

티스토리 뷰
Paper/TTS
[Paper 리뷰] InstructTTS: Modelling Expressive TTS in Discrete Latent Space with Natural Language Style Prompt
feVeRin 2024. 4. 13. 14:21반응형
InstructTTS: Modelling Expressive TTS in Discrete Latent Space with Natural Language Style Prompt
- Expressive Text-to-Speech는 다양한 speech pattern을 반영하는 것을 목표로 하고, 이때 style을 control 하는 style prompt로 natural language를 활용할 수 있음
- InstructTTS
- Self-supervised learning과 cross-modal metric learning을 활용하고 robust sentence embedding model을 얻기 위해 3-stage training을 제시
- 일반적인 mel-spectrogram 대신 vector-quantized acoustic token을 사용하기 위해, discrete latent space를 모델링하고 discrete diffusion probabilistic model을 활용함
- Style-speaker와 style-content의 mutual information minimization을 활용하여 style prompt에서 content, speaker information leakage를 방지
- 논문 (TASLP 2023) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 여전히 expressiveness 측면에서 human speech와 차이를 보임
- 이때 speaking style information을 학습하기 위해 2가지 방식으로 접근할 수 있음
- Framework의 condition으로 auxiliary categorical style label을 사용하는 방법
- Training set에서 pre-define 된 style만 생성 가능하기 때문에 expressiveness의 다양성에 한계가 있음 - Reference speech의 speaking style을 imitate 하는 방법
- Unsupervised 방식으로 train 될 수 있고, out-of-domain style로 generalizable 하지만, 추출된 reference style information이 interpretable 하지 않음
- 특히 사용자의 requirement와 정확하게 일치하는 reference style sample을 선택하는 것이 어려움
- Framework의 condition으로 auxiliary categorical style label을 사용하는 방법
- 한편으로 style prompt로써 natural language를 사용해 expressive TTS를 수행할 수 있고, 이를 위해서는 다음의 문제를 해결해야 함
- Natural language prompt에서 semantic information을 capture 하고, 생성된 음성의 speaking style을 control 하는 language model을 train 하는 방법이 필요
- Expressive TTS의 one-to-many mapping 문제를 효과적으로 모델링할 수 있는 acoustic model의 설계
- 이때 speaking style information을 학습하기 위해 2가지 방식으로 접근할 수 있음
-> 그래서 위 문제를 해결하고, natural language prompt를 사용하여 expressive TTS를 수행하는 InstructTTS를 제안
- InstructTTS
- Natural language prompt를 사용하는 user-controllable expressive TTS 모델
- Style prompt에서 semantic information을 capture 할 수 있는 robust sentence embedding model을 얻기 위한 3-stage strategy를 도입 - Sequence-to-Sequence language modeling task로써 discrete latent space의 acoustic feature를 모델링하고 음성 합성을 cast 함
- 이를 위해 일반적인 mel-spectrogram이 아닌 vector-quantized (VQ) acoustic feature를 활용하는 discrete diffusion model을 train 함
- Mel-spectrogram based VQ feature와 waveform-based VQ feature에 대한 2가지의 VQ acoustic feature 모델링 방식을 고려 - Acoustic model의 training 중에 Mututal Information (MI) minimization을 jointly apply 하여 style prompt의 information leakage를 방지함
- Natural language prompt를 사용하는 user-controllable expressive TTS 모델
< Overall of InstructTTS >
- Self-supervised learning과 cross-modal metric learning을 활용하고 robust sentence embedding model을 얻기 위해 3-stage training을 제시
- Vector-quantized acoustic token을 사용하기 위해, discrete latent space를 모델링하고 discrete diffusion model을 활용함
- Style-speaker와 style-content의 mutual information minimization을 활용하여 style prompt에서 content, speaker information leakage를 방지

2. Method
- InstructTTS는 content encoder, style encoder, speaker embedding module, Style-Adaptive Layer Normalization (SALN) adaptor, discrete diffusion decoder로 구성됨

- Content Encoder
- Content encoder는 content prompt에서 content representation을 추출하는 것을 목표로 함
- 구조적으로는 4개의 feed-forward transformer (FFT)로 구성된 FastSpeech2 architecture를 활용
- FFT block의 1D convolution의 hidden size, attention head, kernel size, filter size는 각각 256, 2, 9, 1024 - FFT block 다음에는 음성의 style과 밀접하게 관련되어 있는 duration, pitch 등의 information을 예측하는 variance adaptor가 추가됨
- 구조적으로는 4개의 feed-forward transformer (FFT)로 구성된 FastSpeech2 architecture를 활용
- Style Prompt Embedding Model
- Style prompt에서 style representation을 추출하는 prompt embedding model로써 RoBERTa를 활용
- 먼저 sequence length $M$에 대해 style prompt sequence $S=[S_{1}, S_{2},...,S_{M}]$이 있다고 하자
- 여기서 prompt sequence의 시작 부분에 $[CLS]$ token을 추가한 다음, 이를 prompt embedding model에 제공하고, $[CLS]$ token의 representation을 해당 sentence의 style representation으로 사용 - Natural language description을 통해 TTS style을 stably control 하기 위해서는, 다음의 2가지 condition을 만족해야 함:
- Learned style prompt space는 important semantic information을 포함할 수 있어야 함
- Prompt embedding space의 분포는 relatively uniform 하고 smooth 해야 하고, 이때 model은 useen style description으로 generalize 될 수 있어야 함
- 이를 위해 InstructTTS는 다음의 3-stage training-fine-tuning strategy를 제안:
- Training a Base Language Model
- 우선 RoBERTa를 training 함 - Fine-tuning the Pre-trained Language Model on Labeled Data
- 더 나은 semantic representation을 얻고 supervised 방식으로 parameter를 fine-tuning 하기 위해 Natural Language Inference (NLI)를 사용함
- 특히 pre-trained RoBERTa를 fine-tuning 하기 위해 InfoNCE loss를 적용함 - Cross-Modal Representation Learning between Style Prompts and Speech
- Style prompt의 prompt embedding vector와 음성의 style representation vector를 shared semantic space에 mapping 하여 TTS output의 style을 control 함
- Training a Base Language Model
- InstructTTS는 아래 그림과 같이 metric learning 기반의 Cross-Modal Representation Learning을 활용하여 style prompt와 audio pair를 기반으로 audio-text retrieval task를 구성함
- 이를 위해, 모든 style prompt에 대해 $N-1$개의 speech audio sample을 randomly choice 하고 하나의 positive audio sample과 combine 하여 training batch를 구축
- 마찬가지로 audio sample에 대해 하나의 positive style prompt와 $N-1$개의 negative style prompt를 가지는 training batch를 구축할 수도 있음
- 이때 기존의 audio-text retrieval과 같이 contrastive ranking loss와 InfoNCE loss를 training objective로 사용
- 먼저 sequence length $M$에 대해 style prompt sequence $S=[S_{1}, S_{2},...,S_{M}]$이 있다고 하자

- Style Encoder
- Style encoder는,
- 다음의 3 부분으로 구성됨
- Pre-trained robust style prompt embedding model (즉, prompt encoder)
- Pre-trained prompt embedding model은 TTS 모델의 나머지 부분을 training 할 때 fix 됨 - Prompt encoder에서 추출된 style embedding을 새로운 latent space에 mapping 하는 adaptor layer
- Reference mel-spectrogram에서 style information을 추출하는 audio encoder
- Pre-trained robust style prompt embedding model (즉, prompt encoder)
- Training stage의 목표 중 하나는 style prompt embedding과 audio embedding 사이의 distance를 최소화하는 것
- 이때 audio encoder가 style-related information만 encoding 할 수 있도록, training 중에 style-speaker mutual information $I(z_{e};z_{sid})$와 style-content mutual information $I(z_{e};c)$를 jointly minimize 함 - 여기서 Mutual Information (MI)는 random variable 간의 correlation을 측정할 수 있는 방법이지만, unknown 분포에 대한 high-dimensional random variable의 MI는 intractable 함
- 따라서 InstructTTS에서는, training 중에 mel-spectrogram에서 content/speaker information leakage를 방지하기 위해 CLUB method를 사용하여 style-content, style-speaker MI를 최소화함
- 다음의 3 부분으로 구성됨
- Modelling Mel-spectrogram in Discrete Latent Space
- InstructTTS는 expressive TTS를 위해 discrete latent space에서 mel-spectrogram을 모델링함
- 이를 위해 VQ-VAE를 intermediate representation으로 활용하여 mel-spectrogram을 모델링하고, discrete diffusion model을 기반으로 하는 non-autoregressive mel-spectrogram token generation model을 도입
- 대부분의 TTS 모델은 continuous space에서 text에서 mel-spectrogram으로의 mapping을 학습하고, pre-trained vocoder를 사용하여 예측된 mel-spectrogram을 waveform으로 decoding 함
- BUT, mel-spectrogram frequency bin은 time, frequency axis 모두에서 높은 correlation을 가지고 있음
- 결과적으로 expressive emotion이나 speaking style이 존재하는 경우 모델링하기 어려운 한계가 있음 - 따라서 InstructTTS는 continuous space가 아닌 discrete latent space에서 mel-spectrogram을 모델링하되, HiFi-GAN vocoder를 사용하여 waveform을 recover 함
- 이를 위해, large-scale speech dataset으로 VQ-VAE를 pre-training 하여 linguistic, pitch, energy 등을 encode 할 수 있는 Mel-VQ-VAE를 얻음
- 이후 vector-quantized latent coder를 predicting target으로 두고 discrete latent space에서 mel-spectrogram을 모델링함
- 그리고 Mel-VQ-VAE를 사용하여 time-frequency correlation을 reduce 하기 위해, mel-spectrogram을 latent discrete space로 변환
- 결과적으로 아래 그림과 같이 mel-spectrogram은 mel-spectrogram token의 sequence로 represent 되고, mel-spectrogram 합성은 language modeling과 같은 discrete token sequence prediction 문제로 transfer 됨
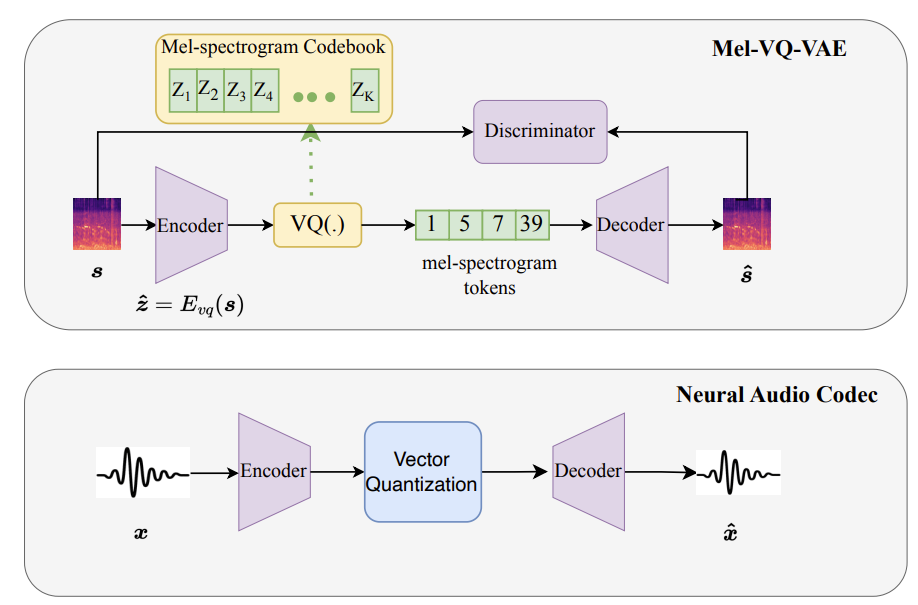
- Mel-VQ-VAE
- Mel-VQ-VAE는 mel-encoder $E_{mel}$, mel-decoder $G_{mel}$, codebook $Z=\{z_{k}\}_{k=1}^{K}\in \mathbb{R}^{K\times n_{z}}$으로 구성됨
- $K$ : codebook size, $n_{z}$ : code의 dimension - Mel-spectrogram $s\in\mathbb{R}^{F_{bin}\times T_{bin}}$을 input이라고 하면,
- 먼저 mel-spectrogram은 latent representation $\hat{z}=E_{mel}(s)\in \mathbb{R}^{F'_{bin}\times T'_{bin}\times n_{z}}$로 encoding 됨
- $F'_{bin} \times T'_{bin}$ : reduced frequency/time dimension - 이후 quantizer $Q(.)$을 사용하여 각 feature $\hat{z}_{ij}$를 가장 가까운 codebook entry $z_{k}$에 mapping 하여 discrete spectrogram token $z_{q}$을 얻음:
(Eq. 1) $z_{q}=Q(\hat{z}):=\left(\arg\min_{z_{k}\in Z}||\hat{z}_{ij}-z_{k}||_{2}^{2}\right)$ - 최종적으로 mel-spectrogram을 reconstruct 하기 위해 decoder를 적용함
- 즉, $\hat{s}=G_{mel}(z_{q})$
- 여기서 reconstruction 성능을 향상하기 위해 training stage에서 adversarial loss를 추가
- 먼저 mel-spectrogram은 latent representation $\hat{z}=E_{mel}(s)\in \mathbb{R}^{F'_{bin}\times T'_{bin}\times n_{z}}$로 encoding 됨
- Mel-VQ-VAE는 mel-encoder $E_{mel}$, mel-decoder $G_{mel}$, codebook $Z=\{z_{k}\}_{k=1}^{K}\in \mathbb{R}^{K\times n_{z}}$으로 구성됨
- Mel-VQ-Diffusion Decoder
- Pre-trained Mel-VQ-VAE를 통해 mel-spectrogram prediction 문제를 quantization token sequence prediction 문제로 transfer 함
- 이때 빠른 추론 속도를 유지하면서 고품질의 mel-spectrogram token을 생성하기 위해 Mel-VQ-Diffusion decoder를 도입 - 먼저 paried training data $(x_{0},y)$가 주어졌을 때, $y$를 phone, style, speaker feature의 combination이고 $x_{0}$는 ground-truth mel-spectrogram token이라고 하자
- InstructTTS는 $p(x_{0})$의 분포를 controllable stationary 분포 $p(x_{T})$로 corrupt 하는 diffusion process를 구축하고
- 이후 transformer-based neural network를 사용하여 $y$에 대해 condition 된 $p(x_{0})$를 recover 하는 방법을 학습함
- 이를 위해 mask와 uniform transition matrix를 활용하여 diffusion process를 guide 하고,
- 이때 transition matrix $Q_{t}\in \mathbb{R}^{(K+1)\times (K+1)}$은:
(Eq. 2) $Q_{t}=\begin{bmatrix} \alpha_{t}+\beta_{t} & \beta_{t} & \beta_{t} & \beta_{t} & ... & 0 \\ \beta_{t} & \alpha_{t}+\beta_{t} & \beta_{t} & \beta_{t} & ... & 0 \\ \beta_{t} & \beta_{t} & \alpha_{t}+\beta_{t} & \beta_{t} & ... & 0 \\ ... & ... & ... & ... & ... & ... \\ \gamma_{t} & \gamma_{t} & \gamma_{t} & \gamma_{t} & ... & 1 \\ \end{bmatrix}$
- $K+1$ index를 mask token으로 사용
- Transition matrix에서 각 token이 mask token으로 transfer 될 확률은 $\gamma_{t}$
- $K\beta_{t}$는 모든 $K$ category에 걸쳐 uniformly resample 되는 확률이고, $\alpha_{t}=1-K\beta_{t}-\gamma_{t}$의 확률로 original token을 유지 - 그러면 다음과 같이 $q(x_{t}|x_{0})$를 계산할 수 있음:
(Eq. 3) $\bar{Q}_{t}c(x_{0})=\bar{\alpha}_{t}c(x_{0})+(\bar{\gamma}_{t}-\bar{\beta}_{t})c(K+1)+\bar{\beta}_{t}$
- $\bar{\alpha}_{T}=\prod_{t=1}^{T}\alpha_{t}, \,\, \bar{\gamma}_{T}=1-\prod_{t=1}^{T}(1-\gamma_{t}),\,\, \bar{\beta}_{T}=(1-\bar{\alpha}_{T}-\bar{\gamma}_{T})/K$
- $c(\cdot)$ : sclar element를 one-hot column vector로의 transfer를 의미 - 결과적으로 stationary distribution $p(x_{T})$는:
(Eq. 4) $p(x_{T})=[\bar{\beta}_{T},\bar{\beta}_{T},...,\bar{\gamma}_{T}]$
- 이때 transition matrix $Q_{t}\in \mathbb{R}^{(K+1)\times (K+1)}$은:
- Pre-trained Mel-VQ-VAE를 통해 mel-spectrogram prediction 문제를 quantization token sequence prediction 문제로 transfer 함
- Decoder Training Target
- Posterior transition distribution $q(x_{t-1}|x_{t},x_{0})$를 추정하기 위해, network $p_{\theta}(x_{t-1}|x_{t},y)$를 training 함
- 여기서 network는 variational lower bound (VLB)를 최소화하도록 train 됨:
(Eq. 5) $\mathcal{L}_{diff}=\sum_{t=1}^{T-1}\left[D_{KL}[q(x_{t-1}|x_{t},x_{0})||p_{\theta}(x_{t-1}|x_{t},y)]\right]+D_{KL}(q(x_{T}|x_{0})||p(x_{T}))$
- Enhancing the Connection between $x_{0} and $y$
- Conditional information $y$가 network에 inject 되면 $p(x_{t-1}|x_{t},y)$를 최적화하는데 도움이 됨
- BUT, last few step에서 $x_{t}$에 충분한 information이 포함되면 network는 training stage에서 conditional information $y$를 ignore 할 수 있음 - 따라서 InstructTTS는 $x_{0}$와 $y$ 사이의 connection을 향상하는 classifier free guidance를 도입하여 $p(x|y)$를 최적화하는 대신, 다음의 target function을 최적화함:
(Eq. 6) $\log (p(x|y))+\lambda\log(p(y|x))$
- $\lambda$ : posterior constraint의 degreee를 제어하는 hyperparameter - Bayes theorem을 사용하여 (Eq. 6)은 다음과 같이 유도됨:
(Eq. 7) $\arg \max_{x}[\log p(x|y)+\lambda\log p(y|x)]=\arg \max_{x}[(\lambda+1)\log p(x|y)-\lambda \log p(x)]$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,=\arg\max_{x}[\log p(x)+(\lambda+1)(\log p(x|y)-\log p(x))]$ - 이때 unconditional mel-spectrogram token을 예측하기 위해 learnable null vector $n$을 사용하여 unconditional information $y$를 represent 함
- Training stage에서는 null vector $n$을 사용할 확률을 10%로 설정
- 추론 시에는 conditional mel-spectrogram token의 logit $p_{\theta}(x_{t-1}|x_{t},y)$를 생성한 다음, unconditional mel-spectrogram token의 logit $p_{\theta}(x_{t-1}|x_{t},n)$을 예측함
- (Eq. 7)을 기반으로 한 next step sample probability $p_{\theta}(x_{t-1}|x_{t},y)$는:
(Eq. 8) $p_{\theta}(x_{t-1}|x_{t},n)+(\lambda+1)(p_{\theta}(x_{t-1}|x_{t},y)-p_{\theta}(x_{t-1}|x_{t},n))$
- Conditional information $y$가 network에 inject 되면 $p(x_{t-1}|x_{t},y)$를 최적화하는데 도움이 됨
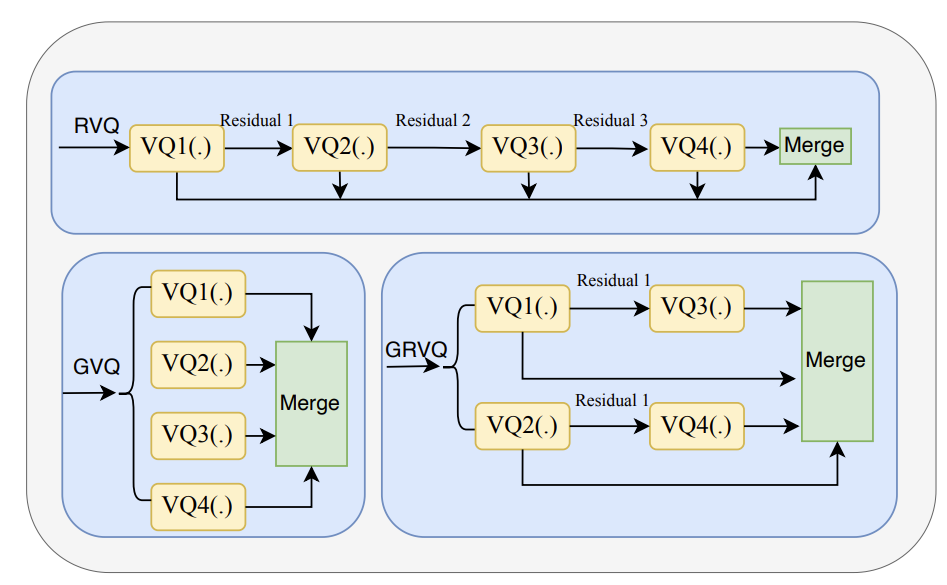
- Modelling Waveform in Discrete Latent Space via Multiple Vector Quantizers
- InstructTTS는 large-scale pre-trained neural audio codec을 사용하여 discrete latent space에서 waveform으로의 예측을 수행함
- 이 과정에서 음성 생성에 있어서 우수한 성능을 보이고 있는 neural codec을 고려할 수 있음
- 대표적으로 AudioLM은 self-supervised model을 통한 $k$-means token과 neural codec의 acoustic token을 사용하여 speech-to-speech language model을 training 함
- BUT, 해당 기존 방식들은 대부분 autoregressive 하게 동작하므로, InstructTTS는 속도를 향상하기 위해 discrete diffusion model을 기반으로 한 non-autoregressive model을 활용 - Mel-VQ-VAE에 비해서 neural audio codec에는 더 많은 codebook이 포함됨
- 결과적으로 더 많은 codebook을 사용하면 reconstruction 성능이 향상될 수 있지만, transformer를 통한 long sequence 모델링의 어려움이 있음
- 실제로 24k sampling rate를 가지는 10초 음성에 대해 8개의 codebook으로 encoder에서 $240\times$ downsampling 하면, 8000개의 token이 생성됨 - 따라서 InstructTTS는 여러 codebook을 동시에 모델링하기 위해 U-Transformer architecture를 채택함
- 아래 그림과 같이 여러 convolution layer를 사용하여 codebook number dimension을 따라 input codebook matrix를 downsampling 함
- 이후 denoising transformer를 사용하여 latent space에서 token relationship을 모델링하고, codebook dimension을 recover 하기 위해 convolution layer와 upsampling layer를 적용
- 최종적으로 여러 output layer를 사용하여 각 codebook에 대한 output prediction result를 얻음
- 이 과정에서 음성 생성에 있어서 우수한 성능을 보이고 있는 neural codec을 고려할 수 있음
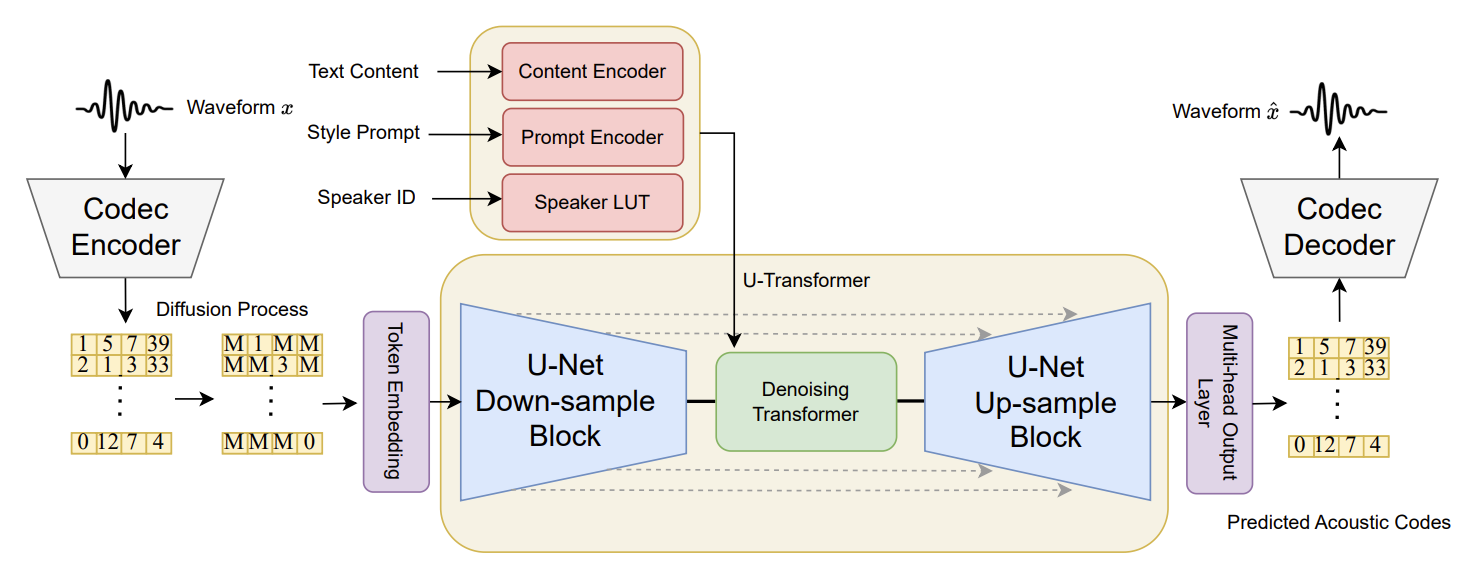
- Wave-VQ-Diffusion
- 앞선 Mel-VQ-Diffusion과 비교하여 Wave-VQ-Diffusion은 3가지 차이점이 존재
- 여러 codebook을 동시에 모델링하기 위해 U-Transformer architecture를 활용
- 서로 다른 codebook의 token은 서로 다른 data 분포를 나타내므로, 서로 다른 codebook에 대해 서로 다른 embedding table을 사용
- Codebook에 포함된 information은 첫 번째 residual vector quantization layer에서 마지막 layer로 점진적으로 decrease 함
- 해당 principle을 기반으로 diffusion process를 위한 improved mask와 uniform strategy를 설계
- 첫 번째 layer의 codebook에는 주로 text, style, speaker identity information이 포함되고, 다음 layer에는 음성 품질에 중요한 fine-grained acoustic detail이 포함됨
- 여기서 첫 번째 layer의 codebook token은 $y$의 condition으로 쉽게 recover 될 수 있지만, 다음 layer의 token은 $y$에 대한 obvious connection이 없기 때문에 recover 하기 어려움 - 따라서 easy-first-generation principle에 따라, forward process 시작 시 마지막 layer의 codebook (codebook $N_{q}$)를 masking 하고 forward process가 끝날 때 첫 번째 layer의 codebook (codebook $1$)을 masking 해야 함
- BUT, 기존의 masking/uniform strategy는 sequence의 모든 token이 동일한 importance를 가진다고 가정하므로, easy-first-generation principle을 violate 함
- 따라서 논문은 해당 문제를 해결하기 위해 다음의 improved mask, uniform startegy를 제시
- 앞선 Mel-VQ-Diffusion과 비교하여 Wave-VQ-Diffusion은 3가지 차이점이 존재
- Improved Mask and Uniform Strategy
- Transition matrix를 pre-define 할 때 서로 다른 codebook에 대해 서로 다른 weight를 dynamically allocate 함
- 이때 앞선 easy-first-generation principle을 고려하여, $\bar{\alpha}_{t}^{i},\bar{\gamma}_{t}^{i},\bar{\beta}_{t}^{i}$를 다음과 같이 구성함:
(Eq. 9) $\bar{\alpha}_{t}^{i}=1-\frac{t}{T}-\frac{\exp \left(\frac{i\% N_{q}}{2*N_{q}}\right)}{2*T},\,\, \bar{\gamma}_{t}^{i}=\frac{t}{T}+\frac{\exp \left(\frac{i \% N_{q}}{2*N_{q}}\right)}{2*T}, \,\, \bar{\beta}_{i}^{t}=(1-\bar{\alpha}_{t}^{i}-\bar{\gamma}_{t}^{i})/K$
- $N_{q}$ : neural audio codec의 residual layer index, $i$ : sequence의 token position - 논문에서는 첫 번째부터 마지막 codebook까지의 모든 token을 concatenate 함

- Training and Inference Details
- 최종적으로 InstructTTS의 training obejctive와 inference process를 요약하자면
- Training Obejctive
- InstructTTS는 end-to-end 방식으로 training 되고 이때 objective는:
(Eq. 10) $\mathcal{L}=\mathcal{L}_{diff}+\mathcal{L}_{var}+\lambda_{1}I(z_{e};c)+\lambda_{2}I(z_{e};z_{sid})+\lambda_{3}D_{Euc}(z_{p},z_{e})-\beta_{1}\mathcal{F}_{1}(\theta_{1})-\beta_{2}\mathcal{F}_{2}(\theta_{2})$
- $\mathcal{L}_{diff}$ : diffusion loss, $\mathcal{L}_{var}$ : duration/pitch/energy reconstruction loss
- $I(.)$ : mutual information, $D_{Euc}$ : $L{2}$ loss
- $\mathcal{F}_{1}(\theta_{1}), \mathcal{F}_{2}(\theta_{2})$ : 각각 $q_{\theta_{1}}(z_{sid}|z_{e})$, $q_{\theta_{2}}(z_{e}|c)$의 likelihood approximation model - 전체 training process는 위의 [Algorithm 1] 참고
- InstructTTS는 end-to-end 방식으로 training 되고 이때 objective는:
- Inference
- 추론 시에는 style prompt embedding 모델에서 추출한 feature를 style feature로 사용함
- 논문에서는 $T=100, \Delta_{t} =1$로 설정 - 전체 추론 process는 아래의 [Algorithm 2] 참고
- 추론 시에는 style prompt embedding 모델에서 추출한 feature를 style feature로 사용함
- Training Obejctive

3. Experiments
- Settings
- Dataset : NLSpeech, VCTK, AISHELL3, LibriTTS
- Comparisons : StyleSpeech
- Results
- Comparison Between InstructTTS and Baseline
- InstructTTS는 음성 품질 및 prosody 측면에서 baseline인 StyleSpeech 보다 우수한 성능을 보임
- Mel-VQ-Diffusion을 decoder로 사용하는 경우, Wave-VQ-Diffusion 보다 더 나은 음성 품질을 얻을 수 있음
- BUT, prosody detail을 유지하는 데는 Wave-VQ-Diffusion이 더 우수함
- 이때 GRVQ와 같은 audio codec을 사용하는 경우, Wave-VQ-Diffusion에서 가장 좋은 성능을 얻을 수 있음

- AXY preference test 측면에서 합성된 음성의 naturalness를 비교해 보면, 마찬가지로 InstructTTS의 결과를 더 선호하는 것으로 나타남

- 추가적으로 expressiveness modeling 측면에서도 InstructTTS가 가장 높은 성능을 보임
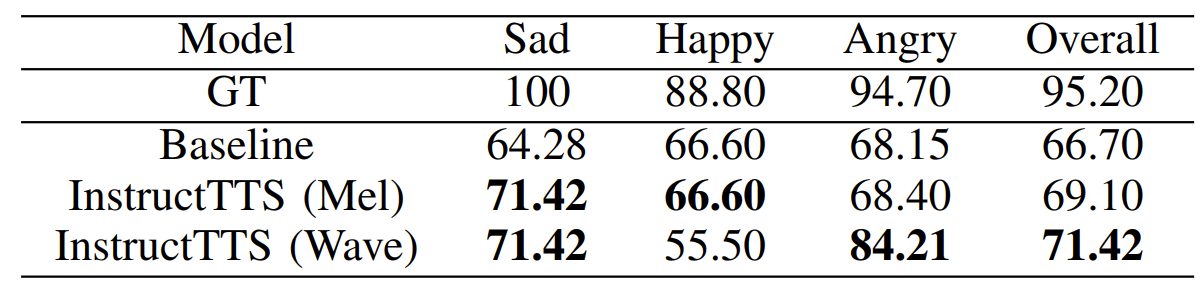
- Ablation Studies for InstructTTS
- 제안된 cross-modal representation learning을 통해 fine-tuning 하는 것이, InstructTTS의 성능을 더 향상할 수 있는 것으로 나타남
- 추가적으로 InfoNCE loss를 사용하면 contrastive ranking loss 보다 더 나은 retrieval 성능을 얻을 수 있음


- Encoded information을 constrain 하기 위해 Mutual Information Minimization (MIM)을 training에 사용함
- 이를 통해 audio encoder는 style-related information만을 encode 하도록 함
- 결과적으로 이러한 MIM training을 사용하면 품질과 pitch similarity를 모두 향상할 수 있음
- 즉, feature disentangled strategy가 더 효과적임
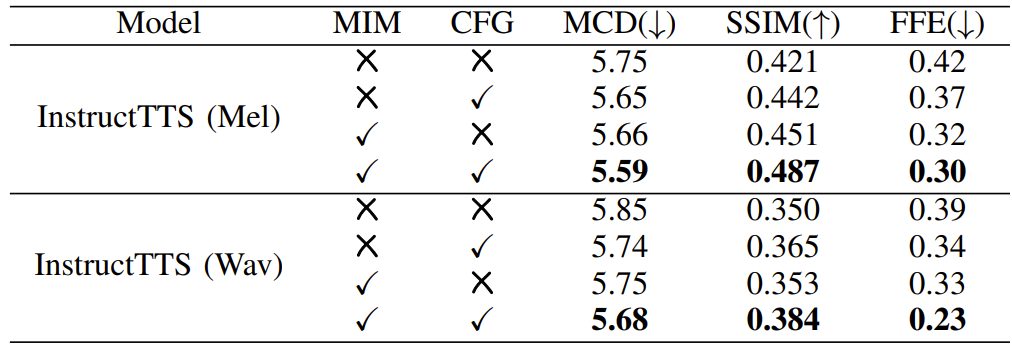
- InstructTTS에서 improved mask를 활용하는 경우 더 나은 성능을 얻을 수 있음

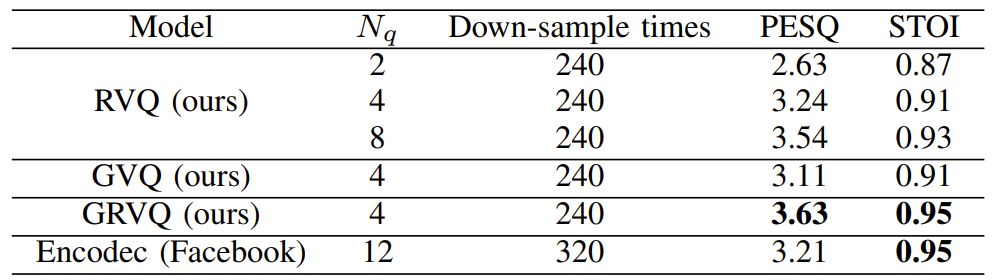
- Residual Vector Quantization (RVQ), Group Vector Quantization (GVQ), Group Residual Vector Quantization (GRVQ)를 비교해 보면
- GRVQ를 사용할 때 최고의 reconstruction 성능을 얻을 수 있음
- 이때 더 많은 codebook을 사용하면 reconstruction 성능이 향상됨
- Synthesis Variation
- Input text, conditional information에 따라 output이 unique 하게 결정되는 기존의 TTS 모델과는 달리, InstructTTS는 denoising step에서 sampling process를 통해 variation을 얻을 수 있음
- 실제로 아래 그림과 같이 합성된 sample의 $F0$ contour를 확인해 보면, InstructTTS는 다양한 pitch의 음성을 합성할 수 있는 것으로 나타남

반응형
'Paper > TTS' 카테고리의 다른 글
댓글