

티스토리 뷰
Paper/Conversion
[Paper 리뷰] TriAAN-VC: Triple Adaptive Attention Normalization for Any-to-Any Voice Conversion
feVeRin 2024. 9. 10. 09:30반응형
TriAAN-VC: Triple Adaptive Attention Normalization for Any-to-Any Voice Conversion
- Voice Conversion은 source speech의 content를 유지하면서 target speaker의 characteristic을 반영해야 함
- TriAAN-VC
- Encoder-Decoder architecture와 attention-based adaptive normalization block으로 구성된 Triple Adaptive Attention Normalization을 활용
- Adaptive normalization block을 통해 target speaker representation을 추출하고 siamese loss로 최적화를 수행
- 논문 (ICASSP 2023) : Paper Link
1. Introduction
- Voice Conversion (VC)는 source speech content를 유지하면서 target speaker로 변환하는 것을 목표로 함
- 이를 위해 대부분의 방식들은 utterance를 content, speaker representation으로 disentangle 함
- VQVC+와 같은 vector quantization 방식은 discrete code로 content를 represent 하므로 time relationship을 reduce 하는 경향이 있음
- S2VC, FragmentVC와 같은 attention-based 방식은 speaker representation에 overly detailed 되는 문제가 있음
- AdaIN-VC, AGAIN-VC와 같은 instance normalization 방식은 speaker characteristic을 충분히 반영하지 못함
- BUT, 기존 방식들은 overly detailed/generalized representation을 사용하므로 content maintain, speaker similarity에 대한 trade-off가 발생함
- 이를 위해 대부분의 방식들은 utterance를 content, speaker representation으로 disentangle 함
-> 그래서 VC 성능에 대한 trade-off 문제를 완화하기 위해 core speaker representation을 활용하는 TriAAN-VC를 제안
- TriAAN-VC
- Encoder-Decoder architecture를 기반으로 content, speaker representation을 disentangle
- Triple Adaptive Attention Normalization (TriAAN) block을 도입하여 disentangled feature에서 detailed, global representation을 추출하고 conversion을 위해 adaptive normalization을 적용
- Time masking이 있는 siamese loss를 활용하여 source content preserving을 향상
- Encoder-Decoder architecture를 기반으로 content, speaker representation을 disentangle
< Overall of TriAAN-VC >
- Encoder-Decoder architecture를 기반으로 TriAAN block과 siamese loss를 적용
- 결과적으로 기존보다 뛰어난 conversion 성능을 달성
2. Method
- Feature Extraction
- S2VC의 Contrastive Predictive Coding (CPC)는 VC 성능을 크게 향상할 수 있으므로, TriAAN-VC도 마찬가지로 CPC feature를 input으로 사용함
- 이때 pre-trained model을 사용하여 raw audio $x_{raw}\in\mathbb{R}^{t}$로부터 CPC feature $x\in\mathbb{R}^{H\times T}$를 추출
- $H, T$ : 각각 $x$의 hidden size, segment length, $t$ : $x_{raw}$의 signal length - 추가적으로 source speaker의 pitch information을 represent 하기 위해, VQMIVC와 같이 DIO algorithm을 $x_{raw}$에 적용하여 log fundamental frequency $x_{f0}\in\mathbb{R}^{T}$를 추출
- 이때 pre-trained model을 사용하여 raw audio $x_{raw}\in\mathbb{R}^{t}$로부터 CPC feature $x\in\mathbb{R}^{H\times T}$를 추출
- Encoder and Decoder
- TriAAN-VC는 content, speaker information을 각각 추출하는 2개의 encoder와 decoder로 구성됨
- Encoder, decoder는 bottleneck layer를 통해 연결되고 각각 $L$개의 layer를 가짐
- 먼저 encoder 이전에 $x_{c,s}\in\mathbb{R}^{H\times T}_{c,s}$에 convolution layer를 적용하여 $H$를 channel size $C$로 expand 함
- $x_{c,s}$ : feature extraction 이후의 content, speaker input - Encoder
- 각 encoder layer는 convolution block과 Instance Normalization (IN)으로 구성됨
- 추가적으로 Speaker Attention (SA)는 speaker encoder에서만 사용됨 - Convolution block은 kernel size가 3이고 stride가 1인 2개의 convolution layer를 가지는 residual block
- 각 encoder layer는 convolution block과 Instance Normalization (IN)으로 구성됨
- Bottleneck Layer
- Encoder process 이후, source speaker의 $x_{f0}\in\mathbb{R}^{T}$를 사용하여 pitch를 represent 함
- 다음으로 $x'_{c}, x_{f0}$ 간의 concatenated output에 GRU layer를 적용함
- $x'_{c}\in\mathbb{R}^{C\times T}$ : content encoder output - 이후 decoder 이전에 Dual Adaptive Normalization (DuAN)을 speaker, content representaiton에 적용하여 initial converted representation을 생성함
- Decoder
- Decoder는 encoder와 동일한 convolution block과 TriAAN block을 사용하여 구성됨
- TriAAN block은 previous layer의 content feature와 speaker encoder layer의 feature map을 사용하여 conversion을 수행 - 최종적으로 decoder output은 GRU와 PostNet을 통해 refine 되어 log mel-spectrogram $\hat{y}\in\mathbb{R}^{M\times T}$를 예측함
- $M$ : mel bin 수
- Decoder는 encoder와 동일한 convolution block과 TriAAN block을 사용하여 구성됨

- Speaker Attention
- Adaptive Instance Normalization (AdaIN)은 speaker representation의 channel-wise statistics를 활용하므로 speaker의 core channel feature를 추출할 수 있어야 함
- 따라서 논문은 IN을 Time-wise IN (TIN)으로 변경하고 TIN-based Speaker Attention (SA)를 설계
- 이때 TIN은 channel relation을 preserving 하면서 time-wise 평균, 표준편차로 normalize 됨 - SA는 다음과 같이 TIN과 self-attention을 활용함:
(Eq. 1) $Q=\text{TIN}(x_{s})W_{q},\,\, K=x_{s}W_{k},\,\, V=x_{s}W_{v}$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, \text{Attention}(Q,K,V)=\text{softmax}\left(QK^{\top}/\sqrt{d}\right)V$
- $x_{s}\in\mathbb{R}^{T\times C}, W_{q,k,v}\in\mathbb{R}^{C\times C}$ : 각각 speaker feature, weight - 결과적으로 SA는 query information을 TIN result로 사용하여 conversion을 위한 speaker information의 channel relation을 preserve 하고 강조함
- 따라서 논문은 IN을 Time-wise IN (TIN)으로 변경하고 TIN-based Speaker Attention (SA)를 설계
- TriAAN Block
- TriAAN block은 Dual Adaptive Normalization (DuAN)과 Global Adpative Normalization (GLAN)으로 구성됨
- 먼저 TriAAN block은 각 $l$-th speaker encoder layer에서 얻어진 feature map $F_{s}^{1:L}\in \mathbb{R}_{1:L}^{T\times C}$를 사용함
- $l=1,2,...,L$ - DuAN은 dual view (time, channel)에서 $F_{s}^{l}$의 layer-wise detailed speaker feature를 추출한 다음 adpative normalization을 적용함
- GLAN은 speaker encoder의 모든 feature map을 사용하여 global speaker information을 추출함
- DuAN
- DuAN은 detailed speaker feature를 추출하기 위해 도입되어 layer-wise speaker feature $F_{s}^{l}$의 attention-based statistics를 represent 함
- Previous layer의 content feature가 $x_{c}\in\mathbb{R}^{T\times C}$이고 normalization function이 $\mathcal{N}(\cdot)$일 때, attention weight $\alpha\in \mathbb{R}^{T\times T}$, attention-weighted mean $M\in\mathbb{R}^{T\times C}$, variance $Var\in\mathbb{R}^{T\times C}$는:
(Eq. 2) $Q=\mathcal{N}(x_{c})W_{q},\,\,K=\mathcal{N}(F_{s}^{l})W_{k},\,\,V=F_{s}^{l}W_{v}$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, \alpha=\text{softmax}\left(QK^{\top}/\sqrt{d}\right)$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, M=\alpha V, \,\, Var=\alpha(V\cdot V)-M\cdot M$
- $W_{q,k,v}\in\mathbb{R}^{C\times C}$ : linear transformation에 대한 weight - Normalized feature로 얻어진 $\alpha$는 content, speaker feature 간의 similarity를 나타내고, $Var$는 variable에 대한 기댓값과 기댓값의 제곱으로 계산됨
- $\alpha$를 적용하면 weighted mean, standard deviation에 detailed speaker feautre인 per-point statistics가 포함될 수 있음
- 따라서 overly detailed speaker feature로 인한 biased result를 방지하기 위해, $M, Var$에 대한 time-wise average를 구하고 $Var$에 square root를 적용하여 standard deviation $S\in\mathbb{R}^{C}$를 구함 - 결과적으로 adaptive normalization과 content feature로 얻어진 converted representation $x'_{c}\in\mathbb{R}^{T\times C}$는 $x'_{c}=\text{IN}(x_{c})S+M$으로 얻어짐
- 이때 channel, time 측면에서 $\mathcal{N}(\cdot)$ function인 IN, TIN에 따라 adaptive normalization을 분리하여 2개의 converted representation을 얻음
- GLAN
- GLAN은 global speaker information을 represent 하기 위해 speaker encoder의 모든 feature map $F_{s}^{1:L}$을 활용함
- Content feature $x_{c}\in\mathbb{R}^{C\times T}$의 경우, DuAN에서 얻어진 두 representation에 대한 channel-wise concatentation에 convolution layer를 적용하여 얻어짐
- 이후 $F_{s}^{1:L}$에서 layer-wise concatenated mean $\mu\in\mathbb{R}^{L\times C}$와 standard deviation $\sigma\in\mathbb{R}^{L\times C}$를 얻음
- $\mu=\left[\text{avg}(F_{s}^{1});...;\text{avg}(F_{s}^{L})\right], \,\,\, \sigma=\left[\text{std}(F_{s}^{l});...;\text{std}(F_{s}^{L})\right]$ - 추가적으로 adaptive normalization을 위해 global speaker feature $\mu, \sigma$에서 core statistics를 추출하고 강조하는 self-attention pooling을 적용
- 그러면 weighted mean $\mu'\in\mathbb{R}^{C}$와 standard deviation $\sigma'\in\mathbb{R}^{C}$는 attention pooling을 통해 다음과 같이 얻어짐:
(Eq. 3) $\alpha_{\mu}=\text{softmax}(\mu W_{\mu}),\,\,\alpha_{\sigma}=\text{softmax}(\sigma W_{\sigma})$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, \mu'=\text{sum}(\mu\times\alpha_{\mu}),\,\,\sigma'=\text{sum}(\sigma\times\alpha_{\sigma})$
- $\alpha_{\mu,\sigma}\in\mathbb{R}^{L}_{\mu,\sigma}, W_{\mu,\sigma}\in\mathbb{R}_{\mu,\sigma}^{C\times C}$ : 각각 attention weight, transformation weight - 결과적으로 GLAN은 DuAN과 같이 $\mu',\sigma'$을 사용하여 adaptive normalization을 적용한 다음, conversion을 수행함
- 먼저 TriAAN block은 각 $l$-th speaker encoder layer에서 얻어진 feature map $F_{s}^{1:L}\in \mathbb{R}_{1:L}^{T\times C}$를 사용함

- Loss Function
- TriAAN-VC의 training을 위해 reconstruction loss와 siamese loss를 결합하여 사용함
- Reconstruction loss는 ground-truth mel-spectrogram $y\in\mathbb{R}^{M\times T}$와 predicted $\hat{y}\in\mathbb{R}^{M\times T}$ 간의 $L1$ loss
- 여기서 $y$는 mel-spectrogram transformation을 통해 raw audio에서 추출되고, $\hat{y}$는 input feature $x\in\mathbb{R}^{H\times T}$가 CPC feature일 때 model로부터 예측됨 - Siamese loss는 $y$와 $\hat{y}_{siam}\in\mathbb{R}^{M\times T}$ 간의 $L1$ loss로 계산됨
- $\hat{y}_{siam}$은 time masking으로 augment된 $x$를 사용하여 예측됨 - $L1$ loss를 $\text{loss}(y,\hat{y})=||y-\hat{y}||_{1}/T$라고 할 때, combined loss는:
(Eq. 4) $\mathcal{L}=\left(\text{loss}(y,\hat{y})+\text{loss}(y,\hat{y}_{siam})\right)/2+\text{loss} (\hat{y},\hat{y}_{siam})$
- $\hat{y}_{siam}$에 대한 additional loss를 계산함으로써 robustness, consistency를 향상 가능
- 특히 time masking은 training 중에 content information을 제거하므로 siamese loss는 content preserving을 향상하는데 도움을 줌
- Reconstruction loss는 ground-truth mel-spectrogram $y\in\mathbb{R}^{M\times T}$와 predicted $\hat{y}\in\mathbb{R}^{M\times T}$ 간의 $L1$ loss
3. Experiments
- Settings
- Results
- Comparison Results
- 전체적으로 TriAAN-VC가 가장 우수한 성능을 보임

- MOS 측면에서도 가장 뛰어난 naturalness와 similarity를 보임

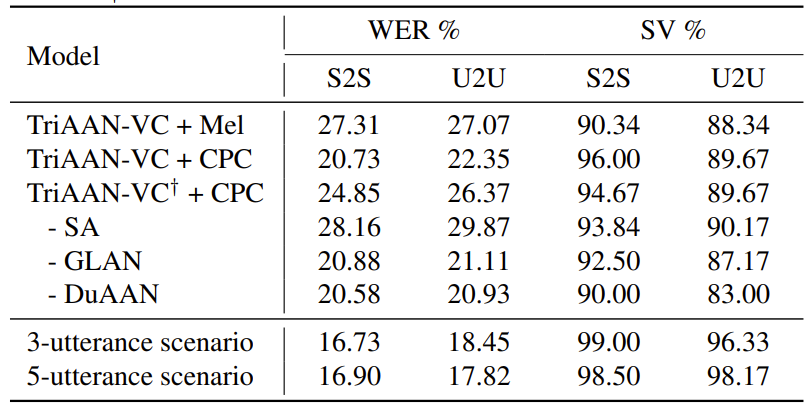
- Ablation Study
- TriAAN-VC의 각 component를 대체하는 경우 성능 저하가 발생함
반응형
'Paper > Conversion' 카테고리의 다른 글
댓글