
티스토리 뷰
Paper/Representation
[Paper 리뷰] XLSR: Unsupervised Cross-Lingual Representation Learning for Speech Recognition
feVeRin 2025. 4. 4. 17:23반응형
XLSR: Unsupervised Cross-Lingual Representation Learning for Speech Recognition
- Multiple language에서 single model을 pre-training 하여 cross-lingual speech representation을 얻을 수 있음
- XLSR
- Wav2Vec 2.0을 기반으로 language 간에 share 되는 latent의 quantization을 jointly learning 함
- 추가적으로 labeled data에서 fine-tuning을 수행
- 논문 (INTERSPEECH 2021) : Paper Link
1. Introduction
- Cross-Lingual learning은 other language를 활용하여 model performance를 개선하는 것을 목표로 함
- BUT, 대부분의 speech processing은 labeled data가 필요한 supervised cross-lingual training에 의존함
- 한편으로 unsupervised representation learning/pre-training을 활용하면 labeled data 없이도 우수한 성능을 달성할 수 있음
- 대표적으로 Speech2Vec, Wav2Vec, Wav2Vec 2.0 등은 speech processing을 위해 unsupervised representation learning을 활용함
- 특히 low-resource language에 대해서도 cross-lingual pre-training을 활용할 수 있음
-> 그래서 cross-lingual setting을 위해 unsupervised representation learning을 활용하는 XLSR을 제안
- XLSR
- Wav2Vec 2.0의 pre-training approach를 활용하여 contextualized speech representation과 latent speech representation의 discrete vocabulary를 jointly learning
- Contrastive loss를 통해 model을 training 하고 여러 language에 걸쳐 discrete speech representation을 share 함 - 모든 pre-trained representation을 freeze 하거나 separate downstream model에 feed 하지 않고 model의 Transformer-part만 fine-tuning
- 추가적으로 multiple language에 대한 pre-training을 통해 model을 extend
- Wav2Vec 2.0의 pre-training approach를 활용하여 contextualized speech representation과 latent speech representation의 discrete vocabulary를 jointly learning
< Overall of XLSR >
- Wav2Vec 2.0을 cross-lingual setting으로 extend 하여 cross-lingual speech representation을 학습
- 결과적으로 mono-lingual pre-training 보다 우수한 성능을 달성
2. Method
- 논문은 여러 language에 대해 share 되는 quantized latent speech representation의 single set을 학습하는 것을 목표로 함
- Architecture
- XLSR은 Wav2Vec 2.0의 design choice를 따름
- 먼저 convolutional feature encoder $f:\mathcal{X}\mapsto \mathcal{Z}$를 통해 raw audio $\mathcal{X}$를 latent speech representation $\mathbf{z}_{1},...,\mathbf{z}_{T}$에 mapping 함
- 이후 transformer network $g:\mathcal{Z}\mapsto \mathcal{C}$에 전달하여 context representation $\mathbf{c}_{1},...,\mathbf{c}_{T}$를 output 함
- 각 $\mathbf{z}_{t}$는 20ms로 stride 된 25ms audio를 의미하고, context network는 BERT를 따름
- Model training을 위해 feature encoder representation은 quantization module $\mathcal{Z}\mapsto \mathcal{C}$를 통해 $\mathbf{q}_{1},...,\mathbf{q}_{T}$로 discretize 되어, self-supervised learning objective를 구성함
- 이때 Gumbel Softmax를 사용하면 fully-differentiable way로 discrete codebook entry를 choice 할 수 있음
- 먼저 convolutional feature encoder $f:\mathcal{X}\mapsto \mathcal{Z}$를 통해 raw audio $\mathcal{X}$를 latent speech representation $\mathbf{z}_{1},...,\mathbf{z}_{T}$에 mapping 함
- Training
- XLSR은 masked feature encoder output에 대한 contrastive task를 solve 하여 training 됨
- Masking의 경우, all timestep의 $p=0.065$를 sampling 하여 starting index를 구성한 다음, subsequent $M=10$ timestep을 mask 함
- 이때 objective는 other masked timestep에서 sampling 한 $K=100$ distractors $\mathbf{Q}_{t}$ set 내에서, masked timestep에 대한 true quantized latent $\mathbf{q}_{t}$를 identifying 하는 것을 목표로 함:
(Eq. 1) $-\log \frac{\exp(\text{sim}(\mathbf{c}_{t},\mathbf{q}_{t}))}{\sum_{\tilde{\mathbf{q}}\sim\mathbf{Q}_{t}}\exp(\text{sim}(\mathbf{c}_{t},\tilde{\mathbf{q}}))}$
- $\mathbf{c}_{t}$ : transformer output, $\text{sim}(\mathbf{a},\mathbf{b})$ : cosine-similarity - 이때 해당 objective는 all codebook entry를 사용하도록 codebook diversity penalty로 encourage 됨
- 즉, 각 group $\bar{p}_{g}$에 대한 codebook entry의 averaged softmax distribution의 entropy를 utterance batch에 대해 maximize 함:
(Eq. 2) $\frac{1}{GV}\sum_{g=1}^{G}-H(\bar{p}_{g})=\frac{1}{GV}\sum_{g=1}^{G}\sum_{v=1}^{V}\bar{p}_{g,v}\log \bar{p}_{g,v}$ - 추가적으로 feature encoder를 stabilize 하기 위해 feature encoder output에 $L2$ penalty를 적용함
- 즉, 각 group $\bar{p}_{g}$에 대한 codebook entry의 averaged softmax distribution의 entropy를 utterance batch에 대해 maximize 함:
- $L$ language에 대한 pre-training의 경우, multi-nomial distribution $(p_{l})_{l=1,...,L}$에서 speech sample을 sampling 하여 multi-lingual batch를 구성함
- $p_{l}\sim\left(\frac{n_{l}}{N}\right)^{\alpha}$
- $n_{l}$ : language $l$의 pre-training hours, $N$ : total hours
- $\alpha$ : upsampling factor로써, pre-training 중에 high-/low-resource language에 대한 importance를 control 함
3. Experiments
- Settings
- Dataset : CommonVoice, BABEL, MLS
- Comparisons : m-CPC
- Results
- 전체적으로 XLSR을 사용했을 때 가장 우수한 recognition 성능을 달성함
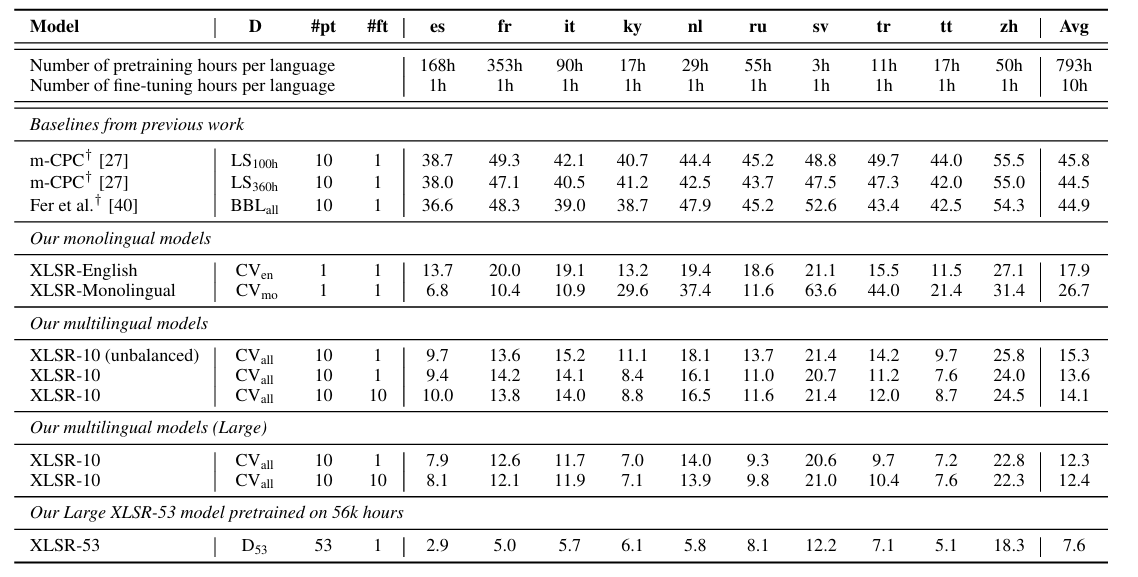
- Mono-lingual model 보다 multi-lingual model을 사용하는 것이 더 효과적임

- Out-of-Domain language에 대해서도 뛰어난 성능을 달성할 수 있음
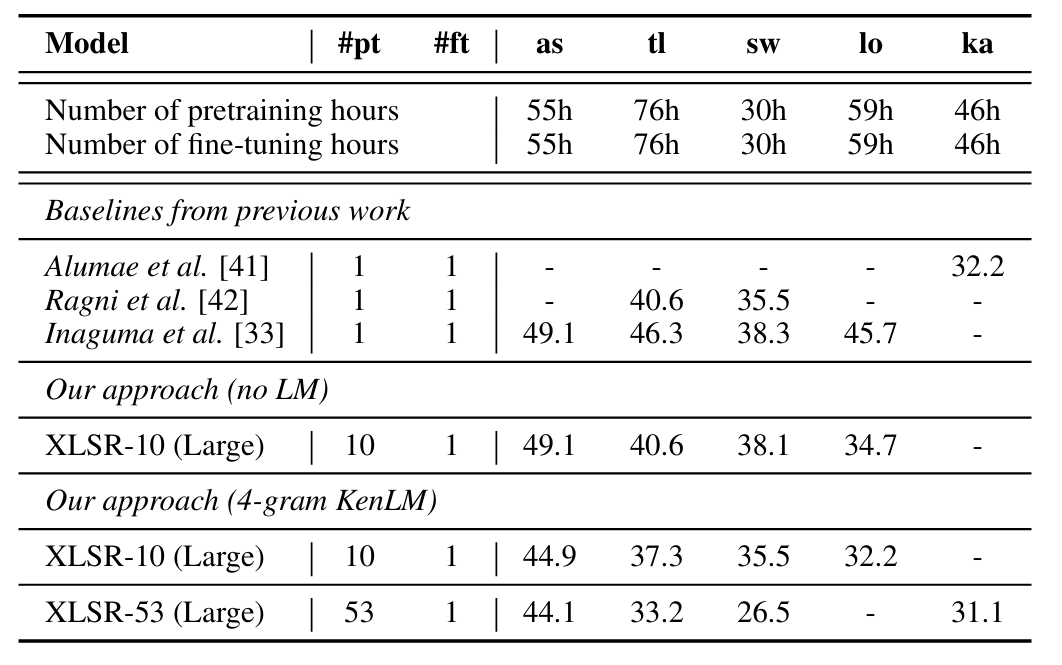
반응형
'Paper > Representation' 카테고리의 다른 글
댓글