

티스토리 뷰
Paper/Conversion
[Paper 리뷰] Neural Analysis and Synthesis: Reconstructing Speech from Self-Supervised Representations
feVeRin 2025. 5. 5. 09:42반응형
Neural Analysis and Synthesis: Reconstructing Speech from Self-Supervised Representations
- Information bottleneck에 기반한 synthesis control은 reconstruction quality 측면에서 한계가 있음
- NANSY
- Original input signal의 information을 perturb 하여 synthesis network가 input signal reconstruction을 위한 essential attribute를 selectively take 하도록 유도
- Wav2Vec feature와 pitch feature인 Yingram을 사용하여 fully self-supervised training을 지원
- 논문 (NeurIPS 2021) : Paper Link
1. Introduction
- 기존의 analysis and synthesis framework는 Linear Predictive Coding (LPC)와 같은 Digital Signal Processing (DSP)를 기반으로 함
- BUT, 해당 방식은 decomposed representation이 low-level representation이므로 controllability 측면에서 한계가 있음
- 즉, controllability를 위해서는 signal이 high-level interpretable representation으로 decompose 되어야 함 - 한편으로 Voice Conversion (VC) 측면에서 text-based/information bottleneck approach를 고려할 수 있음
- Text-based approach는 text modality가 speaker identity와 disentangle 되어 있다는 점을 활용함
- 주로 pre-trained Automatic Speech Recognition (ASR) network를 활용하여 representation을 추출하지만, 해당 ASR model에 의존적이라는 한계가 있음 - AutoVC, VQVC+와 같은 information bottleneck approach의 경우 time/channel dimension을 reduce 하고 intermediate representation을 normalize/quantize 하여 information flow를 restrict 함
- BUT, disentanglement와 reconstruction quality 간에 trade-off가 존재함
- Text-based approach는 text modality가 speaker identity와 disentangle 되어 있다는 점을 활용함
- BUT, 해당 방식은 decomposed representation이 low-level representation이므로 controllability 측면에서 한계가 있음
-> 그래서 speech signal을 효과적인 analysis feature로 decompose 할 수 있는 NANSY를 제안
- NANSY
- Text information 없이 linguistic information을 preserve 하는 Wav2Vec 2.0과 controllable pitch information을 위한 Yingram을 통해 analysis feature를 구성
- 각 analysis feature의 common information을 disentangle 하기 위해 information perturbation을 도입
- 추가적으로 unseen language에 대한 adaptation을 위해 Test-Time Self-Adaptation (TSA)를 적용
- Text information 없이 linguistic information을 preserve 하는 Wav2Vec 2.0과 controllable pitch information을 위한 Yingram을 통해 analysis feature를 구성
< Overall of NANSY >
- Wav2Vec 2.0, Yingram을 활용해 fully self-supervised manner로 training 되는 neural analysis and synthesis framework
- 결과적으로 기존보다 뛰어난 reconstruction 성능을 달성

2. Method
- Analysis Features
- Linguistic
- Intelligible speech를 reconstruct 하기 위해서는 speech signal에서 rich linguistic information을 추출해야 함
- 따라서 논문은 53 language로 pre-training 된 Wav2Vec 2.0인 XLSR-53을 채택함 - 이때 XLSR-53은 language-agnostic linguistic information을 얻기 위해서는 적절한 layer를 선택해야 함
- Wav2Vec 2.0의 layer representation은 서로 다른 characteristic을 가지기 때문 - 경험적으로 middle layer output은 pronunciation characteristic을 가지므로 XLSR-53의 24-layer Transformer encoder에 대한 12-th layer output을 활용함
- Intelligible speech를 reconstruct 하기 위해서는 speech signal에서 rich linguistic information을 추출해야 함
- Speaker
- Speaker embedding을 추출하기 위해서는 AutoVC와 같이 supervised manner로 speaker recognition network를 training 해야 함
- 여기서 논문은 speaker label이 없는 경우로 NASNY를 확장하기 위해 self-supervised manner로 speaker recognition network를 training 함
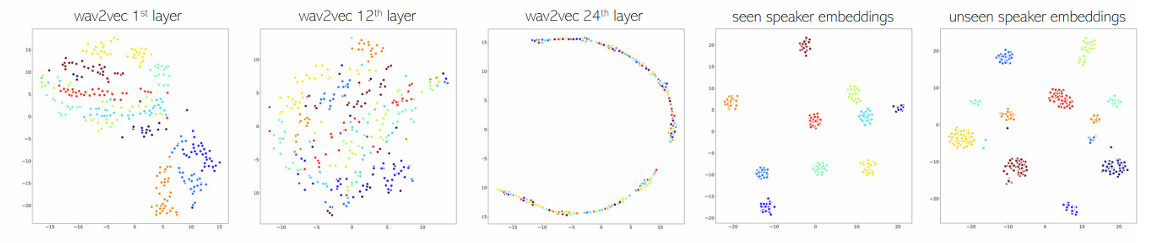
- 따라서 XLSR-53 representation을 활용하여 fully self-supervised model을 구성함 - 이때 적절한 layer를 결정하기 위해 XLSR-53의 각 representation에 $t$-SNE를 적용해 보면:
- 아래 그림과 같이 1-st layer는 speaker에 대한 cluster를 가지지만 이후의 12-th, 24-th layer는 speaker cluster가 나타나지 않음
- 따라서 논문은 XLSR-53의 1-st layer를 input으로 사용하는 speaker embedding network를 training 함
- 구조적으로 speaker embedding network는 1D-CNN에 기반한 speaker recognition network인 ECAPA-TDNN을 채택함
- 추가적으로 speaker embedding은 conditioning 이전에 $L2$-normalize됨
- Pitch
- Glottal pulse의 irregular periodicity로 인해 creaky voice가 나타날 수 있고, 이는 signal에서 jitter나 sub-harmonics로 나타남
- 이 경우 fundamental frequency $f_{0}$가 well-define 되지 않으므로 $f_{0}$ tracker를 통해 estimate 하기 어려움 - 따라서 논문은 Yin algorithm에 기반하여 해당 문제를 해결함
- 먼저 Yin algorithm은 cumulative mean normalized difference function $d'_{t}(\tau)$를 사용하여 raw-waveform으로부터 frame-wise feature를 추출함:
(Eq. 1) $ d'_{t}(\tau)=\left\{\begin{matrix}
1, & \text{if}\,\,\tau=0 \\
d_{t}(\tau)/\sum_{j=1}^{\tau}d_{t}(j), & \text{otherwise} \\
\end{matrix}\right.$ - $d_{t}(\tau)$는 time-lag $\tau$에 periodicity가 존재할 때 small value를 output 하는 difference function으로써:
(Eq. 2) $d_{t}(\tau)=\sum_{j=1}^{W}(x_{j}-x_{j+\tau})^{2}=r_{t}(0)+ r_{t+\tau}(0)-2r_{t}(\tau)$
- $t,\tau,W,r_{t}$ : 각각 frame index, time-lag, window size, auto-correlation function - 이후 post-processing step을 통해 Yin algorithm은 multiple $f_{0}$ candidate에서 $f_{0}$를 select 함
- 먼저 Yin algorithm은 cumulative mean normalized difference function $d'_{t}(\tau)$를 사용하여 raw-waveform으로부터 frame-wise feature를 추출함:
- 여기서 논문은 $f_{0}$를 explicitly select 하지 않고 function $d'_{t}(\tau)$의 output에서 pitch harmonics를 생성하도록 network를 training 함
- BUT, $d'_{t}(\tau)$는 $f_{0}$와 달리 controllability가 부족하므로 pitch feature로 사용하기 어려움
- 따라서 time-lag-axis를 midi-scale-axis로 변환한 Yingram $Y$를 사용함:
(Eq. 3) $Y_{t}(m)=\frac{d'_{t}\left( \lceil \text{c}(m)\rceil\right)-d'_{t}\left(\lfloor \text{c}(m)\rfloor\right) }{\lceil \text{c}(m)\rceil-\lfloor \text{c}(m)\rfloor}\cdot \left(\text{c}(m)-\lfloor \text{c}(m)\rfloor \right)+d'_{t}\left(\lfloor \text{c}(m)\rfloor \right)$
(Eq. 4) $\displaystyle{\text{c}(m)=\frac{\text{sr}}{440\cdot 2^{\left(\frac{m-69}{12}\right)}}}$
- $m,\text{c}(m), \text{sr}$ : 각각 midi-note, midi-to-lag conversation function, sampling rate
- 이때 semitone range를 reprsent 하기 위해 20-bin Yingram을 사용하고 $W=2048$, $22\leq \tau \leq 2047$로 설정하여 10.77hz에서 1000.40hz의 frequency를 represent 하도록 함
- Training 시 synthesis network input은 아래 그림과 같이 25.11hz에서 430.19hz의 frequency range를 가지고, 추론 시에는 scope를 shift 하여 pitch를 변경할 수 있음
- e.g.) 20-bin 만큼 scope down 하면 pitch는 semitone만큼 raise 됨
- Glottal pulse의 irregular periodicity로 인해 creaky voice가 나타날 수 있고, 이는 signal에서 jitter나 sub-harmonics로 나타남
- Energy
- Energy의 경우 frequency-axis를 따라 log-mel-spectrogram에 대한 average를 취함

- Synthesis Network
- 논문은 source-filter theory를 따라 synthesis network를 source generator $\mathcal{G}_{S}$와 filter generator $\mathcal{G}_{F}$로 separate 함
- Energy, speaker feature는 $\mathcal{G}_{S}, \mathcal{G}_{F}$에 대한 common input으로 사용되는 대신, 각각은 Yingram과 Wav2Vec feature를 사용함
- 이때 acoustic feature는 log-magnitude domain에서 source/filter의 summation으로 취급할 수 있으므로 각 generator output을 summing 하여 inductive bias를 incorporate 함
- 이를 통해 training loss가 mel-spectrogram을 기반으로 정의되더라도 network는 아래 그림과 같이 spectral envelope와 pitch harmonics를 separately generate 할 수 있음
- 해당 separation을 통해 NANSY는 formant preserving과 pitch shifting이 가능함
- 결과적으로 acoustic feature인 mel-spectrogram $\hat{M}$은 다음과 같이 생성됨:
(Eq. 5) $\hat{M}=\mathcal{G}_{S}(\text{Yingram},S,E)+\mathcal{G}_{F}(\text{wav2vec},S,E)$
- $S, E$ : 각각 speaker embedding, energy feature - 구조적으로 generator는 Gated Linear Unit (GLU)가 포함된 1D-CNN layer로 구성되고, 생성된 mel-spectrogram은 pre-trained HiFi-GAN vocoder를 통해 waveform으로 변환됨
- Energy, speaker feature는 $\mathcal{G}_{S}, \mathcal{G}_{F}$에 대한 common input으로 사용되는 대신, 각각은 Yingram과 Wav2Vec feature를 사용함

3. Training
- Information Perturbation
- Wav2Vec feature에는 rich linguistic information 뿐만 아니라 pitch, speaker information도 포함되어 있음
- 따라서 논문은 Wav2Vec feature에서 linguistic-related information 만을 selectively extract 하도록 $\mathcal{G}_{F}$를 training 함
- 추가적으로 Yingram feature에서 pitch-related information 만을 selectively extract 하도록 $\mathcal{G}_{S}$를 training 함
- 이를 위해 input waveform $x$에 포함된 information을 3가지 function을 통해 perturb 함
- Formant shifting $\text{fs}$, Pitch randomization $\text{pr}$, Parametric equalizer를 사용한 random frequency shaping $\text{peq}$ - 해당 function chain $f$는 $f(x)=\text{fs}(\text{pr}(\text{peq}(x)))$와 같이 Wav2Vec input에 적용됨
- Yingram에 대해서는 $f0$ information이 preserve 되도록 $\text{fs}, \text{peq}$에 대한 2가지 function chain $g$만 $g(x)=\text{fs}(\text{peq}(x))$와 같이 적용됨
- 이를 위해 input waveform $x$에 포함된 information을 3가지 function을 통해 perturb 함
- 위 과정을 통해 $\mathcal{G}_{F}$는 Wav2Vec feature에서 linguistic-related information을 추출하고, $\mathcal{G}_{S}$는 Yingram feature에서 pitch-related information만 추출할 수 있음
- 결과적으로 Wav2Vec, Yingram feature는 speaker-related information을 포함하지 않으므로 speaker information control은 speaker embedding에만 의존하게 됨
- Training Loss
- 논문은 generated mel-spectrogram $\hat{M}$과 ground-truth mel-spectrogram $M$간의 $L1$ loss를 사용하여 generator와 speaker embedding network를 training 함
- BUT, $L1,L2$ loss는 generated acoustic feature의 over-smoothness로 인해 speech quality가 저하될 수 있음
- 따라서 논문은 $L1$ loss 외에 speaker conditional generative adversarial training을 도입함
- 먼저 discriminator를 $\mathcal{D}(M,\mathbf{c}_{+},\mathbf{c}_{-}):=\sigma(h(M,\mathbf{c}_{+},\mathbf{c}_{-}))$라 하자
- 그러면 다음과 같이 positive pair와 negative pair에 projection conditioning을 적용할 수 있음:
(Eq. 6) $h(M,\mathbf{c}_{+},\mathbf{c}_{-})=\psi(\phi(M))+\mathbf{c}_{+}^{T}\phi(M)-\mathbf{c}_{-}^{T}\phi(M)$
- $M$ : mel-spectrogram, $\sigma(\cdot)$ : sigmoid function
- $\mathbf{c}_{+},\mathbf{c}_{-}$ : 각각 positive pair/randomly sampled utterance의 speaker embedding
- $\phi(\cdot)$ : discriminator의 intermediate layer output, $\psi(\cdot)$ : input vector를 scalar value로 mapping 하는 function
- 결과적으로 discriminator loss $\mathcal{L}_{\mathcal{D}}$와 generator loss $\mathcal{L}_{\mathcal{G}}$는:
(Eq. 7) $\mathcal{L}_{\mathcal{D}}=-\mathbb{E}_{(M,\mathbf{c}_{+},\mathbf{c}_{-})\sim p_{data},\hat{M}\sim p_{gen}}\left[\log (\sigma(h(M,\mathbf{c}_{+},\mathbf{c}_{-})) )-\log (\sigma (h(\hat{M},\mathbf{c}_{+},\mathbf{c}_{-})))\right]$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, \mathcal{L}_{\mathcal{G}}=-\mathbb{E}_{(M,\mathbf{c}_{+},\mathbf{c}_{-})\sim p_{data},\hat{M}\sim p_{gen}}\left[ \log (\sigma(h(\hat{M},\mathbf{c}_{+},\mathbf{c}_{-})))\right] +|M-\hat{M}|$
- BUT, $L1,L2$ loss는 generated acoustic feature의 over-smoothness로 인해 speech quality가 저하될 수 있음
- Test-Time Self-Adaptation
- Synthesis network는 unseen language에 대해 wrong pronunciation을 output 할 수 있음
- 따라서 논문은 Wav2Vec feature를 modify 하는 Test-Time Self-Adaptation (TSA)를 도입함
- 먼저 test-time에서 generated mel-spectrogram $\hat{M}$과 ground-truth mel-spectrogram $M$ 간의 $L1$ loss를 compute 함
- 이후 loss의 backpropagation signal을 사용하여 parameterized Wav2Vec feature를 update 함
- 이때 loss gradient는 filter generator를 통해서만 backpropagate 됨
- 해당 test-time training scheme은 single test-time sample만 사용하고 test-time sample 자체를 target으로 하여 input parameter를 update 함
- 따라서 논문은 Wav2Vec feature를 modify 하는 Test-Time Self-Adaptation (TSA)를 도입함

4. Experiments
- Settings
- Results
- Reconstruction
- NANSY는 english, multilingual dataset 모두에서 ground-truth 수준의 reconstruction이 가능함

- Test-Time Self-Adaptation을 활용하면 더 나은 CER을 달성할 수 있음

- Voice Conversion
- 전체적으로 NANSY의 성능이 가장 뛰어남
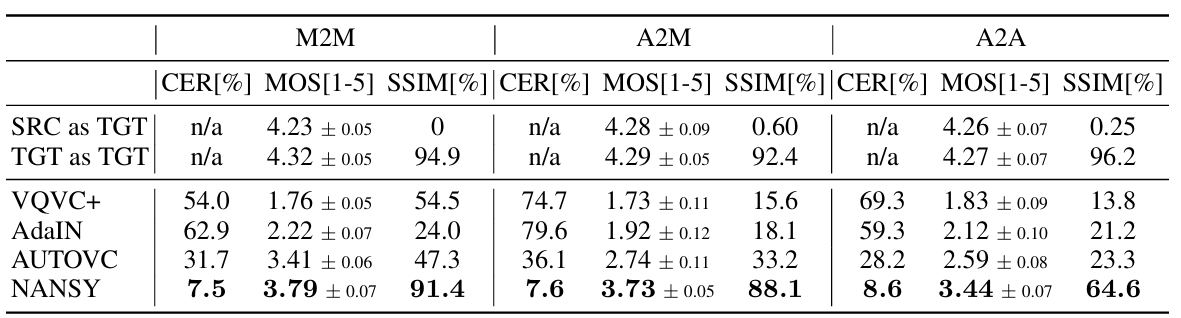
- Multilingual, Unseen dataset에 대해서도 우수한 성능을 보임

- Pitch Shift and Time-Scale Modification
- NANSY는 pitch shift, time-scale modification에 대해 robust 한 성능을 보임

반응형
'Paper > Conversion' 카테고리의 다른 글
댓글