

티스토리 뷰
Paper/Conversion
[Paper 리뷰] StarVC: A Unified Auto-Regressive Framework for Joint Text and Speech Generation in Voice Conversion
feVeRin 2025. 7. 3. 17:00반응형
StarVC: A Unified Auto-Regressive Framework for Joint Text and Speech Generation in Voice Conversion
- 기존의 Voice Conversion model은 linguistic content의 explicit utilization을 neglect 함
- StarVC
- Explicit text modeling을 voice conversion에 integrate
- Text token을 먼저 predict 한 다음 acoustic feature를 synthesize 하는 autoregressive framework를 활용
- 논문 (INTERSPEECH 2025) : Paper Link
1. Introduction
- Voice Conversion (VC)는 utterance의 linguistic content를 preserve 하면서 speaker identity를 modify 함
- 이를 위해서는 speech signal에서 speaker characteristic과 linguistic content를 decoupling 해야 함
- 특히 speaker-related feature와 비교하여 speech에서 semantic information은 WavLM, HuBERT, Wav2Vec 2.0 등을 통해 쉽게 추출됨
- 따라서 VC system이 semantic representation을 효과적으로 반영할 수 있다면 speaker characteristic과 linguistic content를 better disentangle 할 수 있음
- BUT, SEF-VC와 같은 기존 방식들은 textual content를 explicitly generate 하지 않고 latent text-based feature에 의존하므로 linguistic consistency에 대한 weaker constraint를 가짐
- 추가적으로 DualVC3와 같은 Large Language Model (LLM)-driven approach를 활용하면 long-form speech를 효과적으로 처리할 수 있음
- 즉, linguistic content를 explicitly modeling 하면서 speech synthesis를 수행하면 coherence와 intelligibility를 모두 향상할 수 있음
- 이를 위해서는 speech signal에서 speaker characteristic과 linguistic content를 decoupling 해야 함
-> 그래서 voice conversion과 text generation을 autoregressive structure에 unify 한 StarVC를 제안
- StarVC
- Acoustic feature를 생성하기 전에 text token을 predict 하는 intermediate step을 도입
- Structured semantic representation을 기반으로 synthesis를 수행하여 strong linguistic consistency를 제공함 - Multi-stage training을 채택하여 Automatic Speech Recognition (ASR)와 VC task를 jointly training
- Acoustic feature를 생성하기 전에 text token을 predict 하는 intermediate step을 도입
< Overall of StarVC >
- Semantic representation을 기반으로 text generation과 speech conversion을 jointly modeling 한 VC model
- 결과적으로 기존보다 뛰어난 성능을 달성
2. Method
- System Architecture
- StarVC는 autoregressive manner로 speech conversion과 text generation을 joint modeling 함
- 구조적으로는 Semantic Feature Extractor, Speaker Feature Extractor, Language Model, Acoustic Decoder를 가짐 - Semantic Feature Extractor
- 논문은 Whisper-Small의 encoder를 Semantic Encoder로 채택하여 source speech에서 high-level semantic feature를 추출함
- 해당 ASR model은 voice conversion에서 linguistic content를 capture 하기 위해 사용됨
- 먼저 source audio는 frame 수 $T_{m}$, mel-bin 수 $F_{m}$에 대해 mel-spectrogram $M_{s}\in\mathbb{R}^{T_{m}\times F_{m}}$으로 convert 되고,
- Semantic Encoder와 Semantic Adapter에 전달되어 semantic feature $S=\{s_{1},s_{2},...,s_{T}\},s_{i}\in\mathbb{R}^{dim}$을 얻음
- $T$ : semantic feature length, $dim$ : embedding dimension
- 먼저 source audio는 frame 수 $T_{m}$, mel-bin 수 $F_{m}$에 대해 mel-spectrogram $M_{s}\in\mathbb{R}^{T_{m}\times F_{m}}$으로 convert 되고,
- Speaker Feature Extractor
- Speaker Encoder의 경우 ERes2Net-Large를 사용하여 target speech에서 speaker-specific feature를 추출함
- 먼저 frame 수 $T_{f}$, FBank bin 수 $F_{f}$에 대해 FBank feature $B_{t}\in\mathbb{R}^{T_{f}\times F_{f}}$를 추출함
- 이후 Speaker Encoder, Speaker Adapter를 통해 speaker feature $S'=s'_{1}$을 얻음 ($s'_{1}\in\mathbb{R}^{dim}$)
- Autoregressive Language Model
- 논문은 acoustic token을 prior text token에 condition 하기 위해 MusicGen의 delay method를 적용함
- 여기서 모든 text token은 first acoustic token 보다 one step ahead에서 generate 되어 acoustic token이 generated text에 explicitly condition 되도록 함
- 추가적으로 teacher forcing strategy와 RoPE encoding을 도입하여 training effect를 optimize 함
- 결과적으로 LM은 추출된 semantic feature $S$와 speaker feature $S'$을 concatenate 하여 input으로 사용하고, 다음과 같이 output sequence를 생성함:
(Eq. 1) $Y=\text{LM}(S,S')=\{\hat{y}_{t},\hat{y}_{a_{1}},...,\hat{y}_{a_{n}}\}, \hat{y}_{t}\in\mathbb{R}^{V_{t}},\hat{y}_{a_{i}}\in\mathbb{R}^{V_{a}}$
- $n$ : codebook layer 수, $V_{t},V_{a}$ : 각각 text, acoustic token의 vocabulary size
- 논문은 acoustic token을 prior text token에 condition 하기 위해 MusicGen의 delay method를 적용함
- Acoustic Decoder
- Waveform reconstruction을 위해 논문은 Mimi를 사용함
- 특히 Mimi의 first layer는 WavLM에서 distill 되어 semantic information을 retain 하고 나머지 layer는 fine-grained acoustic detail을 encode 함 - 해당 multi-layer structure는 autoregressive text-acoustic generation과 combine 되어 naturalness를 향상함
- Waveform reconstruction을 위해 논문은 Mimi를 사용함

- Multi-Stage Training Strategy
- Text generation과 voice conversion을 effectively optimize 하기 위해 3-stage training strategy를 채택함
- 이때 모든 training stage에서 Semantic Encoder, Speaker Encoder, Acoustic Decoder는 frozen 됨
- 이를 통해 unnecessary parameter update를 방지하고 pre-trained representation을 preserve 함
- 이때 모든 training stage에서 Semantic Encoder, Speaker Encoder, Acoustic Decoder는 frozen 됨
- ASR Pretraining
- First stage에서 model은 Semantic Adapter와 LM을 update 하기 위해 ASR system으로 training 됨
- 이를 통해 subsequent voice conversion task에서 linguistic accuracy를 향상할 수 있는 robust semantic representation을 추출할 수 있음 - 이때 ASR loss는:
(Eq. 2) $\mathcal{L}_{ASR}=\text{CE}(y_{t},\hat{y}_{t})$
- $y_{t}$ : ground-truth transcription, $\text{CE}$ : cross-entropy
- First stage에서 model은 Semantic Adapter와 LM을 update 하기 위해 ASR system으로 training 됨
- VC Training
- Second stage에서는 linguistic accuracy를 preserve 하면서 speaker characteristic을 incorporate 하기 위해 Speaker Adapter, LM, Semantic Adapter를 update 함
- VC loss는 text, acoustic loss의 weighted combination으로 주어짐:
(Eq. 3) $ \mathcal{L}_{VC}=w\text{CE}(y_{t},\hat{y}_{t})+(1-w)\sum_{i=1}^{n}\lambda_{i}\text{CE} (y_{a_{i}},\hat{y}_{a_{i}})$
- $w$ : text, acoustic loss 간의 balance를 위한 weight
- $\lambda_{t}$ : 서로 다른 layer의 acoustic token loss를 adjust 하는 weight
- Joint ASR-VC Training
- Final stage에서는 ASR, VC task에 대해 model을 jointly training 함
- Training instance의 $20\%$는 ASR, $80\%$는 VC task에 allocate 됨 - 결과적으로 얻어지는 final loss는:
(Eq. 4) $\mathcal{L}=w'\mathcal{L}_{ASR}+(1-w')\mathcal{L}_{VC}$
- ASR, VC objective를 jointly optimize 함으로써 model은 linguistic accuracy와 speaker identity retention을 balance 하고 high-quality voice conversion을 지원할 수 있음
- Final stage에서는 ASR, VC task에 대해 model을 jointly training 함

- Parallel Data Augmentation
- Speaker diversity를 향상하기 위해 논문은 OpenVoice2를 사용하여 서로 다른 speaker의 동일한 utterance를 multiple variation으로 synthesize 함
- Training 중에는 real/synthesized speech를 target audio로 randomly select 하여 model의 robustness를 향상함
3. Experiments
- Settings
- Results
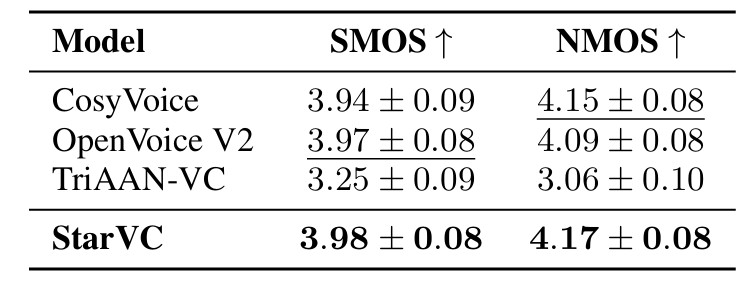
- 전체적으로 StarVC는 뛰어난 성능을 달성함

- MOS 측면에서도 우수한 성능을 보임
반응형
'Paper > Conversion' 카테고리의 다른 글
댓글