
 [Paper 리뷰] EnCodec: High-Fidelity Neural Audio Compression
[Paper 리뷰] EnCodec: High-Fidelity Neural Audio Compression
EnCodec: High Fidelity Neural Audio Compression Neural network를 사용하여 real-time, high-fidelity의 audio codec을 구성할 수 있음 EnCodec End-to-End 방식으로 학습된 quantized latent space를 가지는 streaming encoder-decoder architecture를 활용 Artifact를 줄이고 고품질의 sample을 합성하기 위해 multi-scale spectrogram adversary를 사용하여 training을 단순화하고 속도를 향상함 이때 training을 stabilize 할 수 있는 loss balancer mechanism을 도입 논문 (Meta AI 2022) : Paper..
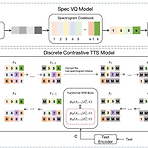 [Paper 리뷰] DCTTS: Discrete Diffusion Model with Contrastive Learning for Text-to-Speech Generation
[Paper 리뷰] DCTTS: Discrete Diffusion Model with Contrastive Learning for Text-to-Speech Generation
DCTTS: Discrete Diffusion Model with Contrastive Learning for Text-to-Speech Generation Text-to-Speech에서 latent diffusion model을 우수한 성능을 보이고 있지만, resource consumption이 크고 추론 속도가 느림 DCTTS Discrete diffusion model과 contrastive learning을 결합한 text-to-speech 모델 간단한 text encoder와 VQ model을 사용하여 raw data를 discrete space로 compress 한 다음, discrete space에서 diffusion model을 training 함 이때 diffusion step 수를 줄..
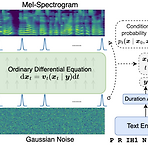 [Paper 리뷰] VoiceFlow: Efficient Text-to-Speech with Rectified Flow Matching
[Paper 리뷰] VoiceFlow: Efficient Text-to-Speech with Rectified Flow Matching
VoiceFlow: Efficient Text-to-Speech with Rectified Flow Matching Text-to-Speech에서 diffusion model은 우수한 성능을 보이고 있지만 sampling complexity로 인해 비효율적임 VoiceFlow 제한된 sampling step으로도 고품질의 합성을 수행할 수 있는 rectified flow matching을 활용 Text input을 condition으로 하여 mel-spectrogram을 ordinary differential equation을 통해 추정 Rectified flow는 효율적인 합성을 위해 sampling trajectory를 straighten 함 논문 (ICASSP 2024) : Paper Link 1...
 [Paper 리뷰] Universal MelGAN: A Robust Neural Vocoder for High-Fidelity Waveform Generation in Multiple Domains
[Paper 리뷰] Universal MelGAN: A Robust Neural Vocoder for High-Fidelity Waveform Generation in Multiple Domains
Universal MelGAN: A Robust Neural Vocoder for High-Fidelity Waveform Generation in Multiple Domains 여러 domain에서 high-fidelity의 음성을 합성할 수 있는 vocoder가 필요함 Universal MelGAN MelGAN-based structure에 multi-resolution spectrogram discriminator를 추가하여 생성된 waveform의 spectral resolution을 향상 이를 통해 large footprint 모델의 high-frequency band에서의 over-smoothing 문제를 방지 논문 (ICASSP 2021) : Paper Link 1. Introduction ..
 [Paper 리뷰] LightCodec: A High Fidelity Neural Audio Codec with Low Computation Complexity
[Paper 리뷰] LightCodec: A High Fidelity Neural Audio Codec with Low Computation Complexity
LightCodec: A High Fidelity Neural Audio Codec with Low Computation ComplexityNeural codec은 높은 computational complexity의 한계를 가지고 있음- 즉, complexity를 줄이는 경우 성능이 현저하게 저하되므로 low computation resource에서 사용하기 어려움LightCodec높은 품질을 유지하면서 낮은 complexity를 가지는 neural audio codecFrequency band division에 기반한 structure를 도입하고 Within Band-Across Band Interaction (WBABI) module을 통해 subband에 대한 feature를 학습하도록 함Quant..
 [Paper 리뷰] AudioDec: An Open-Source Streaming High-Fidelity Neural Audio Codec
[Paper 리뷰] AudioDec: An Open-Source Streaming High-Fidelity Neural Audio Codec
AudioDec: An Open-Source Streaming High-Fidelity Neural Audio Codec Telecommunication과 같은 live application에 적합한 audio codec은 다음의 속성을 만족해야 함 - Compression : signal을 transmit 하는데 필요한 bitrate는 가능한 낮아야 함 - Latency : encoding, decoding은 최소한의 delay만으로 수행되어야 함 - Reconstruction quality of signal AudioDec 위 3가지 property를 모두 만족하는 streamable, real-time neural audio codec 6ms 미만의 GPU에서 12kbps 만으로 동작하면서 고품질의..