

티스토리 뷰
Paper/TTS
[Paper 리뷰] F5E-TTS: Enhancing Speech Synthesis by Aligning Text with Rich Semantic Representations
feVeRin 2026. 5. 12. 13:46반응형
F5E-TTS: Enhancing Speech Synthesis by Aligning Text with Rich Semantic Representations
- Text-to-Speech는 text, speech 간의 semantic alignment에 대한 한계가 있음
- F5E-TTS
- Phonetic PosteriorGram의 bottleneck feature를 condition으로 Diffusion Transformer backbone을 학습
- Shared Vector-Quantized codebook을 사용한 explicit cross-modal regularization을 도입
- 논문 (ICASSP 2026) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 content consistency와 prosodic richness 측면에서 여전히 한계가 있음
- 이는 text가 speech에 대한 semantically-sparse representation이기 때문
- 이를 해결하기 위해서는 Phonetic PosteriorGram (PPG)와 같은 semantically-dense modality를 활용해야 함
-> 그래서 PPG embedding을 활용하여 기존 flow matching TTS model을 개선한 F5E-TTS를 제안
- F5E-TTS
- Sparse text와 PPG embedding을 활용하여 speech content에 대한 robust internal representation을 학습
- Diffusion Transformer (DiT) backbone을 통해 text, PPG embedding을 implicitly align 하고 Shared Vector-Quantized (VQ) codebook을 통해 explicit alignment를 반영
< Overall of F5E-TTS >
- PPG embedding과 explicit alignment를 활용한 semantically-rich TTS model
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- Model Architecture
- F5E-TTS는 DiT backbone을 가진 flow matching network인 F5-TTS를 기반으로 함
- 이때 network는 다음 4가지 input을 사용함:
- Text sequence
- Phonetic, prosodic detail을 위한 PPG embedding
- Speaker timbre에 대한 prompt audio mel-spectrogram
- Flow generation process를 위한 noisy target mel-spectrogram
- Text, PPG embedding은 dedicated pre-net을 통해 process되고 해당 embedding은 mel-spectrogram length에 맞게 padding 됨
- Combined sequence는 flow matching module을 condition 하여 final mel-spectrogram을 생성하고, pre-trained Vocos vocoder를 통해 waveform으로 convert 됨
- 이때 network는 다음 4가지 input을 사용함:

- Training for Enhanced Content Representation
- Classifier-Free Guidance for Multi-Modal Learning
- F5E-TTS training은 Classifier-Free Guidance (CFG)로 guide 되는 multi-task objective를 활용하여 model이 robust, disentangled representation을 학습하도록 유도함
- 이때 주요 training configuration은:
- Primary TTS Task
- Model은 speaker prompt, text에 대해 condition 되고 PPG는 drop 됨 - Rich Context Learning from PPG
- Model은 text가 drop 된 상태에서 PPG, speaker prompt에 condition 됨
- 이는 rich semantic feature에서 speech로의 mapping을 유도하여 natural prosody를 강화함 - Joint Alignment Task
- Text, PPG embedding을 모두 제공하여 DiT가 lexical, prosodic information 간의 joint alignment를 학습하도록 유도함 - Speaker Adaptation
- Speaker modeling을 향상하기 위해 certain probability로 prompt audio condition을 drop 함
- 이를 통해 model은 specific speaker에 less-dependent 한 generalized representation을 학습할 수 있음
- Primary TTS Task
- Explicit Alignment with a Shared Codebook
- Textual, phonetic modality를 unified semantic space로 explicitly align 하기 위해 논문은 Cross-Modal Vector Quantization을 도입함
- 특히 논문은 SpeechT5를 따라 2개의 distinct data stream의 continuous representation을 shared, discrete latent space에 mapping 하는 bridge를 구축함 - 이를 위해 $K$ learnable embedding vector를 포함하는 shared codebook $C^{K}$를 도입함
- Text, PPG input이 각각의 pre-net을 통해 process 된 다음, resulting continuous representation $u$는 vector quantizer로 전달됨
- 이때 quantizer는 Gumbel-Softmax를 통해 continuous vector $u_{i}$를 discrete codebook $c_{i}$로 convert 함:
(Eq. 1) $c_{i}=\sum_{j=1}^{K}\text{softmax}\left(\left(\log \pi_{j}+g_{j}\right)/\tau\right)\cdot c_{j}$
- $\pi_{j}$ : 각 codebook entry의 logit, $g_{j}$ : $\text{i.i.d.}$ Gumbel sample, $\tau$ : temperature - 해당 operation은 text, PPG embedding 모두에 대해 independent 하게 적용되지만, 동일한 codebook $C^{K}$를 사용하므로 동일한 representational space로 forcing 됨
- Model이 meaningful alignment를 학습하고 quantized representation을 ignore 하지 않도록, main DiT network 이전에 continuous vector의 certain percentage를 quantized counterpart로 randomly replace 함
- 추가적으로 text, PPG token에 대한 overlapping quantized vector를 학습할 수 있도록, batch에 대한 codebook usage의 averaged softmax distribution entropy를 maximize 하는 perplexity loss $\mathcal{L}_{p}$를 도입함:
(Eq. 2) $\mathcal{L}_{p}=\frac{1}{K}\sum_{k=1}^{K}p_{k}\log p_{k}$
- $p_{k}$ : $k$-th code를 choice 할 averaged probability - 그러면 final loss는:
(Eq. 3) $\mathcal{L}=\mathcal{L}_{denoising}+\gamma\mathcal{L}_{p}$
- $\gamma=0.1$ : hyperparameter
- Textual, phonetic modality를 unified semantic space로 explicitly align 하기 위해 논문은 Cross-Modal Vector Quantization을 도입함

- Controllable Inference
- F5E-TTS는 CFG를 활용하여 primary condition (speaker prompt $c_{spk}$, text $c_{txt}$, noise $z_{t}$) 각각에 대한 guidance strength를 independently adjust 할 수 있음
- 특히 final guided output $\hat{f}_{\theta}$는 conditional, unconditional output에 대한 weighted combination과 같음
- 결과적으로 TTS task에서 guided flow는:
(Eq. 4) $ \hat{f}_{\theta}(z_{t},c_{spk},c_{txt},\emptyset) = f_{\theta}(z_{t},\emptyset, \emptyset, \emptyset) + \alpha_{txt}\left[f_{\theta}(z_{t},\emptyset,c_{txt},\emptyset) - f_{\theta}(z_{t},\emptyset,\emptyset, \emptyset)\right]$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,+ \alpha_{spk}\left[f_{\theta}(z_{t},c_{spk},c_{txt},\emptyset)-f_{\theta}(z_{t},\emptyset, c_{txt},\emptyset)\right]$
- $\alpha_{spk}, \alpha_{txt}$ : guidance scale, $\emptyset$ : empty input
3. Experiments
- Settings
- Dataset : Emilia
- Comparisons : F5-TTS
- Results
- 전체적으로 F5E-TTS의 성능이 가장 우수함

- Seed-TTS dataset에 대해서도 우수한 성능을 보임
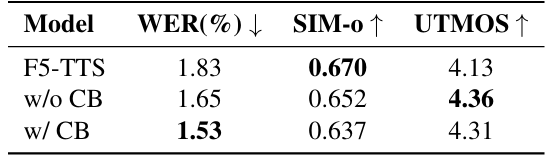
- Speaker, text guidance $\alpha_{spk}, \alpha_{txt}$를 통해 fine-grained control이 가능함

반응형
'Paper > TTS' 카테고리의 다른 글
댓글