

티스토리 뷰
Paper/TTS
[Paper 리뷰] SFM-TTS: Lightweight and Rapid Speech Synthesis with Flexible Shortcut Flow Matching
feVeRin 2026. 5. 8. 10:47반응형
SFM-TTS: Lightweight and Rapid Speech Synthesis with Flexible Shortcut Flow Matching
- Flow matching Text-to-Speech model은 small step에서 generation quality가 떨어짐
- SFM-TTS
- Standard Gaussian distribution을 linear interpolation을 통해 ground-truth distribution으로 transform
- 추가적으로 Fast Linear Attention을 활용해 parameter 수를 절감
- 논문 (ICASSP 2026) : Paper Link
1. Introduction
- Flow Matching은 noise에서 data로의 continuous-time transport map을 학습하여 few-step sampling을 지원함
- BUT, flow matching model은 very-few step에서 generation quality가 크게 저하된다는 한계점이 있음
- 한편으로 generation quality를 향상하기 위해 consistency model, shortcut model 등을 고려할 수 있음
- 이때 Fast Linear Attention with Single Head (FLASH), ZipFormer와 같은 architecture를 활용하면 long audio sequence에 대한 computational complexity를 추가적으로 절감할 수 있음
-> 그래서 Shortcut Flow Matching과 lightweight architecture를 접목한 SFM-TTS를 제안
- SFM-TTS
- Non-fixed scheme 기반의 Shortcut Flow Matching (SFM)을 활용하여 transport process를 adpatively adjust
- ZipFormer, FLASH block을 text encoder와 decoder에 incorporate 하여 computational cost를 절감
< Overall of SFM-TTS >
- SFM과 ZipFormer, FLASH architecture를 활용한 lightweight Text-to-Speech model
- 결과적으로 기존보다 우수한 성능을 달성
2. Preliminary
- Shortcut model은 desired step size를 condition으로 single forward pass 만으로 high-quality sample을 생성할 수 있음
- Noise point $x_{0}$, data point $x_{1}$이 주어졌을 때 objective는 all possible $x_{t}, t, d$ combination에 대해 shortcut을 학습하도록 $s_{\theta}(x_{t},t,d)$를 training 함:
(Eq. 1) $x'_{t+d}=x_{t}+s_{\theta}(x_{t},t,d)d$
- $d$ : step size, $d\rightarrow 0$일 때 shortcut은 instantaneous flow와 equivalent 함 - Shortcut model의 loss function은 feature matching loss와 self-consistency loss를 combine 하여 얻어짐:
(Eq. 2) $ \mathcal{L}=\mathbb{E}_{x_{0},x_{1},t}\left[\left|\left| s_{\theta}(x_{t},t,0)-(x_{1}-x_{0})\right|\right|^{2}\right]+\mathbb{E}_{x_{0},x_{1},t,d}\left[ \left|\left| s_{\theta}(x_{t},t,2d)-s_{target}\right|\right|^{2}\right]$
- $s_{target}=\text{sg}\left(s_{\theta}(x_{t},t,d)/2+s_{\theta}(x'_{t+d},t,d)/2\right)$
- $\text{sg}(\cdot)$ : stop-gradient operation, $d$의 value는 set $\left( \frac{1}{128},\frac{1}{64},...,\frac{1}{4},\frac{1}{2}\right)$로 constrain 됨
- Noise point $x_{0}$, data point $x_{1}$이 주어졌을 때 objective는 all possible $x_{t}, t, d$ combination에 대해 shortcut을 학습하도록 $s_{\theta}(x_{t},t,d)$를 training 함:
3. Method
- Fast Linear Attention
- FLASH는 Gated Attention Unit (GAU)를 사용하여 self-attention의 computational overhead를 alleviate 함
- 특히 GAU는 Gated Linear Unit (GLU)를 다음과 같이 generalize 함:
(Eq. 3) $U=\phi_{u}(XW_{u})\in\mathbb{R}^{T\times e},$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,V=\phi_{v}(XW_{v})\in\mathbb{R}^{T\times e},$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,O=(U\odot AV)W_{o}\in\mathbb{R}^{T\times d}$
- $X\in\mathbb{R}^{T\times e}$ : $T$ token에 대한 representation, $\odot$ : element-wise multiplication, $\phi$ : activation function
- $e,d$ : 각각 expanded intermediate size/model size, $W_{u}\in\mathbb{R}^{T\times e}$, $W_{v}\in\mathbb{R}^{T\times e}$, $W_{o}\in\mathbb{R}^{T\times d}$ - $A\in\mathbb{R}^{T\times T}$는 token-token attention weight로써:
(Eq. 4) $Z=\phi_{z}(XW_{z})\in\mathbb{R}^{T\times s},$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,A=\text{relu}^{2}(\mathcal{Q}(Z)\mathcal{K}(Z)^{\top}+b)\in\mathbb{R}^{T\times T}$
- $Z$ : intermediate shared representation, $W_{z}\in\mathbb{R}^{T\times z}$
- $\mathcal{Q},\mathcal{K}$ : $Z$에 대해 per-dim scalar/offset을 적용하는 transformation, $b$ : relative position bias - $A$가 identity matrix일 때 (Eq. 3)은 GLU로 reduce 됨
- 특히 GAU는 Gated Linear Unit (GLU)를 다음과 같이 generalize 함:

- ZipFormer Block
- ZipFormer는 Multi-Head Self-Attention (MHSA)를 attention weight에 대한 Multi-Head Attention Weight (MHAW), frame information을 aggregate 하는 Self-Attention (SA)로 decompose 함
- 추가적으로 ZipFormer는 Non-Linear Attention (NLA)을 통해 first SA module에 대한 global context를 capture 함:
(Eq. 5) $\text{attention weights}: \,\,x_{a}=\text{MHSA}(\texttt{input}),$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\text{NLA}:\,\,x_{nla}=c_{1}+\text{NLA}(x_{a},c_{1}),$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\text{first SA}: \,\,x_{sa}=x_{nla}+\text{SA}(x_{a},x_{nla}),$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\text{second SA}: \,\,x_{sa}=c_{2}+\text{SA}(x_{a},c_{2})$
- $c_{1},c_{2}$ : preceding module의 output - Bypass module은 module의 input/output을 combine 하기 위해 channel-wise scalar weight를 학습하고, 기존의 LayerNorm, Swish activation 대신 BiasNorm과 SwooshR/SwooshL activation을 사용함:
(Eq. 6) $\text{BiasNorm}(x)=\frac{x}{\text{RMS}(x-b)}\cdot\exp(\gamma),$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\text{SwooshR}(x)=\log(1+\exp(x-1))-0.08x-0.313261687,$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\text{SwooshL}(x)=\log(1+\exp(x-4))-0.08x-0.035$
- $b$ : learnable channel-wise bias, $\text{RMS}$ : channel에 대한 Root-Mean-Square, $\gamma$ : scalar
- 추가적으로 ZipFormer는 Non-Linear Attention (NLA)을 통해 first SA module에 대한 global context를 capture 함:
- Flexible Shortcut Flow Matching
- Flow matching model은 source distribution $p_{0}$를 target distribution $p_{1}$으로 transform 하는 ODE-based framework로써 일반적으로 $p_{0}$는 standard Gaussian, $p_{1}$은 ground-truth distribution을 사용함
- $x_{0}\sim p_{0}, x_{1}\sim p_{1}$을 고려할 때 pair $(x_{0},x_{1})$으로 induce 된 flow는 time $t\in[0,1]$에 대한 ODE로 나타낼 수 있음:
(Eq. 7) $dx_{t}=s_{\theta}(x_{t},t)dt$ - Velocity field $s_{\theta}(x_{t},t):\mathbb{R}^{d}\rightarrow \mathbb{R}^{d}$는 $x_{0}$에서 $x_{1}$로 connect 되는 linear path direction $(x_{1}-x_{0})$와 align 되도록 optimize 됨
- 이때 objective는 $s_{\theta}(x_{t},t)$를 $(x_{1}-x_{0})$에 approximate 함:
(Eq. 8) $\mathcal{L}_{fm}=\mathbb{E}_{x_{0},x_{1},t}\left[\left|\left| s_{\theta}(x_{t},t)-(x_{1}-x_{0})\right|\right|^{2}\right]$
- $x_{t}=tx_{1}+(1-t)x_{0}$ : $x_{0},x_{1}$ 간의 linear interpolation - 해당 flow matching model을 기반으로 논문은 shortcut architecture를 도입하여 $s_{\theta}(x_{t},t,d)$와 같이 step size $d$를 additional input으로 사용할 수 있도록 함
- 여기서 논문은 non-uniform step size를 채택하여 $t\in\mathcal{U}(0,1)$의 time point를 sample 하고, $t+d_{1}+d_{2}\leq 1$이 되도록 $d_{1}>0, d_{2}>0$의 step size를 sample 함
- 그러면 $x_{t}$에서 $x_{t+d_{1}+d_{2}}$로의 다음 2가지 distinct pathway가 존재하게 됨:
(Eq. 9) $x_{t+d_{1}+d_{2}}=x_{t}+s_{\theta}(x_{t},t,d_{1})d_{1}+s_{\theta}(x_{t+d_{1}},t+d_{1}, d_{2})d_{2}$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, \texttt{or}\,\, x_{t+d_{1}+d_{2}}=x_{t}+s_{\theta}(x_{t},t,d_{1}+d_{2})(d_{1}+d_{2})$
- $x_{t+d_{1}}=x_{t}+s_{\theta}(x_{t},t,d_{1})d_{1}$ - 결과적으로 self-consistency loss는:
(Eq. 10) $\mathcal{L}_{sc}=\mathbb{E}_{x_{0},x_{1},t,d_{1},d_{2}}\left[\left|\left| s_{\theta}(x_{t},t,d_{1}+d_{2})-s_{target}\right|\right|^{2}\right],$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, s_{target}=\text{sg}\left(\alpha_{1}s_{\theta}(x_{t},t,d_{1})+\alpha_{2}s_{\theta} (x_{t+d_{1}},t+d_{1},d_{2})\right),$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\alpha_{1}=\frac{d_{1}}{d_{1}+d_{2}},\,\,\alpha_{2}=\frac{d_{2}}{d_{1}+d_{2}}$
- SFM-TTS는 text encoder, duration predictor, SFM decoder로 구성되고, 이때 overall training objective는:
(Eq. 11) $\mathcal{L}_{total}=\lambda_{1}\mathcal{L}_{dur}+\lambda_{2}\mathcal{L}_{prior}+\lambda_{3}(\mathcal{L}_{fm}+\mathcal{L}_{sc})$
- $\mathcal{L}_{dur}, \mathcal{L}_{prior}$ : Grad-TTS를 따름, $\mathcal{L}_{fm}, \mathcal{L}_{sc}$ : flexible shortcut module에 대한 objective, $\lambda_{1},\lambda_{2},\lambda_{3}$ : coefficient
- $x_{0}\sim p_{0}, x_{1}\sim p_{1}$을 고려할 때 pair $(x_{0},x_{1})$으로 induce 된 flow는 time $t\in[0,1]$에 대한 ODE로 나타낼 수 있음:
4. Experiments
- Settings
- Dataset : VCTK
- Comparisons : Grad-TTS, VoiceFlow, Matcha-TTS, RapFlow-TTS
- Results
- 전체적으로 SFM-TTS의 성능이 가장 우수함
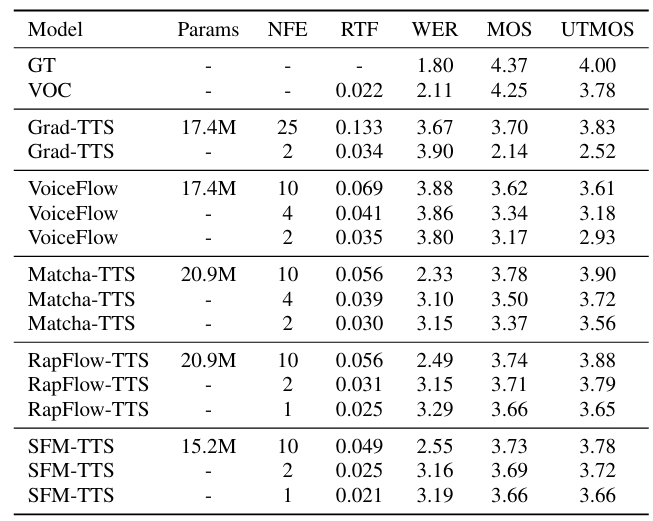
- Ablation Study
- 각 component는 성능 향상에 유효함

반응형
'Paper > TTS' 카테고리의 다른 글
댓글