

티스토리 뷰
Paper/ASR
[Paper 리뷰] Whisper: Robust Speech Recognition via Large-Scale Weak Supervision
feVeRin 2025. 3. 1. 13:48반응형
Whisper: Robust Speech Recognition via Large-Scale Weak Supervision
- Audio transcripting을 위해 large data로 speech processing system을 training 할 수 있음
- Whisper
- 680,000 hours의 multilingual, multitask supervision으로 model을 scaling
- Dataset에 대한 specific fine-tuning 없이도 뛰어난 accuracy, robustness를 달성
- 논문 (ICML 2023) : Paper Link
1. Introduction
- Speech recognition은 wav2vec 2.0의 unsupervised pre-training technique을 주로 활용함
- Unsupervised pre-training은 human label 없이 raw audio에서 directly learning 할 수 있으므로 unlabeled, large dataset을 활용할 수 있음
- 이를 통해 얻어진 pre-trained audio encoder는 speech의 high-quality representation을 학습할 수 있음
- BUT, purely unsupervised method로 인해 representation을 usable output에 mapping 하는 decoder가 존재하지 않으로 실제 speech recognition을 수행하기 위해서는 fine-tuning step이 필요함
- 따라서 complex process로 인해 usefulness가 저해되고, fine-tuning 과정에서의 generalization 문제가 존재함
- 해당 unsupervised pre-training method는 audio encoder의 quality 개선에는 유용하지만 dataset-specific fine-tuning protocol과 high-quality pre-trained decoder의 부재로 인해 robustness의 한계가 있음
- 즉, speech recognition system은 fine-tuning이나 deployment에 관계없이 안정적으로 동작할 수 있어야 함 - 한편 다양한 dataset/domain에서 supervised fashion으로 pre-train된 speech recognition system은 single source model 보다 higher robustness, generalizability를 가짐
- BUT, 해당 방식은 high-quality speech recognition dataset을 요구함
- Unsupervised pre-training은 human label 없이 raw audio에서 directly learning 할 수 있으므로 unlabeled, large dataset을 활용할 수 있음
-> 그래서 680,000 hours의 labeled audio data를 활용한 weakly supervised speech recognition model인 Whisper를 제안
- Whisper
- 680,000 hours의 large-scale labeled audio dataset을 활용해 speech recognition model을 weakly supervised pre-training
- English-only speech recognition task 외에도 multilingual, multitask model로 확장
< Overall of Whisper >
- Large-scale audio dataset을 활용한 weakly supervised speech recognition model
- 결과적으로 data-specific fine-tuning 없이도 기존보다 뛰어난 성능을 달성
2. Method
- Data Processing
- Sequence-to-Sequence model의 expressiveness를 활용해 utterance와 transcirbed form 간의 mapping을 학습하고, significant standardization이나 pre-processing 없이 transcript의 raw text를 predict 함
- 이를 통해 naturalistic transcriptions을 output 하기 위한 separate inverse text normalization step을 remove 할 수 있으므로 speech recognition pipeline을 simplify 할 수 있음
- 먼저 논문은 Internet으로부터 audio와 paired transcript로 구성된 dataset을 구축하여 diverse environment, recording setup, language, speaker를 가지도록 함
- 한편 audio quality는 robust training에는 도움이 되지만 transcript quality의 diversity는 beneficial 하지 않음
- 특히 raw dataset에는 subpar transcript가 다수 존재하므로 transcript quality를 향상하기 위해 automated filtering method를 적용함
- Internet 상의 transcript는 대부분 human-generated가 아니라 기존 ASR system의 output에 해당함
- 따라서 punctuation, capitalization 등에 대한 various heuristics를 활용하여 training dataset에서 machine-generated transcript를 detect, remove 함
- 기존의 ASR system에는 inverse text normalization이 포함되어 있지만, comma including과 같은 부분에서 detectable 함 - 추가적으로 VoxLingua107 dataset에서 training 된 model을 fine-tuning 한 audio language detector를 사용하여 spoken lanugage가 CLD2에 따라 transcript의 language와 match 되는지 확인함
- Match 되지 않는 경우, $\text{(audio, transcrpt)}$ pair를 speech recognition training dataset으로 사용하지 않음
- 대신 해당 pair를 $\text{X}\rightarrow \text{en}$ speech translation training dataset에 추가함 - 이후 transcript text의 fuzzy de-duping을 활용해 training dataset에서 duplication과 automatically generated content를 reduce 함
- 따라서 punctuation, capitalization 등에 대한 various heuristics를 활용하여 training dataset에서 machine-generated transcript를 detect, remove 함
- 논문은 audio file을 30s segment로 break 하여 해당 time segment 내에서 occur 되는 transcript의 subset과 pairing 함
- 이때 no speech segment를 포함한 모든 audio에서 training 하고 해당 segment를 Voice Activity Detection을 위한 training dataset으로 사용함 - Additional filtering pass의 경우, initial model을 training 한 다음 training data source에서 error rate에 대한 information을 aggregate 하고 high error rate와 data source size를 combine 하여 sorting 함
- 이후 해당 data source에 대한 manual inspection을 수행하여 low-quality data를 remove 함 - 추가적으로 contamination을 방지하기 위해 training dataset과 overlap 될 수 있는 TED-LIUM3 dataset에 대해 transcript-level de-duplication을 수행함
- Model
- Whisper는 speech recognition을 위해 large-scale supervised pre-training을 적용하는 것을 목표로 함
- 구조적으로는 encoder-decoder Transformer architecture를 채택함
- 이때 모든 audio는 16,000Hz로 resample 되고 80 channel log magnitude Mel-spectrogram representation은 10ms의 stride로 25ms window에서 compute 됨
- Feature normalization의 경우, pre-training dataset에서 approximately 0 mean, $[-1,1]$ range를 가지도록 input을 globally scale 함
- Encoder는 먼저 filter width가 3인 2개의 convolution layer와 GELU activation으로 구성된 small stem을 기반으로 해당 input representation을 processing 함
- 여기서 두 번째 convolution layer는 stride 2를 사용 - 이후 stem output에 Sinusoidal positional embedding을 add 한 다음, encoder Transformer block을 적용함
- Transformer는 pre-activation residual block을 사용하고 final layer normalization을 encoder output에 적용함 - Decoder는 learned positional embedding과 tied input-output token representation을 사용함
- Encoder/Decoder는 동일한 width, transformer block 수를 가짐
- Whisper는 English model에 GPT-2의 byte-level BPE text tokenizer를 도입함
- Multilingual model의 경우, GPT-2 BPE vocabulary는 english-only이므로 other language에 대한 token fragmentation을 방지하기 위해 vocabulary를 refit 함
- 구조적으로는 encoder-decoder Transformer architecture를 채택함

- Multitask Format
- Speech processing system은 speech recognition 외에도 voice activity detection, speaker diarization, inverse text normalization 등을 포함함
- 일반적으로는 separate pipeline으로 구성되지만 Whisper는 simplicity를 위해 entire pipeline을 single model로 지원함
- 이때 same input audio signal으로도 여러 task를 수행할 수 있으므로 task specification이 필요함
- 따라서 all task와 conditioning information을 decoder에 대한 input token sequence로 specify 함 - 추가적으로 longer-range context를 사용해 ambiguous audio를 resolve 할 수 있도록 transcript의 history text를 condition으로 training 함
- 여기서 일정 probability로 current audio segment를 preceding 하는 transcript text를 decoder context에 add 함
- 이때 same input audio signal으로도 여러 task를 수행할 수 있으므로 task specification이 필요함
- $\text{<|startoftranscript|>}$ token이 prediction beginning을 indicate 한다고 하자
- 먼저 Whisper는 training set의 각 language에 대한 token으로 represent 되는 spoken language를 predict 함
- Audio segment에 speech가 없는 경우, model은 $\text{<|nospeech|>}$ token을 predict 하도록 training 됨 - 다음 token은 $\text{<|transcribe|>},\text{<|translate|>}$ token과 같이 task를 specify 하고 해당 task에 대한 $\text{<|notimestamps|>}$ token을 포함하여 timestamp를 predict 할지 여부를 결정함
- 여기서 task와 desired format이 fully specified 되고 output token이 begin 됨
- 먼저 Whisper는 training set의 각 language에 대한 token으로 represent 되는 spoken language를 predict 함
- Timestamp prediction의 경우 current audio segment를 기준으로 predict 함
- 이후 모든 time을 Whisper의 time resolution과 match 되는 nearest 20ms로 quantize 한 다음, 각각에 대한 vocabulary에 additional token을 add 함
- 그런 다음 prediction을 caption token과 interleave 함
- Start time token은 각 caption text 이전에 predict 되고 end time token은 이후에 predict 됨 - Current 30s audio chunk에 transcript segment가 partially include 된 경우, timestamp mode에서 segmet의 start time token만 predict 함
- 이는 subsequent decoding이 해당 time에 align 된 audio window에서 수행되어야 함을 의미
- 그렇지 않은 경우, segment를 include 하지 않도록 truncate 함
- 최종적으로 $\text{<|endoftranscript|>}$ token을 add 함
- Previous context text에 대한 training loss만을 mask 하고 all other token을 predict 하도록 model이 training 됨
- 일반적으로는 separate pipeline으로 구성되지만 Whisper는 simplicity를 위해 entire pipeline을 single model로 지원함
- Training Details
- Whisper model은 39M에서 1550M parameter의 scale을 가짐
- 우선 training의 경우 AdamW, gradient norm clipping을 사용함
- 이때 first 2048 update에 대한 warm up 이후 linear learning rate는 0으로 decay 함
- 256 segment의 batch size를 사용하고 전체 dataset에 대한 2~3 pass인 $2^{20}$ update로 training
- Data augmentation이나 regularization은 사용하지 않고 large dataset을 통해 generalization, robustness를 달성함
- 추가적으로 Whisper는 speaker name에 대해 plausible-incorrect guess를 transcribe 하는 경향이 있음
- Training transcript에 speaker name이 포함되어 있는 경우가 많기 때문
- 따라서 speaker annotation이 포함되지 않은 transcript subset으로 Whisper를 fine-tuning 하여 해당 behavior를 remove 함
- 우선 training의 경우 AdamW, gradient norm clipping을 사용함


3. Experiments
- Settings
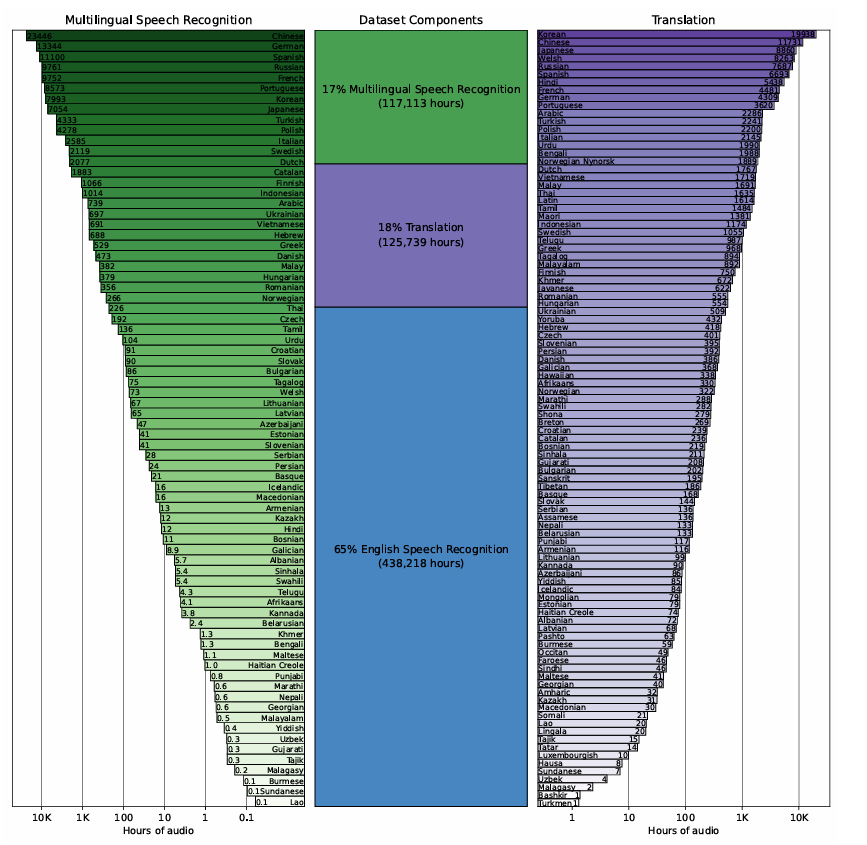
- Dataset : 아래 그림 참고
- Comparisons : wav2vec 2.0, XLS-R, mSLAM, Maestro
- Results
- English Speech Recognition
- English dataset에 대해 Whisper-Large V2는 wav2vec 2.0-Large 보다 우수한 WER을 보임
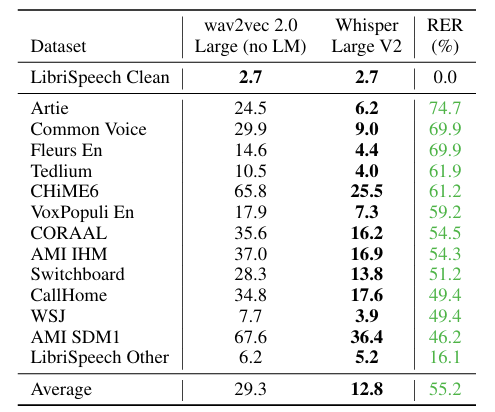
- Whisper는 human-level robustness, accuracy를 달성함

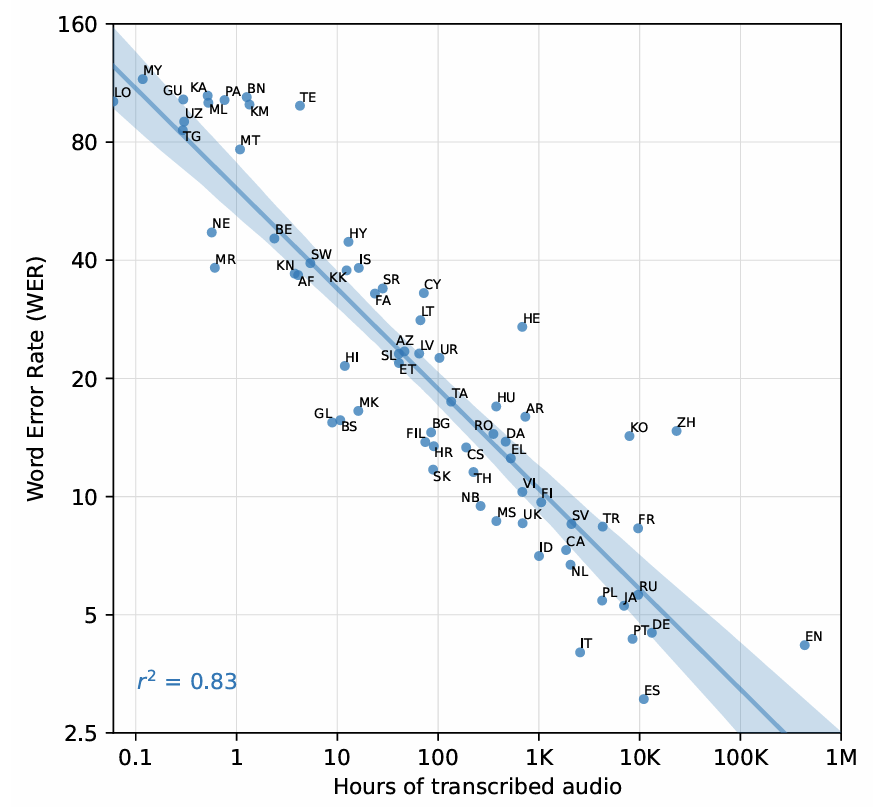
- Multilingual Speech Recognition
- Multilingual dataset에 대해 Whisper는 가장 높은 성능을 보임

- 특히 training data 양과 zero-shot performance 간의 relationship을 확인해 보면, WER과 training data 양의 $\log$ 간에는 0.83의 strong squared correlation이 존재함
- Translation
- $\text{X}\rightarrow \text{en}$ Translation 측면에서 Whisper는 29.1 BLEU의 성능을 달성함
- 특히 mSLAM과 비교하여 Whisper는 6.7 BLEU가 개선됨

- Language Identification
- Whisper는 language identification에서 Fleurs dataset의 overlapping language에 대해 80.3%의 accuracy를 달성함
- Analysis and Ablations
- Dataset Scaling
- $\text{X}\rightarrow \text{en}$ Translation task도 마찬가지로 dataset scale에 따라 성능이 개선됨

- Model Scaling
- Model size 역시 Whisper 성능과 비례함
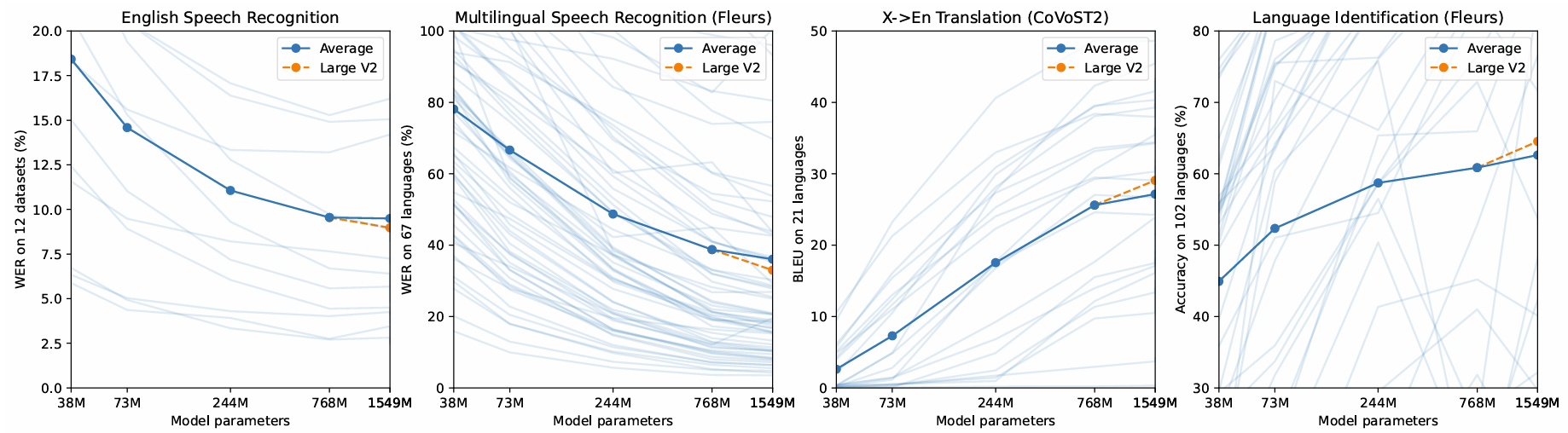
- Multitask and Multilingual Transfer
- Multitask, Multilingual model은 large model인 경우 English-only model 보다 높은 성능을 보임

반응형
'Paper > ASR' 카테고리의 다른 글
댓글