independent 하도록 설계된 voice characteristic을 설명하는 speaker prompt를 도입 Diffusion-based acoustic model을 사용하여 다양한 speaker factor를 모델링..
 [Paper 리뷰] FeatherWave: An Efficient High-Fidelity Neural Vocoder with Multi-Band Linear Prediction
[Paper 리뷰] FeatherWave: An Efficient High-Fidelity Neural Vocoder with Multi-Band Linear Prediction
FeatherWave: An Efficient High-Fidelity Neural Vocoder with Multi-Band Linear Prediction Multi-band signal processing과 linear predictive coding을 결합하여 neural vocoder를 구성할 수 있음 FeatherWave LPCNet에 multi-band linear predictive coding을 결합한 모델 Multi-band method를 활용하여 여러 sample을 병렬적으로 빠르게 합성할 수 있도록 함 논문 (INTERSPEECH 2020) : Paper Link 1. Introduction Text-to-Speech (TTS)에서 vocoder는 human-like 음성을 합성하는..