
 [Paper 리뷰] Period VITS: Variational Inference with Explicit Pitch Modeling for End-to-End Emotional Speech Synthesis
[Paper 리뷰] Period VITS: Variational Inference with Explicit Pitch Modeling for End-to-End Emotional Speech Synthesis
Period VITS: Variational Inference with Explicit Pitch Modeling for End-to-End Emotional Speech Synthesis End-to-End 방식은 acoustic model과 vocoder를 개별적으로 training 하는 cascade 방식보다 더 우수한 text-to-speech 성능을 달성할 수 있음 - BUT, dataset에 다양한 prosody나 emotional attribute가 포함되어 있는 경우 audible artifact와 unstable pitch를 생성하는 경우가 많음 Period VITS Unstable pitch 문제를 해결하기 위해 explicit periodicity generator를 사용하는 end-..
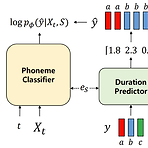 [Paper 리뷰] Guided-TTS: A Diffusion Model for Text-to-Speech via Classifier Guidance
[Paper 리뷰] Guided-TTS: A Diffusion Model for Text-to-Speech via Classifier Guidance
Guided-TTS: A Diffusion Model for Text-to-Speech via Classifier Guidance Classifier guidance를 활용하여 target speaker의 transcript 없이 고품질의 text-to-speech를 수행할 수 있음 Guided-TTS Classifier guidance를 위해 개별적으로 train된 phoneme classifier와 unconditional diffusion model을 결합 Unconditional diffusion model은 untranscribed speech data로부터 context 없이 음성을 생성하는 방법을 학습 Phoneme classifier를 사용하여 diffusion model의 generati..
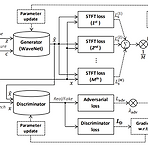 [Paper 리뷰] Parallel WaveGAN: A Fast Waveform Generation Model Based on Generative Adversarial Networks with Multi-Resolution Spectrogram
[Paper 리뷰] Parallel WaveGAN: A Fast Waveform Generation Model Based on Generative Adversarial Networks with Multi-Resolution Spectrogram
Parallel WaveGAN: A Fast Waveform Generation Model Based on Generative Adversarial Networks with Multi-Resolution Spectrogram Generative Adversarial Network를 사용하여 distillation 과정이 필요 없는 vocoder를 구성할 수 있음 Parallel WaveGAN Waveform의 time-frequency 분포를 효과적으로 capture 하는 multi-resolution spectrogram loss와 adversarial loss를 jointly optimize 하여 non-autoregressive WaveNet을 training 함 기존의 teacher-student..
 [Paper 리뷰] Textually Pretrained Speech Language Models
[Paper 리뷰] Textually Pretrained Speech Language Models
Textually Pretrained Speech Language Models Speech language model은 textual supervision 없이 acoustic data 만을 처리하고 생성함 Textually Warm Initialized Speech Transformer (TWIST) Pretrained textual languaga model의 warm-start를 사용하여 speech language model을 training Parameter 수와 training data 측면에서 가장 큰 speech language model을 제시 논문 (NeurIPS 2023) : Paper Link 1. Introduction 음성에는 단순한 textual context 이상의 정보가 포..
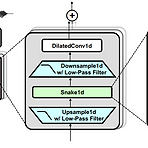 [Paper 리뷰] BigVGAN: A Universal Neural Vocoder with Large-Scale Training
[Paper 리뷰] BigVGAN: A Universal Neural Vocoder with Large-Scale Training
BigVGAN: A Universal Neural Vocoder with Large-Scale TrainingGenerative Adversarial Network (GAN) 기반의 vocoder는 우수한 품질을 보이고 있지만, 다양한 recording 환경과 speaker에 대한 audio를 합성하는 것에는 어려움이 있음BigVGANFine-tuning 없이 다양한 out-of-distribution scenario에 generalize 할 수 있는 universal vocoderGAN generator에 periodic activation function과 anti-aliased representation을 도입하여 inductive bias를 제공하고 합성 성능을 향상결과적으로 over-regula..
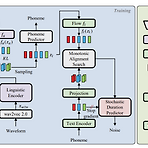 [Paper 리뷰] HierSpeech: Bridging the Gap between Text and Speech by Hierarchical Variational Inference using Self-Supervised Representations for Speech Synthesis
[Paper 리뷰] HierSpeech: Bridging the Gap between Text and Speech by Hierarchical Variational Inference using Self-Supervised Representations for Speech Synthesis
HierSpeech: Bridging the Gap between Text and Speech by Hierarchical Variational Inference using Self-Supervised Representations for Speech Synthesis Text로부터 raw waveform을 직접 생성하는 end-to-end pipeline은 고품질의 합성이 가능하지만, mispronunciation이나 over-smoothing 문제가 종종 발생함 HierSpeech 고품질의 end-to-end text-to-speech를 위해 self-supervised speech representation을 활용하는 hierarchical variational autoencoder 구조 Self-s..