

 [Paper 리뷰] CLAPSpeech: Learning Prosody from Text Context with Contrastive Language-Audio Pre-training
[Paper 리뷰] CLAPSpeech: Learning Prosody from Text Context with Contrastive Language-Audio Pre-training
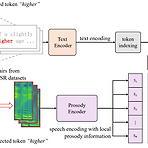
CLAPSpeech: Learning Prosody form Text Context with Contrastive Language-Audio Pre-trainingExpressive text-to-speech를 위한 masked token reconstruction은 prosody를 효과적으로 모델링하는 것이 어려움CLAPSpeech서로 다른 context에서 동일한 text token의 prosody variance를 explicitly learning 하는 cross-modal contrastive pre-training framework를 활용Encoder input과 contrastive loss를 설계하여 joint multi-modal space에서 text context와 해당 prosody..
 [Paper 리뷰] STEN-TTS: Improving Zero-Shot Cross-Lingual Transfer for Multi-Lingual TTS with Style-Enhanced Normalization Diffusion Framework
[Paper 리뷰] STEN-TTS: Improving Zero-Shot Cross-Lingual Transfer for Multi-Lingual TTS with Style-Enhanced Normalization Diffusion Framework
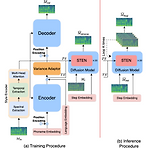
STEN-TTS: Improving Zero-Shot Cross-Lingual Transfer for Multi-Lingual TTS with Style-Enhanced Normalization Diffusion FrameworkMultilingual text-to-speech는 주로 fine-tuning을 활용하거나 personal style을 추출하는데 중점을 둠STEN-TTS3초의 reference 만으로 multilingual 합성을 수행하고 style을 유지하는 Style-Enhanced Normalization (STEN)을 도입추가적으로 diffusion model에 해당 STEN module을 결합하여 style을 simulate 함논문 (INTERSPEECH 2023) : Paper Li..
 [Paper 리뷰] PVAE-TTS: Adaptive Text-to-Speech via Progressive Style Adaptation
[Paper 리뷰] PVAE-TTS: Adaptive Text-to-Speech via Progressive Style Adaptation
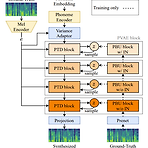
PVAE-TTS: Adaptive Text-to-Speech via Progressive Style AdaptationAdaptive text-to-speech는 limited data에서 speaking style을 학습하기 어렵기 때문에 새로운 speaker에 대한 합성 품질이 떨어짐PVAE-TTSStyle에 점진적으로 adapting 하면서 data를 생성하는 Progressive Variational AutoEncoder를 채택추가적으로 adaptiation 성능을 향상하기 위해 Dynamic Style Layer Normalization을 도입논문 (ICASSP 2022) : Paper Link1. IntroductionText-to-Speech (TTS) system을 training 하기 위..
 [Paper 리뷰] EmoSphere-TTS: Emotional Style and Intensity Modeling via Spherical Emotion Vector for Controllable Emotional Text-to-Speech
[Paper 리뷰] EmoSphere-TTS: Emotional Style and Intensity Modeling via Spherical Emotion Vector for Controllable Emotional Text-to-Speech
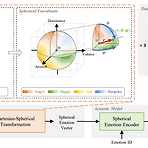
EmoSphere-TTS: Emotional Style and Intensity Modeling via Spherical Emotion Vector for Controllable Emotional Text-to-SpeechEmotional text-to-speech는 pre-defined label로 제한되므로 emotion의 변화를 효과적으로 반영하지 못함EmoSphere-TTSEmotional style, intensity를 control 하는 spherical emotion vector를 채택Human annotation 없이 arousal, valence, dominance pseudo-label을 사용하여 Cartesian-spherical transformation을 통해 emotion을 모델..
 [Paper 리뷰] Mega-TTS2: Boosting Prompting Mechanisms for Zero-Shot Speech Synthesis
[Paper 리뷰] Mega-TTS2: Boosting Prompting Mechanisms for Zero-Shot Speech Synthesis
Mega-TTS2: Boosting Prompting Mechanisms for Zero-Shot Speech SynthesisZero-shot text-to-speech에서 prompting mechanism은 다음의 문제를 가지고 있음- 대부분 single-sentence prompt로 training 되므로 추론 시 주어지는 data가 다양한 경우 성능이 제한됨- Prompt의 prosodic information은 timbre와 highly couple 되어 있고, 서로 untransferable 함Mega-TTS2고품질 reconstruction을 제공하면서 prosody, timbre information을 compressed latent space로 separately encode 하는 ac..
 [Paper 리뷰] RAD-MMM: Multilingual Multiaccented Multispeaker Text to Speech
[Paper 리뷰] RAD-MMM: Multilingual Multiaccented Multispeaker Text to Speech
RAD-MMM: Multilingual Multiaccented Multispeaker Text to SpeechIndividual voice characteristic을 retaining 하면서 native accent를 가지는 음성을 생성할 수 있는 multilingual system이 요구됨이를 위한 bilingual data는 expansive 하지만, 해당 data가 부족한 경우 speaker, language, accent 간의 entangle로 인해 합성 성능이 저하됨RAD-MMMAccent, language, speaker, fine-grained $F_{0}$, energy feature를 explicit control 하는 RAD-TTS를 기반으로 multilingual task로 확장..