

티스토리 뷰
Paper/Conversion
[Paper 리뷰] EmoReg: Directional Latent Vector Modeling for Emotional Intensity Regularization in Diffusion-based Voice Conversion
feVeRin 2025. 6. 21. 08:34반응형
EmoReg: Directional Latent Vector Modeling for Emotional Intensity Regularization in Diffusion-based Voice Conversion
- Emotional Voice Conversion은 linguistic content는 preserve 하면서 source emotion을 주어진 target으로 convert 하는 것을 목표로 함
- EmoReg
- Emotion intensity를 control 하기 위해 Self-Supervised Learning-based feature representation을 활용
- 추가적으로 emotional embedding space에서 Unsupervised Directional Latent Vector Modeling을 도입
- 논문 (AAAI 2025) : Paper Link
1. Introduction
- Emotional speech synthesis는 여전히 intensity control, regularization 측면에서 한계가 있음
- 특히 Emotional Voice Conversion (EVC)는 linguistic content, speaker identity를 preserve 하면서 speech utterance의 discrete emotional state를 변환하는 것을 목표로 함
- 즉, 아래 그림과 같이 neutral utterance는 mild/moderate/severe-level의 emotion으로 convert 할 수 있음
- BUT, 기존 방식은 discrete approach를 활용하므로 continuous emotion representation을 확보하기 어려움
- 추가적으로 EVC를 위해서는 large emotional speech dataset의 부족 문제를 해결해야 함
- 이를 위해 Self-Supervised Learning (SSL) model을 고려할 수 있음
- 특히 Emotional Voice Conversion (EVC)는 linguistic content, speaker identity를 preserve 하면서 speech utterance의 discrete emotional state를 변환하는 것을 목표로 함

-> 그래서 discrete emotion-based EVC의 emotion intensity regularization을 향상한 EmoReg를 제안
- EmoReg
- Large annotated emotional speech dataset 문제를 해결하기 위해 SSL-based framework를 채택
- Diffusion-based EVC model을 기반으로 intensity control을 지원하는 Direction Vector Modeling을 도입
< Overall of EmoReg >
- SSL representation과 Direction Latent Vector Modeling을 활용한 diffusion-based EVC model
- 결과적으로 기존보다 뛰어난 conversion 성능과 emotion controllability를 달성
2. Method
- Problem Formulation
- Reference emotion speech $x_{r}$, input speech $x_{0}$, intensity value $i$가 주어지면,
- EVC는 $Y=G(X_{0},e_{s},e_{r},i;\theta)$와 같이 emotional intensity regularized converted speech $y$를 생성하는 것을 목표로 함
- $X_{0},Y$ : 각각 input speech $x_{0}$, converted emotional speech $y$의 mel-spectrogram
- $e_{s},e_{r}$ : 각각 source, reference speech에 대한 emotional feature representation - 이때 $\theta$는 conditional diffusion probabilistic model-based EVC에 대한 model parameter를 의미함
- EVC는 $Y=G(X_{0},e_{s},e_{r},i;\theta)$와 같이 emotional intensity regularized converted speech $y$를 생성하는 것을 목표로 함
- EmoReg Architecture
- EmoReg는 emotion intensity $i$를 control 하면서 EVC를 수행하기 위해 diffusion-based model을 활용함
- 구조적으로는 diffusion-based decoder와 encoder로 구성됨
- Diffusion decoder는 emotion-controllable speech synthesis를 수행하고 encoder는 disentanglement 되어야 하는 emotion, speech representation을 encode 함
- 이때 decoder는 서로 다른 emotion에 대한 transition을 지원하는 Direction Vector Modeling (DVM)-based feature $e_{ir}$에 의해 condition 됨
- Diffusion decoder output은 mel-spectrogram $Y$를 제공하고, HiFi-GAN vocder $H(\cdot)$을 통해 $y=H(Y)$와 같이 output speech signal로 convert 됨
- 구조적으로는 diffusion-based decoder와 encoder로 구성됨
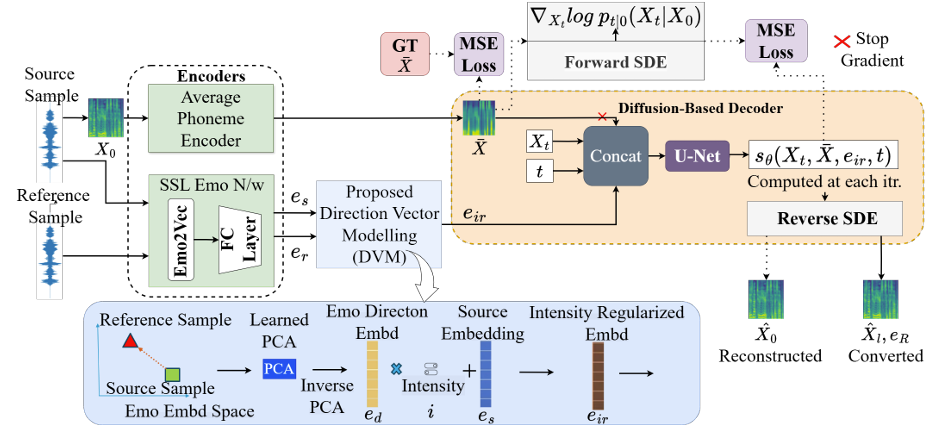
- Encoders
- EmoReg는 lexical content, emotion representation에 대한 2가지 encoder를 활용함
- Phoneme Encoder
- 먼저 논문은 speaker-/emotion-independent average phoneme-level mel-characteristic을 사용하여 phoneme-level에서 lexical content를 encode 함
- 이때 Transformer-based encoder를 채택하여 다음과 같이 modeling 함:
(Eq. 1) $\bar{\mathbf{X}}=\phi(\mathbf{X}_{0})$
- $\bar{\mathbf{X}}$ : source audio의 average mel-spectrogram, $\mathbf{X}_{0}$ : source speech mel-spectrogram
- $\phi(\cdot)$ : pre-trained average phoneme encoder
- SSL Emotion Embedding Network
- Large annotated emotional speech dataset은 확보하기 어려우므로, 논문은 SSL-based representation을 사용함
- 이때 pre-trained Emotion2Vec embedding network $E(\cdot)$을 fine-tuning 하여 768-dimensional emotional embedding representation을 얻음 - 한편으로 high dimensional embedding space에서 denoising task의 insufficient noise는 detoriation으로 이어짐
- 따라서 논문은 해당 embedding을 fully-connected layer를 통해 256-dimension으로 reduce 함
- 이후 reduced embeddding을 output layer에 전달하여 target emotion을 classify 함
- Training은 supervised manner로 수행됨
- Training 이후에는 fully-connected layer를 통해 256-dimensional emotion embedding을 얻을 수 있음
- 해당 emotional embedding은 converted output에서 target emotional state를 반영하기 위해 diffusion decoder에 conditioning 되고, intensity fine-control을 위해 Direction Vector Modeling을 통해 manipulate 됨
- Large annotated emotional speech dataset은 확보하기 어려우므로, 논문은 SSL-based representation을 사용함
- Direction Vector Modeling
- Training phase에서 앞선 256-dimensional emotional embedding은 DVM module input으로 사용됨
- 논문은 각 emotion에 대한 local mean vector를 derive 하기 위해 64-component Gaussian Mixture Model (GMM)을 사용하여 emotion embedding space를 modeling 함
- 이후 각 emotion에 대한 GMM feature를 추출하고, Angry/Happy/Sad embedding과 Neutral embedding 간에 pairwise substraction을 수행함
- 이를 통해 하나의 emotional state에서 다른 emotional state로의 all possible transition에 대한 emotional direction vector matrix를 얻음 - 다음으로 Principal Component Analysis (PCA)를 각 emotion에 대한 emotional direction matrix에 적용함
- 이를 통해 256 component를 128 component로 reduce 함
- 이후 각 emotion에 대한 GMM feature를 추출하고, Angry/Happy/Sad embedding과 Neutral embedding 간에 pairwise substraction을 수행함
- 추론 시에는 Neutral emotion의 source sample과 다른 emotion의 reference sample이 주어짐
- 이때 emotional direction vector는 source neutral embedding $e_{s}$에서 reference emotional embedding $e_{r}$을 substracting 하여 얻어짐
- 해당 direction vector는 PCA를 통해 128-dimensional vector로 convert 된 다음, inverse PCA를 통해 original 256-dimensional space로 convert back 되어 final emotional reference embedding $e_{d}$를 얻음
- Emotional reference embedding은 intensity value $i$에 해당하는 specified factor로 scale 됨
- Scale factor는 $[0,1]$ range를 가지고, source embedding $e_{s}$에 add 되어 embedding space에서 reference emotion $e_{ir}$ 쪽으로 shift 함 - 최종적으로 reverse Stochastic Differential Equation (SDE)는 scaled embedding에 condition 되어 emotion intensity value로 regulate 된 reference target emotion을 가지는 output speech를 생성함
- 논문은 각 emotion에 대한 local mean vector를 derive 하기 위해 64-component Gaussian Mixture Model (GMM)을 사용하여 emotion embedding space를 modeling 함

- Diffusion-based Decoder
- Diffusion-based Deocder는 Grad-TTS의 SDE formulation을 따름
- 먼저 continuous diffusion time-step variable $t$는 diffusion process의 progression을 characterize 함
- 그러면 $0<t\leq 1$에 대한 forward SDE는:
(Eq. 2) $d\mathbf{X}_{t}=\frac{1}{2}\beta_{t}\left(\bar{\mathbf{X}}-\mathbf{X}_{t}\right)dt +\sqrt{\beta_{t}}d\mathbf{w}$
- $\mathbf{X}_{t}$ : current process state, $\mathbf{X}_{0}$ : initial condition
- $\mathbf{w}$ : Wiener process, $\beta_{t}$ : noise schedule로써, non-negative function - Mean evolution은 $t=1$에서 average phoneme characteristic $\bar{\mathbf{X}}$ distribution으로 roughly end 되고, $t=0$에서 source $\mathbf{X}_{0}$ distribution으로 begin 하는 interpolation을 represent 함
- Forward SDE에 대한 reverse SDE는:
(Eq. 3) $d\mathbf{X}_{t}=\left[-\frac{1}{2}\beta\left(\bar{\mathbf{X}}-\mathbf{X}_{t}\right) +\beta_{t}\nabla_{\mathbf{X}_{t}}\log p_{t}\left(\mathbf{X}_{t}|\bar{\mathbf{X}}\right)\right]dt +\beta_{t}d\bar{\mathbf{w}}$
- $d\bar{\mathbf{w}}$ : reverse Wiener process
- 여기서 noise $\beta_{t}=\beta_{0}+t(\beta_{1}-\beta_{0})$는 $\beta_{0},\beta_{1}$ 모두에 대해 linear schedule을 따르고, $e^{-\int_{0}^{1}(\beta_{s}ds)}$는 0으로 수렴함 - Reverse SDE는 forward SDE와 동일한 trajectory를 가짐
- 즉, average voice의 distribution에서 begin 하여 $t=0$에서 source target의 distribution으로 end 함
- 그러면 $0<t\leq 1$에 대한 forward SDE는:
- 한편으로 논문은 score model $s_{\theta}$로써 U-Net architecture를 사용함
- 이때 score model은 $\mathbf{X}_{t},t$와 regulated emotion intensity feature $e_{ir}=f(e_{s},e_{r},i)$를 사용함
- $f(\cdot)$ : DVM function - 이를 통해 emotion intensity regularized embedding $e_{ir}$이 주어지면, learned $s_{\theta}(\mathbf{X}_{t},\bar{\mathbf{X}},t,e_{ir})$을 가지는 reverse SDE를 사용하여 average voice $\bar{\mathbf{X}}$로부터 reconstructed $\mathbf{X}_{0}$를 estimate 할 수 있음
- 이때 score model은 $\mathbf{X}_{t},t$와 regulated emotion intensity feature $e_{ir}=f(e_{s},e_{r},i)$를 사용함
- 추론 시에는 neutral emotion의 source sample이 reference sample의 specified target emotion으로 convert 됨
- Source emotional embedding, reference emotional embedding은 DVM input으로 사용되고, DVM은 direction vector를 modeling 하고 emotion intenisty regularized embedding을 생성함
- 해당 embedding과 learned score function은 source sample을 reference sample emotion으로 transform 하는 데 사용됨
- 먼저 continuous diffusion time-step variable $t$는 diffusion process의 progression을 characterize 함
3. Experiments
- Settings
- Dataset : Emotional Speech Dataset (ESD)
- Comparisons : EmoVox, Mixed Emotion, CycleGAN-EVC, StarGAN-EVC, StyleVC, DISSC, Seq2Seq-EVC
- Results
- Objective evaluation 측면에서 EmoReg가 가장 우수한 성능을 달성함

- WER, CER 측면에서도 EmoReg가 가장 뛰어난 성능을 보임

- Subjective Evaluation
- 전체적으로 EmoReg의 MOS가 가장 뛰어남
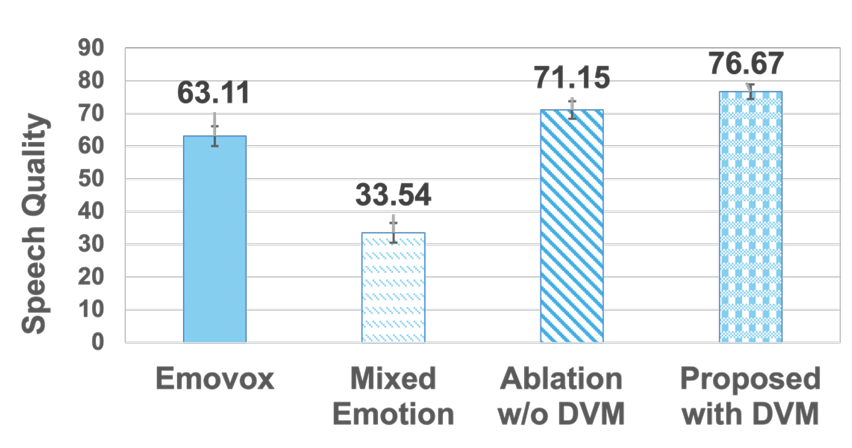
- Performance Across Language
- EmoReg는 서로 다른 language에 대해서도 high emotional similarity를 보임
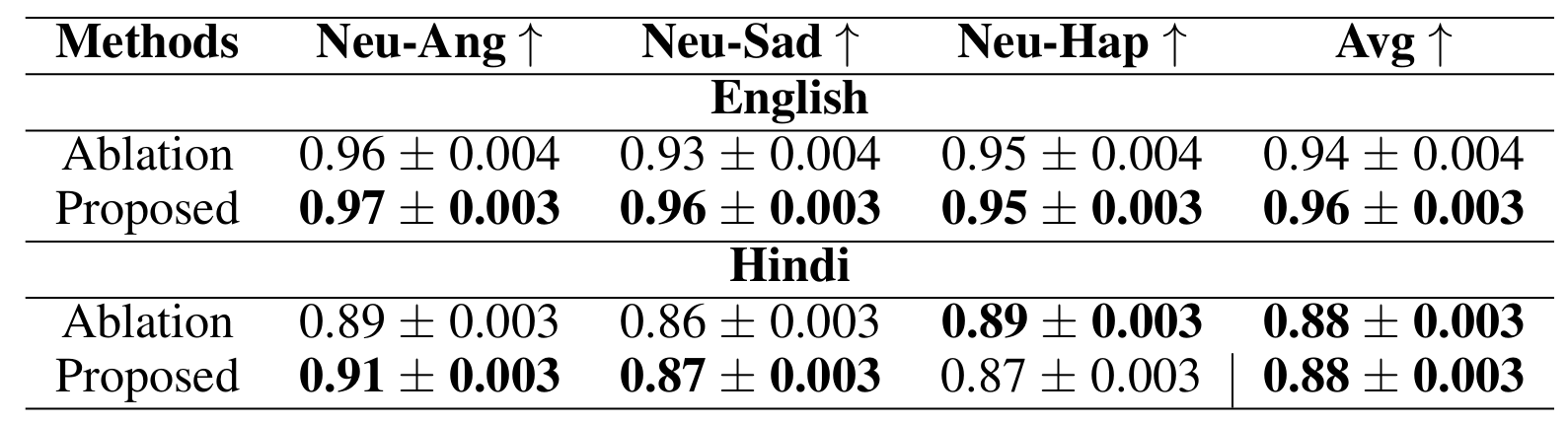
- Ablation Study
- 각 component를 제거하는 경우 CER, WER이 저하됨

- 특히 128 PCA component를 사용하는 경우 최적의 성능을 달성할 수 있음

- Visual Analysis
- Mel-spectrogram 측면에서 EmoReg는 emotion intensity를 효과적으로 control 함

반응형
'Paper > Conversion' 카테고리의 다른 글
댓글