

티스토리 뷰
Paper/TTS
[Paper 리뷰] NCF-TTS: Enhancing Flow Matching based Text-to-Speech with Neighborhood Consistency Flow
feVeRin 2026. 5. 6. 11:04반응형
NCF-TTS: Enhancing Flow Matching based Text-to-Speech with Neighborhood Consistency Flow
- Diffusion-based Text-to-Speech는 추론 속도의 한계와 guidance method에 대한 incompatibility가 존재함
- NCF-TTS
- Large-step sampling을 stablize 하는 Neighborhood Consistency Flow를 활용
- Conditional, unconditional supervision을 training process로 unify 하는 embedded guidance objective를 도입하고 flow matching supervision과 NCF consistency loss를 jointly optimize
- 논문 (ICASSP 2026) : Paper Link
1. Introduction
- Diffusion/Flow Matching-based Text-to-Speech (TTS) model은 high-fidelity sample을 생성할 수 있지만, 여전히 추론 속도의 한계가 있음
- 이를 위해 consistency model, shortcut model 등을 활용하여 sampling efficiency를 향상할 수 있음
- BUT, conditional generation에서 Classifier-Free Guidance (CFG)와 같은 external guidance는 few-step model과 theoretical incompatibility가 존재함
-> 그래서 diffusion-based TTS의 추론 속도와 guidance compatibility를 개선한 NCF-TTS를 제안
- NCF-TTS
- Neighborhood Consistency Flow (NCF)를 활용해 long interval displacement를 successive shorter displacement의 sequence로 decompose
- 즉, interval $[t_{1},t_{3}]$ 내의 intermediate time $t_{2}$에 대해 instantaneous velocity field $v$에 대한 integral displacement rule은 $t_{1}$에서 $t_{2}$, $t_{2}$에서 $t_{3}$까지 accumulate 된 displacement의 합과 같다는 것을 활용함
- Average velocity field $u_{13}$이 $t_{1}$에서 $t_{3}$ 까지의 velocity field $u$를 나타낸다고 하면:
(Eq. 1) $ (t_{3}-t_{1})\cdot u_{13}=(t_{2}-t_{1})\cdot u_{12}+(t_{3}-t_{2})\cdot u_{23}$
- CFG에 대한 incompatibility를 개선하기 위해 conditional, unconditional prediction을 training objective에 directly incorporate 하는 embedding guidance strategy를 도입
- Neighborhood Consistency Flow (NCF)를 활용해 long interval displacement를 successive shorter displacement의 sequence로 decompose
< Overall of NCF-TTS >
- NCF와 embedded guidance를 활용하여 추론 속도를 개선한 few-step flow matching-based TTS model
- 결과적으로 기존보다 우수한 성능을 달성
2. Preliminary
- Flow Matching
- $x_{t}$를 동일한 dimensionality의 noise point $x_{0}\sim \mathcal{N}(0,I)$, data point $x_{1}\sim \mathcal{D}$ 간의 linear interpolation이라고 하자
- Velocity $v_{t}$는 noise에서 data point로의 direction에 해당함:
(Eq. 2) $x_{t}=(1-t)\cdot x_{1}+t\cdot x_{0}$
(Eq. 3) $v_{t}=x_{1}-x_{0}$ - $x_{0}, x_{1}$이 주어지면 $v_{t}$를 fully determine 할 수 있지만, $x_{t}$만 주어지는 경우 multiple plausible pair $(x_{0},x_{1})$이 존재하고 결과적으로 velocity가 취할 수 있는 값이 달라지므로 $v_{t}$는 random variable이 됨
- Flow matching model은 $x_{t}$에서 all plausible velocity를 average 한 expectation $v_{t}=\mathbb{E}[v_{t}|x_{t}]$를 estimate 하기 위해 neural network를 학습함
- 이때 flow matching model은 noise $x_{0}$, data $x_{1}$ pair를 randomly sample 한 다음, empirical velocity를 regress 하여 optimize 할 수 있음:
(Eq. 4) $ v_{\theta}=\mathbb{E}_{x_{0},x_{1}}\sim\mathcal{D}[v_{t}|x_{t}]$
(Eq. 5) $\mathcal{L}_{FM}(\theta)=\mathbb{E}_{x_{0},x_{1}}\left[||v_{\theta}(x_{t},t )-v_{t}||_{2}^{2}\right]$
- $\theta$ : model parameter - Sampling 시에는 Normal distribution에서 noise point $x_{0}$를 sampling 하고, learned $v_{\theta}(x_{t},t)$로 govern 되는 denoising Ordinary Differential Equation (ODE)를 통해 $x_{0}$에서 $x_{1}$으로 iteratively update 함
- 이때 flow matching model은 noise $x_{0}$, data $x_{1}$ pair를 randomly sample 한 다음, empirical velocity를 regress 하여 optimize 할 수 있음:
- Velocity $v_{t}$는 noise에서 data point로의 direction에 해당함:
- Classifier-Free Guidance
- Classifier-Free Guidance (CFG)는 generation performance와 condition alignment를 향상하기 위해 사용됨
- CFG는 posterior probability를 combine 하기 위해 conditional, unconditional model을 모두 사용함:
(Eq. 6) $v_{\theta}\left\{\begin{matrix} v_{\theta}(x_{t},t,c), & \text{if conditional} \\ v_{\theta}(x_{t},t,\emptyset), & \text{otherwise} \\ \end{matrix}\right.$ - 추론 시 Guided velocity field는:
(Eq. 7) $\tilde{v}_{\theta}(x_{t},t,c)=(1-w)\cdot v_{\theta}(x_{t},t,\emptyset) +w\cdot v_{\theta}(x_{t},t,c)$
- $w$ : guidance scale, $\emptyset$ : null condition
- $w=1$인 경우 guidance 없이 conditional velocity로 sampling 하는 것과 같음
- CFG는 posterior probability를 combine 하기 위해 conditional, unconditional model을 모두 사용함:
3. Method
- NCF-TTS는 CFG를 training에 directly integrate 하여 large sampling의 relationship을 modeling 하고 conditional/unconditional prediction 모두에 대한 linear output을 학습하는 것을 목표로 함
- Neighborhood Consistnecy Flow
- Shortcut model은 discrete $d$에 condition 되어 future curvature를 modeling 하고 correct next point로 jump함
- BUT, fixed stride $d$는 model의 expressiveness를 저해하므로 논문은 discrete stride condition $d$를 continuous stride condition으로 extend 함
- Instantaneous velocity field $v$에서 임의의 ordered time point $t_{1}\leq t_{2}\leq t_{3}$에 대해 다음의 identity가 성립함:
(Eq. 8) $\int_{t_{1}}^{t_{3}}v_{\theta}(x_{t},t)dt=\int_{t_{1}}^{t_{2}}v_{\theta}(x_{t},t)dt +\int_{t_{2}}^{t_{3}}v_{\theta}(x_{t},t)dt$ - Average velocity $u$를 두 time step $t_{1}, t_{3}$ 간의 displacement를 time interval로 나눈 값이라고 하자:
(Eq. 9) $ (t_{3}-t_{1})\cdot u_{\theta}(x_{t_{1}},t_{1},t_{3})=(t_{2}-t_{1})\cdot u_{\theta}(x_{t_{1}}, t_{1},t_{2})+(t_{3}-t_{2})\cdot u_{\theta}(x_{t_{2}},t_{2},t_{3})$ - 이때 essential boundary condition은 $t_{1}=t_{2}, \,u_{\theta}(x_{t_{1}},t_{1},t_{2})=v_{\theta}(x_{t_{1}},t_{1})$과 같이 주어짐
- (Eq. 9)는 $t_{1}$에서 $t_{3}$ 까지의 displacement가 $t_{1}$에서 intermediate time $t_{2}$, $t_{2}$에서 $t_{3}$ 까지의 displacement의 summation과 equivalent 하다는 것을 의미함
- 즉, 해당 constaint는 다음을 반영함:
(Eq. 10) $u_{\theta}(x_{t_{1}},t_{1},t_{3})=\alpha\cdot u_{\theta}(x_{t_{1}},t_{1},t_{2}) +\beta u_{\theta}(x_{t_{2}},t_{2},t_{3})$
(Eq. 11) $\alpha=\frac{t_{2}-t_{1}}{t_{3}-t_{1}},\,\, \beta=\frac{t_{3}-t_{2}}{t_{3}-t_{1}}$
- $\alpha,\beta$ : weighting coefficient, $\alpha+\beta=1$
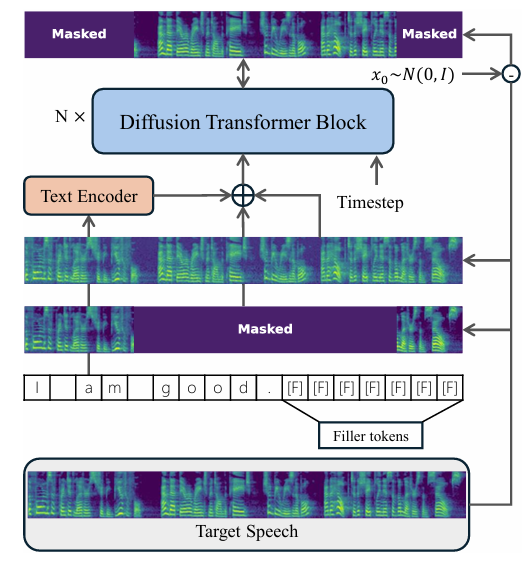
- Model Inference without Classifier-Free Guidance
- Few-shot setting에서 neural network는 source, target state를 single transformation으로 connect 하는 average velocity나 trajectory shortcut을 estimate 함
- 이때 iterative denoising process가 없으므로 guidance를 inject 할 intermediate state도 존재하지 않음
- Output stage에만 CFG를 적용하면 unconditional/conditional component를 linearly decompose 할 수 없어 instability가 발생하므로 CFG를 few-shot flow matching에 directly apply 하기 어려움 - 이를 해결하기 위해 논문은 guidance를 externally apply 하지 않고 loss function에 embed 함
- 즉, model은 conditional/unconditional prediction을 align 하면서 controllability를 retain 하는 composite objective로 optimize 됨:
(Eq. 12) $ \tilde{u}_{\theta}(x_{t_{1}},t_{1},t_{2})=w_{1}\cdot u_{\theta}(x_{t_{1}}, t_{1},t_{2},c)+w_{2}\cdot u_{\theta}(x_{t_{1}},t_{1},t_{2},\emptyset)$
- $w_{1}, w_{2}$ : conditional/unconditional weight coefficient, $w_{1}+w_{2}=1$ - 결과적으로 논문은 training 중에 guidance effect를 internalize 하여 computational overhead를 줄임
- 즉, model은 conditional/unconditional prediction을 align 하면서 controllability를 retain 하는 composite objective로 optimize 됨:
- 이때 iterative denoising process가 없으므로 guidance를 inject 할 intermediate state도 존재하지 않음

- Training and Sampling
- Few-step flow matching을 학습하기 위해 논문은 flow matching obejctive와 NCF constraint를 unify 하는 joint optimization framework를 채택함
- Model은 average velocity field $v$를 학습하고 instantaneous velocity field $v$는 boundary condition $t_{1}=t_{2}, u_{\theta}=v_{\theta}$로 사용됨
- 그러면 joint training을 위한 loss function은:
(Eq. 13) $\mathcal{L}_{all}=\lambda_{1}\cdot \mathcal{L}_{FM}+\lambda_{2}\cdot \mathcal{L}_{consist}$
- $\mathcal{L}_{FM}$ : noise, data pair 간의 flow matching loss, $\mathcal{L}_{consist}$ : NCF를 따라 local trajectory decomposition을 regularize 하는 역할, $\lambda_{1},\lambda_{2}$ : weight coefficient - Sampling은 chosen interval에 대해 learned average velocity field $u$를 sequentially apply 하여 수행됨
- 이때 guidance는 training objective에 embed 되어 있으므로 추론 시 CFG는 필요하지 않음

4. Experiments
- Settings
- Dataset : Emilia
- Comparisons : CosyVoice, CosyVoice2, F5-TTS, Seed-TTS

- Results
- 전체적으로 NCF-TTS의 성능이 가장 우수함
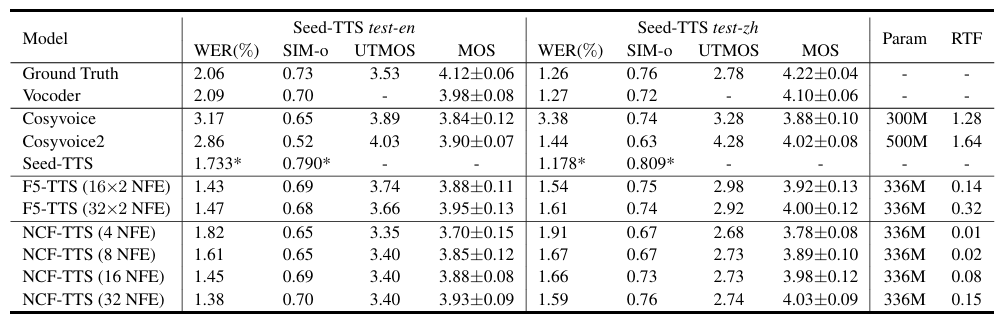
- ABX test 측면에서도 NCF-TTS가 가장 선호됨

- Ablation Study
- 각 component는 성능 향상에 유효함

반응형
'Paper > TTS' 카테고리의 다른 글
댓글