

티스토리 뷰
Paper/TTS
[Paper 리뷰] IPACue-TTS: Integrating Prosody and Articulatory Cues in Conditional Flow Matching for Multilingual Zero-Shot TTS
feVeRin 2026. 5. 14. 14:03반응형
IPACue-TTS: Integrating Prosody and Articulatory Cues in Conditional Flow Matching for Multilingual Zero-Shot TTS
- Native-sounding cross-lingual, code-mixed Text-to-Speech model이 필요함
- IPACue-TTS
- Pronunciation, prosodic accuracy를 향상하기 위해 articulatory phoneme refinement를 incorporate
- Flow-based framework를 통해 fine-grained acoustic, prosodic feature를 explicitly modeling
- 논문 (ICASSP 2026) : Paper Link
1. Introduction
- 기존 Text-to-Speech (TTS) model은 cross-lingual, code-switching 환경에서 accent leakage가 발생함
- 한편 speech-production cue를 incorporate 하는 articulatory-informed TTS를 활용하면 clarity를 향상할 수 있음
- 추가적으로 대부분의 TTS model은 coarse global embedding이나 learned style token을 활용해 style을 modeling 하므로 linguistic content를 disentangle 하기 어려움
- 이때 jitter, formant frequency, shimmer 등과 같은 temporal acoustic parameter를 도입하면 acoustic characteristic에 대한 low-level description을 향상할 수 있음
-> 그래서 articulatory cue와 temporal acoustic feature를 활용한 IPACue-TTS를 제안
- IPACue-TTS
- Articulatory cue에 기반한 phonological rule을 도입하여 naturalness를 향상하고 Text Encoder를 language embedding에 condition 하여 language-specific articulatory variation을 capture
- Temporal acoustic, prosodic feature를 Conditional Flow에 incorporate 하여 fine-grained acoustic information을 modeling
< Overall of IPACue-TTS >
- Articulatory cue를 활용한 Conditional Flow Matching-based multilingual code-switching TTS model
- 결과적으로 기존보다 우수한 성능을 달성
2. Integrating Articulation and Prosody
- Articulatory information과 prosodic pattern을 incorporate 하면 naturalness를 향상할 수 있으므로, 논문은 speech articulation에서 derive 된 phonological rule을 구성함
- Closure Phoneme Modeling for Stop Consonants
- Aspirated, unaspirated stop consonant ($\texttt{/p/}$, $\texttt{/t/}$, $\texttt{/}\texttt{k}^\texttt{h}\texttt{/}$)는 closure 이후에 release burst가 이어지는 2-phase articulation을 가짐
- 이때 기존의 grapheme-to-phoneme conversion은 release phase만 capture 하므로 under-articulated, short stop segment를 생성할 수 있음
- 따라서 논문은 각 stop consonant에 대해 explicit closure phoneme을 도입하여 closure phase를 modeling 함
- 이를 통해 voicing contrast perception을 향상하고 natural temporal pattern을 제공할 수 있음
- Explicit Representation of Geminated Sounds
- Gemination은 stop의 경우 longer closure, fricative, nasal의 경우 sustained constriction으로 articulate 되고 surrounding vowel의 shortening으로 이어짐
- 즉, phoneme을 두 번 repeat 되는 경우, model은 prolonged closure/frication에 대한 single articulatory gesture를 independent two phoneme으로 취급할 수 있음
- 이를 해결하기 위해 논문은 lengthened sound의 temporal, spectral continuity를 encode 하는 dedicated geminate phone을 도입함
- Temporal Acoustic and Prosody Modeling
- 논문은 articulatory cue 외에도 formant detail, energy, shimmer, Hammarberg index, spectral tilt와 같은 low-level temporal acoustic descriptor를 explicit conditioning variable로 추가함
- 해당 descriptor를 통해 model은 intonation, rhythm, stress에 대한 fine-grained temporal, spectral variation을 capture 하고 naturalness와 expressiveness를 향상할 수 있음
- 특히 prosody descriptor에 대한 explicit conditioning을 통해 speaker generalization을 위한 finer-level speaker-specific characteristic을 preserve 할 수 있음

3. Architecture
- IPACue-TTS에서 text는 $\texttt{phonemizer}$를 통해 International Phonetic Alphabet (IPA)로 convert 됨
- Articulatory cue는 앞선 phonological rule을 따라 IPA에 적용되고, 각 IPA는 128-dimensional non-trainable embedding으로 convert 됨
- Phoneme positional information은 Rotational Positional Embedding (RoPE)를 통해 incorporate 됨 - 여기서 phoneset는 language 간에 공통이므로, language에 condition 된 Text Encoder를 사용하여 language 간 articulatory variation을 capture 함
- 이를 위해 IPA embedding과 함께 16-dimensional fixed embedding을 Text Encoder에 전달함
- Text Encoder는 ConvNeXt module로 구성되고, 얻어진 linguistic representation은 target mel-spectrogram의 frame 수에 맞게 filler token embedding과 concatenate 됨
- Mel-spectrogram은 target speech에서 40ms frame length, 20ms frame shift, 1024 FFT length를 사용하여 얻어지고, temporal acoustic, prosodic parameter는 $\texttt{Opensmile}$을 통해 추출됨
- IPACue-TTS는 conditional flow matching을 기반으로 mel-spectrogram의 neighbor segment를 condition으로 segment를 predict 하는 infilling task로 training 됨
- Acoustic reference는 temporal acoustic, prosodic parameter와 mel-spectrogram을 concatenate 한 다음, Conditional Flow module을 통해 modeling 됨
- 이때 predict 할 acoustic reference segment는 randomly mask 되고, F5-TTS와 같이 normalizing flow의 0-th step에서 acoustic reference와 동일한 dimension의 noise input이 initialize 됨
- Filled linguistic representation, masked acoustic reference, noise input은 concatenate 되어 Diffusion Transformer (DiT) module에 전달되고, masked segment인 acoustic target을 predict 함
- 이후 predicted output에 inverse mask를 적용하여 masked region에 대한 loss를 compute 함
- 추론 시에는 reference speech와 text가 concatenate 되어 전달됨
- Reference speech에서 추출된 acoustic reference는 unmasked segment로 사용되고, average phone duration으로 compute 된 approximate length의 mask를 filling task에 활용함
- Acoustic target은 16-step으로 predict 되고 generated mel-spectrogram은 pre-trained Vocos vocoder를 통해 reconstruct 됨
- Articulatory cue는 앞선 phonological rule을 따라 IPA에 적용되고, 각 IPA는 128-dimensional non-trainable embedding으로 convert 됨

4. Experiments
- Settings
- Dataset : IndicTTS, SYSPIN, RASA
- Comparisons : YourTTS, FastSpeech2, Matcha-TTS, E2-TTS, F5-TTS
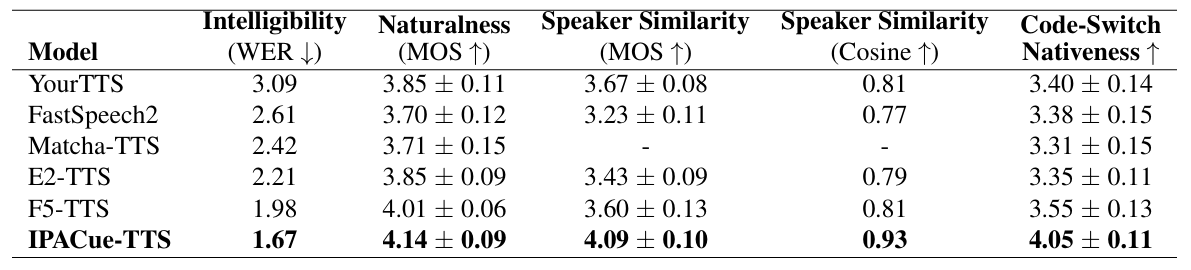
- Results
- 전체적으로 IPACue-TTS의 성능이 가장 우수함
반응형
'Paper > TTS' 카테고리의 다른 글
댓글