
 [Paper 리뷰] SpatialCodec: Neural Spatial Speech Coding
[Paper 리뷰] SpatialCodec: Neural Spatial Speech Coding
SpatialCodec: Neural Spatial Speech CodingMulti-channel recording에 embed 된 spatial cue를 정확하게 reconstruct 하고 preserve 하기 위한 효과적인 encoding 방식이 필요함SpatialCodecSingle-channel neural sub-band와 SpatialCodec의 two phase로 구성된 neural audio coding framework Neural sub-band codec은 low bitrate로 reference channel을 encode 하고SpatialCodec은 decoder end에서 정확한 multi-channel reconstruction을 위해 relative spatial info..
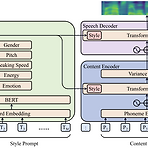 [Paper 리뷰] PromptTTS: Controllable Text-to-Speech with Text Descriptions
[Paper 리뷰] PromptTTS: Controllable Text-to-Speech with Text Descriptions
PromptTTS: Controllable Text-to-Speech with Text Descriptions Text description을 generation task를 guide 하는 데 사용할 수 있음 PromptTTS 음성 합성을 위해 style, content description이 포함된 prompt를 input으로 사용하는 text-to-speech 모델 Prompt에서 해당 representation을 추출하는 style encoder, content encoder를 활용하고, 추출된 style, content representation에 따라 음성을 합성하는 speech decoder로 구성됨 추가적으로 prompt가 포함된 dataset이 없으므로, 이에 해당하는 새로운 dataset..
 [Paper 리뷰] Elucidating the Design Space of Diffusion-based Generative Models
[Paper 리뷰] Elucidating the Design Space of Diffusion-based Generative Models
Elucidating the Design Space of Diffusion-based Generative Models현재의 diffusion-based generative model은 불필요하게 복잡함EDMDiffusion model에 대한 구체적인 design choice을 위한 명확한 design space를 제시이를 위해 sampling, training process, score network의 pre-conditioning 등에 대한 다양한 변경 사항들을 identify 함논문 (NeurIPS 2022) : Paper Link1. IntroductionDiffusion-based generative model은 conditional/unconditional 설정 모두에서 뛰어난 합성 성능을 보이..
 [Paper 리뷰] UniCATS: A Unified Context-Aware Text-to-Speech Framework with Contextual VQ-Diffusion and Vocoding
[Paper 리뷰] UniCATS: A Unified Context-Aware Text-to-Speech Framework with Contextual VQ-Diffusion and Vocoding
UniCATS: A Unified Context-Aware Text-to-Speech Framework with Contextual VQ-Diffusion and VocodingSemantic token과 acoustic token으로 나누어진 discrete speech token을 활용하면 text-to-speech의 성능을 향상 가능대표적으로 VALL-E와 SPEAR-TTS는 짧은 speech prompt에서 추출된 acoustic token에 대한 autoregressive continuation으로 zero-shot speaker adaptation이 가능함- BUT, 해당 autoregressive 모델은 순차적으로 수행되므로 speaker editing에는 적합하지 않고, audio code..
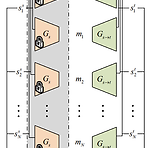 [Paper 리뷰] AdaVocoder: Adaptive Vocoder for Custom Voice
[Paper 리뷰] AdaVocoder: Adaptive Vocoder for Custom Voice
AdaVocoder: Adaptive Vocoder for Custom Voice Custom voice는 few target recording만을 사용하여 personal 음성 합성을 구축하는 것을 목표로 함 이때 vocoder 학습을 위한 multi-speaker dataset은 확보하기 어렵고, target speaker의 분포는 training dataset의 분포와 항상 mismatch 하게 나타나는 문제점이 있음 AdaVocoder Adaptive vocoder를 위해 cross-domain consistency loss를 도입 Few-shot transfer learning에 대한 GAN-based vocoder의 overfitting 문제를 해결하여 고품질의 custom voice를 얻음 ..
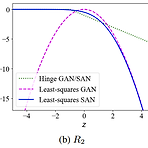 [Paper 리뷰] BigVSAN: Enhancing GAN-based Neural Vocoders with Slicing Adversarial Network
[Paper 리뷰] BigVSAN: Enhancing GAN-based Neural Vocoders with Slicing Adversarial Network
BigVSAN: Enhancing GAN-based Neural Vocoders with Slicing Adversarial Network Generative Adversarial Network (GAN) 기반의 vocoder는 빠르게 고품질의 waveform을 합성할 수 있다는 장점이 있음 - BUT, 대부분의 GAN은 feature space에서 real/fake data를 discriminating 하기 위한 optimal projection을 얻지 못하는 것으로 나타남 BigVSAN Optimal projection을 얻을 수 있는 Slicing Adversarial Network (SAN)을 vocoding task에 적용한 모델 GAN-based vocoder에서 채택되는 least-squar..