

티스토리 뷰
Paper/Conversion
[Paper 리뷰] VoicePrompter: Robust Zero-Shot Voice Conversion with Voice Prompt and Conditional Flow Matching
feVeRin 2025. 4. 7. 17:28반응형
VoicePrompter: Robust Zero-Shot Voice Conversion with Voice Prompt and Conditional Flow Matching
- Zero-Shot Voice Conversion은 speaker similarity 측면에서 여전히 한계가 있음
- VoicePrompter
- Speech component를 disentangle 하는 factorization method를 활용
- Factorized feature와 voice prompt에 대한 conditioning을 수행하는 DiT-based Conditional Flow Matching Decoder를 도입
- Latent Mixup을 통해 various speaker feature를 combining 하여 in-context learning을 향상
- 논문 (ICASSP 2025) : Paper Link
1. Introduction
- 최근 YourTTS, SEF-VC와 같은 Zero-Shot Voice Conversion (VC) system이 우수한 성능을 보이고 있음
- 특히 Diff-HierVC, DDDM-VC 등은 source-filter disentanglement와 disentangled denoising process를 활용하여 zero-shot VC 성능을 개선함
- BUT, 해당 diffusion-based VC model은 iterative sampling으로 인해 inference speed가 상당히 느리고, noisy speech에 vulnerable 하다는 한계가 있음 - 한편으로 target speaker adaptation을 위해 global style conditioning 대신 voice prompting을 활용할 수 있음
- 대표적으로 VALL-E는 audio codec을 input sequence에 concatenate 하고, VoiceBox는 masking/in-filling strategy와 Conditional Flow Matching (CFM) architecture를 활용함
- 특히 prompting mechanism을 사용하면 in-context learning capability를 model에 제공하여 주어진 voice prompt의 style을 효과적으로 반영할 수 있음
- BUT, VC task의 경우 여전히 speech disentanglement의 어려움이 존재함
- 특히 Diff-HierVC, DDDM-VC 등은 source-filter disentanglement와 disentangled denoising process를 활용하여 zero-shot VC 성능을 개선함
-> 그래서 voice prompt와 in-context learning ability를 활용한 VC model인 VoicePrompter를 제안
- VoicePrompter
- CFM을 backbone으로 하는 diffusion transformer architecture를 채택
- Speech perturbation을 위해, latent mixup으로 augment 되고 speech disentangle encoder로 추출된 feature를 기반으로 vector field를 추정함
- 이후 sequence masking과 in-filling을 활용하여 in-context learning ability를 지원함
- Conversion 시에는 prompt를 통해 target voice style을 guiding함으로써 더 나은 speaker similarity를 달성
- CFM을 backbone으로 하는 diffusion transformer architecture를 채택
< Overall of VoicePrompter >
- Voice prompt와 in-context learning을 활용하는 zero-shot VC model
- 결과적으로 기존보다 우수한 conversion 성능을 달성
2. Method
- VoicePrompter는 2가지 component로 구성됨
- Speech Factorizing Encoder : input speech를 disentangle 하고 embedding 하는 역할
- DiT-based CFM Decoder : factorized speech feature와 voice prompt를 conditioning 하는 역할
- Speech Factorizing Encoder
- Content Encoder
- Input audio에서 linguistic information을 추출하기 위해 pre-trained MMS model의 7-th layer를 활용함
- MMS embedding에는 acoustic information이 포함되어 있으므로 input audio에 signal perturbation을 적용하여 speaker characteristic과 independent 한 linguistic information을 isolate 함
- 추출된 MMS embedding은 8-layer WaveNet-based content encoder를 사용하여 speaker information과 함께 modeling 됨
- Pitch Encoder
- Pitch 추출을 위해, 논문은 Praat을 사용하여 $F0$ value를 얻음
- 추출된 $F0$ value는 encoder의 hidden layer configuration을 따라 embed 되고 embedded pitch information은 temporal bottleneck layer를 통해 처리됨
- 이후 content encoder와 동일한 WaveNet-based architecture를 사용하는 pitch encoder를 통해 pitch information을 modeling 함
- Speaker Encoder
- 1D convolution layer를 통해 mel-spectrogram에 대한 spectral feature 추출을 수행하여 speaker information을 얻음
- Temporal feature는 Conv1DGLU layer로 refine 되고 long-term dependency는 multi-head attention을 통해 capture 됨
- Final 1D convolution layer는 style representation을 생성하고, encoder/decoder에서 speaker adaptation을 위해 사용됨

- Conditional Flow Matching Decoder
- 논문은 high-quality mel-spectrogram을 생성하기 위해, Optimal-Transport (OT) path를 활용하는 Conditional Flow Matching (CFM) structure를 채택함
- CFM은 standard Gaussian distribution에서 추출한 noisy sample $x_{0}$에서 시작하여, time-conditioned transformation $\phi_{t}$를 학습해 target sample $x_{1}$에 mapping 함
- 여기서 flow는 Ordinary Differential Equation (ODE)를 통해 control 됨 - Time-conditioned vector field $u_{t}$는 OT path를 choice 할 수 있고, 해당 vector field는 vector field estimator network $v_{\theta}$로 estimate 됨
- 이때 network는 factorized speech feature $z$, voice prompt $p$, speaker embedding $e_{spk}$에 따라 conditioning 되어 vector field를 predict 함
- CFM loss computation은 아래 [Algorithm 1]을 따름
- CFM은 standard Gaussian distribution에서 추출한 noisy sample $x_{0}$에서 시작하여, time-conditioned transformation $\phi_{t}$를 학습해 target sample $x_{1}$에 mapping 함

- Voice Prompt for In-Context Learning
- In-Context learning을 위한 masking strategy를 활용해 direct target voice prompt를 incorporate 할 수 있음
- 이를 위해 input speech의 $70\text{~}100\%$ mask 하고 decoder embedding과 함께 conditioning input으로 사용함
- 즉, VoiceBox의 masking strategy를 채택하여 masked segment에 대한 CFM loss를 compute 함 - 추론 시에는 source content information과 factorized feature $z$를 활용하여 masked portion을 predict 하는 in-filling task를 수행함
- 이를 위해 input speech의 $70\text{~}100\%$ mask 하고 decoder embedding과 함께 conditioning input으로 사용함
- DiT with AdaLN-Sep
- 논문은 CFM decoder의 backbone으로 DiT를 채택하고 conditioning method로써 AdaLN-Zero에서 derive 된 AdaLN-Sep를 도입함
- 먼저 AdaLN-Zero는 conditioning을 transformer에 integrate 하여 DiT의 성능을 향상함:
(Eq. 1) $\text{AdaLN-Zero}(h,c)=\alpha_{c}\odot (\gamma_{c}\cdot \text{LN}(h)+\beta_{c})$ - AdaLN-Zero block은 각 residual block의 end에서 scaling parameter를 zero-initializing 하고 residual connection 전에 dimension-wise scaling parameter를 적용하여 training을 accelerate 함
- BUT, AdaLN-Zero는 conditioning information을 함께 처리하므로, 각 feature의 independent characteristic을 fully-reflect 하지 못함 - 따라서 논문은 speaker, time embedding을 separate 하는 AdaLN-Sep를 도입하여 각 conditioning information을 transformer block에 independently integrate 함:
(Eq. 2) $\text{AdaLN-Sep}(h,s,t)=\left\{\begin{matrix} \alpha_{s}\odot(\gamma_{s}\cdot\text{LN}(h)+\beta_{s}), & \text{for SA Block} \\ \alpha_{t}\odot (\gamma_{t}\cdot\text{LN}_{h}+\beta_{t}), & \text{for FFN Block} \\ \end{matrix}\right.$
- 먼저 AdaLN-Zero는 conditioning을 transformer에 integrate 하여 DiT의 성능을 향상함:

- Latent Mixup
- Voice prompt와 DiT backbone network를 integrate 하여 speaker adaptation을 개선할 수 있지만, train-inference mismatch 문제를 해결해야 함
- 이때 DDDM-VC를 따라 training phase에서 서로 다른 speaker representation을 randomly combining 하여 speech component를 perturb 하는 Latent Mixup을 도입함
- 이때 Latent Mixup은 batch size의 $50\%$에서 수행됨
- 먼저 mixup이 적용되지 않은 process는 다음과 같음:
(Eq. 3) $E_{\text{cont}}(z_{\text{cont},x},z_{\text{spk},x})+E_{F0}(z_{F0,x},z_{\text{spk},x})=\hat{z}$
- $E_{\text{cont}}$ : content encoder, $E_{F0}$ : $F0$ encoder
- $z_{\text{spk},x}$ : speaker $x$의 style information - Mixup이 적용되는 경우의 formulation은:
(Eq. 4) $E_{\text{cont}}(z_{\text{cont},x},z_{\text{spk},y})+E_{F0}(z_{F0,x},z_{\text{spk},y})=\hat{z}_{\text{mix}}$
- $z_{\text{cont},x}, z_{F0,x}$ : speaker $x$의 content/$F0$ information
- $z_{\text{spk},y}$ : speaker $y$의 style information
- 논문은 CFM decoder의 condition으로 $\hat{z}_{\text{mix}}$를 사용하고 encoder의 reconstruction에는 $\hat{z}$를 사용함
- 이를 통해 relevant factor를 robustly disentangle 할 수 있으므로 zero-shot VC의 generalization을 향상할 수 있음
- 이때 DDDM-VC를 따라 training phase에서 서로 다른 speaker representation을 randomly combining 하여 speech component를 perturb 하는 Latent Mixup을 도입함
3. Experiments
- Settings
- Dataset : LibriTTS, VCTK
- Comparisons : DiffVC, Diff-HierVC, DDDM-VC, NaturalSpeech3
- Results
- 전체적으로 VoicePrompter의 성능이 가장 우수함

- Ablation Study
- VoicePrompter의 각 component를 제거하는 경우 성능 저하가 발생함
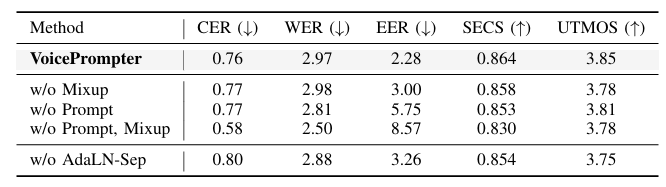
- Sampling Steps
- VoicePrompter는 single-step generation 만으로도 우수한 성능을 달성할 수 있음

- Scaling Down Model Size
- 38M의 parameter 수를 가지는 smaller variant을 구성할 수 있음

- VoicePrompter-S는 큰 성능 저하 없이 zero-shot VC를 수행할 수 있음

반응형
'Paper > Conversion' 카테고리의 다른 글
댓글