

티스토리 뷰
Paper/Vocoder
[Paper 리뷰] FeatherWave: An Efficient High-Fidelity Neural Vocoder with Multi-Band Linear Prediction
feVeRin 2024. 4. 10. 10:31반응형
FeatherWave: An Efficient High-Fidelity Neural Vocoder with Multi-Band Linear Prediction
- Multi-band signal processing과 linear predictive coding을 결합하여 neural vocoder를 구성할 수 있음
- FeatherWave
- LPCNet에 multi-band linear predictive coding을 결합한 모델
- Multi-band method를 활용하여 여러 sample을 병렬적으로 빠르게 합성할 수 있도록 함
- 논문 (INTERSPEECH 2020) : Paper Link
1. Introduction
- Text-to-Speech (TTS)에서 vocoder는 human-like 음성을 합성하는 데 사용됨
- 이때 음성을 합성하기 위해서는 많은 computational cost가 요구되므로, WaveGlow와 같은 flow-based vocoder가 병렬 합성을 지원하기 위해 등장함
- BUT, 해당 모델은 causality prior가 무시되기 때문에 phase issue가 종종 발생하므로 WaveNet보다 muffle 된 sound를 생성함 - 한편으로 RNN-based sequential vocoder는 보다 효율적인 합성을 지원할 수 있음
- 대표적으로 LPCNet은 $\mu$-law quantization을 활용해 작은 model size에서도 우수한 합성 품질을 달성함 - BUT, LPCNet은 single CPU 환경에서 24kHz 이상의 고품질 음성을 생성할 때, 합성 속도의 한계를 보임
- 실제로 real-time 보다 5배 느린데, 이는 1초의 음성을 합성하기 위해 200ms 이상의 latency가 필요하다는 것을 의미함
- 이때 음성을 합성하기 위해서는 많은 computational cost가 요구되므로, WaveGlow와 같은 flow-based vocoder가 병렬 합성을 지원하기 위해 등장함
-> 그래서 LPCNet에 multi-band process를 결합하여 더욱 빠른 추론 속도를 지원하는 FeatherWave를 제안
- FeatherWave
- FeatherWave는 multi-band linear prediction을 기반으로 하는 neural vocoder
- 이를 위해 LPCNet framework에 multi-band signal processing을 결합하고, discretized speech signal을 모델링하기 위해 $\mu$-law quantization을 활용
- 이러한 multi-band linear prediction process를 통해 complexity를 크게 줄임 - 결과적으로 24kHz의 고품질 음성을 합성할 때, FeatherWave는 real-time 보다 10배 빠른 추론 속도를 달성함
- 동시에 4.55의 높은 MOS 품질을 달성
< Overall of FeatherWave >
- LPCNet에 multi-band linear predictive coding을 결합한 모델
- Multi-band method를 활용하여 여러 sample을 병렬적으로 빠르게 합성할 수 있도록 함
- 결과적으로 빠른 합성 속도와 우수한 품질을 달성
2. Method
- FeatherWave는 Multi-Band process를 활용해 속도를 향상하고, LPCNet의 Linear Prediction 장점을 반영함
- Multi-band Linear Prediction
- 먼저 우수한 합성 품질을 얻을 수 있는 linear prediction (LP)과 빠른 합성 속도를 지원하는 multi-band (MB) process를 결합한 Multi-Band Linear Prediction (MB-LP)를 모델에 도입
- Multi-band waveform signal에 대한 LP analysis를 통해, 각 sub frequency band의 $M$-order linear prediction coefficient $\alpha_{k}^{b}$를 mel-spectrogram frame의 해당 frequency bin에서 추출할 수 있음
- 이때 $b$-th sub-band signal $g^{b}$는 invertible analysis filter를 통해 original signal $x$에서 downsampling 됨 - LP 가정 하에서, 예측된 signal $p_{n}^{b}$와 $b$-th band의 excitation (prediction residual) $e_{n}^{b}$는 다음과 같이 계산됨:
(Eq. 1) $p_{n}^{b}=\sum_{k=1}^{M}\alpha_{k}^{b}g_{n-k}^{b}$
(Eq. 2) $g^{b}_{n}=p_{n}^{b}+e_{n}^{b}$
- Multi-band waveform signal에 대한 LP analysis를 통해, 각 sub frequency band의 $M$-order linear prediction coefficient $\alpha_{k}^{b}$를 mel-spectrogram frame의 해당 frequency bin에서 추출할 수 있음
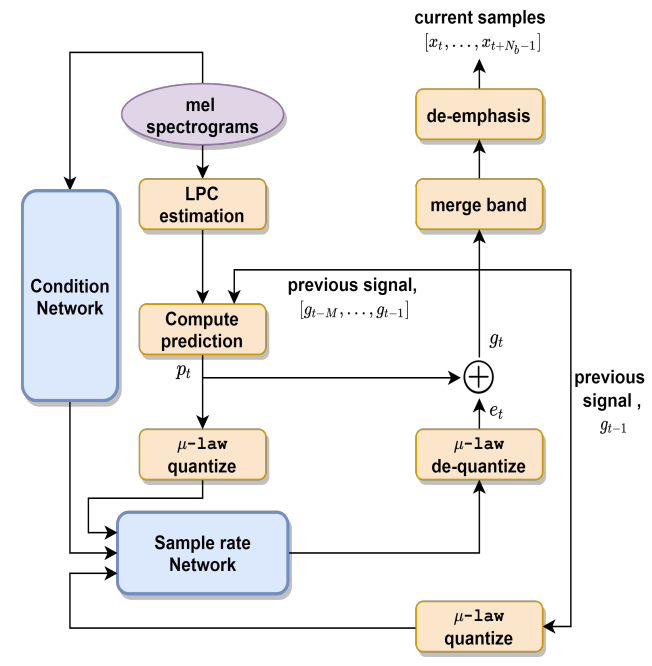
- FeatherWave
- FeatherWave는 MB-LP를 활용하여, mel-spectrogram의 input frame에서 동작하는 condition network와 multi dual softmax output layer를 통해 $N_{b}$ sample을 생성하는 sample rate network로 구성됨
- WaveRNN과 유사하게 sampling network는 excitation signal의 coarse part를 예측한 다음, 예측된 coarse signal을 conditioning 하여 fine part를 계산함
- 이때 (Eq. 2)와 같이 sub-band signal은 network output excitation과 (Eq. 1)로 얻어진 linear predicted signal을 사용하여 예측됨 - 이후 FeatherWave는 synthesis filter를 사용한 merge band operation을 적용해, 예측된 sub-band signal로부터 original waveform signal을 reconstruct 함
- 논문에서는 일반적으로 사용되는 mel-spectrogram을 input conditional feature로 사용함
- WaveRNN과 유사하게 sampling network는 excitation signal의 coarse part를 예측한 다음, 예측된 coarse signal을 conditioning 하여 fine part를 계산함
- Discretized Multi-band Linear Prediction
- LPCNet에서는 first-order pre-emphasis filter $E(z) = 1- \alpha z^{-1}$이 training data에 적용되고, 이러한 pre-emphasis를 통해 8-bit $\mu$-law discretized signal을 고품질로 모델링함
- FeatherWave에서는 모델의 효율성을 더욱 향상하기 위해 해당 pre-emphasis를 확장
- 따라서 pre-emphasis filter를 먼저 training signal에 적용한 다음, $\mu$-law를 사용하여 MB-LP process 이후의 모든 sub-band signal을 quantize 함
- 이를 통해 LPCNet과 마찬가지로, $\mu$-law discretized signal 모델링과 MB-LP framework를 사용하여 작은 모델로도 고품질의 합성이 가능해짐
- 논문에서는 FeatherWave의 각 sub-band signal에 대해 10-bit $\mu$-law quantization을 채택
- Condition Network
- Neural vocoder에서 생성되는 음성의 intelligibility는 condition network structure에 민감함
- 따라서 FeatherWave는 bi-directional RNN을 사용하는 대신, streaming inference를 위한 condition network로 convolution layer stack을 채택함
- Local acoustic feature는 먼저 5개의 $1\times 3$ convolution layer로 처리되므로 sample rate network에 충분한 receptive field를 제공할 수 있음
- 이때 안정적인 training을 위해 exponential linear unit (ELU) activation을 채택 - 이후 target signal과 sampling rate를 match 하기 위해 condition network의 output은 $f$번 repeat 됨
- $h$를 hop size라고 했을 때, repetition 수 $f=h/N_{b}$
- Sample Rate Network
- Sample rate network에서 linear prediction으로 계산된 결과는 LPCNet을 따라 closed-loop synthesis 방식으로 condition 됨
- Condition network의 output에서 upsample 된 feature와 previous generated signal도 추가적으로 사용함 - 모든 discretized signal은 GRU cell에 feed 되기 전에 trainable embedding layer로 전달됨
- 여기서 WaveRNN과 유사하게 dual softmax layer를 사용하여 GRU, affine layer 이후의 discretized signal에 대한 coarse/fine part를 sequential 하게 예측
- 이때 추론 속도 향상을 위해, GRU layer의 parameter를 sparsify 하는 block sparse pruning을 도입함 - 이후 Affine layer의 output은 multiple softmax layer로 전달되어 모든 sub-band excitation을 simultaneous 하게 예측하고, parameter는 Negative Log-Likelihood (NLL) loss을 최소화하는 것으로 최적화됨
- Sample rate network에서 linear prediction으로 계산된 결과는 LPCNet을 따라 closed-loop synthesis 방식으로 condition 됨
- Generation Model
- Lightweight neural vocoder에서 random sampling process로 인해 발생하는 noise를 방지하고, 더 나은 품질을 달성하기 위해 output distribution의 sharpness를 adjust 해야 함
- FFTNet의 경우 constant factor를 사용하여 voiced region의 temperature를 낮추는 방식을 사용함
- LPCNet의 경우 temperature factor를 adjust 하기 위해 pitch correlation을 채택하고, impulse noise를 방지하기 위해 constant threshold $T$을 통해 distribution substraction을 수행함 - FeatherWave도 마찬가지로 더 나은 성능을 위해 distribution substraction technique을 활용함
- 경험적으로 temperature $T=0.02$에서 최적의 결과를 얻을 수 있는 것으로 나타남
- 여기서 substraction은 다음과 같이 fine part에 대해서만 수행됨:
(Eq. 3) $P'_{f}(e_{t})=\mathcal{R}(\max[P_{f}(e_{t})-T, 0])$
- $P_{f}(e_{t})$ : fine part의 distribution, $\mathcal{R}(\cdot)$ : normalizing operator
- Lightweight neural vocoder에서 random sampling process로 인해 발생하는 noise를 방지하고, 더 나은 품질을 달성하기 위해 output distribution의 sharpness를 adjust 해야 함
- Two-stage Sparse Pruning
- Block sparse weight를 갖는 GRU는 neural vocoder에서 빠른 추론을 가능하게 함
- FeatherWave에서는 이러한 block sparse strategy의 성능을 향상하기 위해, two-stage sparse pruning (TSSP)를 도입하여 GRU weight에서 높은 sparsity ratio를 달성함
- 기존의 block sparsity pruning를 채택하면 40% 이상의 높은 sparsity ratio에서는 모델의 성능이 저하됨
- 즉, 높은 sparsity ratio를 사용하면 추론 속도를 향상할 수 있지만 음성 품질의 저하가 필연적으로 발생함 - 이때 warming-up stage와 increasing stage의 2단계로 구성된 TSSP를 도입하면 위 문제를 해결 가능
- Warming-up stage에서는 모델의 성능 저하를 방지하기 위해 50%의 warming-up sparsity ratio로 sparse model을 training 함
- Increasing stage에서는 target sparsity ratio에 도달하기 위해 loop 별로 sparsity ratio를 점진적으로 증가시킴
- e.g.) loop 당 sparsity ratio를 10%씩 증가시키는 방식 - 이후 warming-up sparisity ratio나 increasing stage의 loop에서 target sparsity ratio에 도달하면, constant iteration을 통해 sparsity ratio를 유지함
3. Experiments
- Settings
- Dataset : Mandarin Corpus (internal)
- Comparisons : LPCNet
- Results
- Synthesis Speed
- FeatherWave의 computational complexity는:
(Eq. 4) $C=(3dN^{2}_{G}+N_{G}\cdot N_{F}+2N_{F}\cdot Q\cdot N_{B})\cdot 2F_{S}/N_{B}$
- $N_{G}$ : sparse GRU의 size, $d$ : sparse GRU의 density, $Q$ : $\mu$-law level 수에 대한 root
- $N_{F}$ : fully-connected layer와 연결된 affine layer의 width, $N_{B}$ : frequency band 수, $F_{S}$ : sampling rate - $F_{S}=16000, N_{G} = 384, d=0.1, Q=32, N_{F}=128, N_{B}=4$로 설정했을 때, FeatherWave의 total complexity는 1.6 GFLOPS
- 결과적으로 FeatherWave는 LPCNet보다 더 적은 parameter 수를 가지면서 더 빠른 합성 속도를 보임
- FeatherWave의 computational complexity는:

- Evaluations
- MOS 측면에서 FeatherWave의 성능을 비교해 보면, LPCNet보다 더 고품질의 음성을 합성할 수 있는 것으로 나타남
- FeatherWave는 dual softmax layer를 통한 10-bit $\mu$-law quantization을 사용하므로 LPCNet보다 quantization noise와 fidelity loss가 더 적기 때문

- 제안된 two-stage sparse pruning (TSSP)의 효과를 확인해 보면, 일반적인 pruning에 비해 TSSP를 사용했을 때 더 낮은 NLL 결과를 얻을 수 있음

반응형
'Paper > Vocoder' 카테고리의 다른 글
댓글