
티스토리 뷰
Paper/Conversion
[Paper 리뷰] One-Shot Voice Conversion by Separating Speaker and Content Representations with Instance Normalization
feVeRin 2024. 8. 8. 09:49반응형
One-Shot Voice Conversion by Separating Speaker and Content Representations with Instance Normalization
- Source, target speaker의 example utterance만으로 voice conversion을 수행할 수 있어야 함
- AdaIN-VC
- Instance Normalization을 도입해 speaker, content representation을 disentanlging 함
- Unseen speaker에 대해 one-shot voice conversion이 가능
- 논문 (INTERSPEECH 2019) : Paper Link
1. Introduction
- Voice Conversion (VC)는 linguistic content를 유지하면서 speech signal의 non-linguistic information을 변환하는 것을 목표로 함
- 이때 non-linguistic information은 speaker identity나 accent, pronunciation 등을 의미
- 한편 기존 VC 방식은 크게 supervised, unsupervised method로 나눌 수 있음
- Supervised VC는 뛰어난 conversion 성능을 보이지만, source와 target utterance 간의 frame-level alignment가 필요함
- 즉, source/target domain 간에 큰 gap이 존재하는 경우 inaccurate alignment로 인해 품질이 저하될 수 있음
- 추가적으로 training에 많은 양의 data가 필요하므로 time-consuming 함 - Unsupervised VC는 data collection efficiency 측면에서 장점을 가짐
- 대표적으로 ASR system을 결합하거나 VAE, GAN과 같은 generative model을 활용함
- BUT, 해당 방식들은 unseen speaker를 합성하는데 있어 품질의 한계가 있음
- Supervised VC는 뛰어난 conversion 성능을 보이지만, source와 target utterance 간의 frame-level alignment가 필요함
-> 그래서 unseen speaker에 대해서도 효과적으로 동작하는 one-shot VC 모델인 AdaIN-VC를 제안
- AdaIN-VC
- Speech signal에서 speaker, acoustic condition은 time-independent 한 반면 linguistic part는 frame별로 쉽게 변화
- 즉, utterance는 speaker representation과 content representation으로 factorize 될 수 있음 - 여기서 speaker와 content representation을 disentangle 하기 위해, speaker encoder, content encoder, decoder의 3가지 component를 도입
- Speaker encoder는 speaker information을 speaker representation으로 encoding 하고 content encoder는 linguistic information을 content representation으로 encoding 함
- 이후 decoder는 두 representation을 결합하여 speech를 합성
- Content encoder에서 global information을 control 하는 channel statistics를 normalize 하기 위해 instance normalization을 적용
- 추가적으로 decoder에서는 Adaptive Instance Normalization (AdaIN)을 채택해 factorized representation을 학습
- 해당 instance noramlization은 adversarial training과 비교하여 utterance information을 제거하는데 효과적임
- Speech signal에서 speaker, acoustic condition은 time-independent 한 반면 linguistic part는 frame별로 쉽게 변화
< Overall of AdaIN-VC >
- Unseen speaker에 대해 supervision 없이 one-shot VC를 수행 가능
- 결과적으로 instance normalization을 통해 representation을 효과적으로 disentangling 하고 meaningful speaker embedding을 학습할 수 있음
2. Method
- AdaIN-VC는 factorization을 통해 다음과 같이 one-shot VC를 수행함
- 먼저 target utterance에서 speaker representation을 추출한 다음,
- Source utterance에서 content representation을 추출하고, Decoder와 결합해 conversion을 수행
- 이때 전체 모델은 training process 중에 utterance에 대한 speaker label을 요구하지 않으므로 data collection 측면에서 장점이 있음
- Variational AutoEncoder
- $x$를 acoustic feature segment라고 하고 $\mathcal{X}$를 training data의 모든 acoustic segment collection이라고 하자
- $E_{s}, E_{c}, D$를 각각 speaker encoder, content encoder, decoder라고 할 때, $E_{s}$는 speaker representation $z_{s}$를 생성하고, $E_{c}$는 content representation $z_{c}$를 생성하도록 학습됨
- $p(z_{c}|x)$가 $p(z_{c}|x)=\mathcal{N}(E_{c}(x),I)$와 같이 unit variance를 가지는 conditionally independent Gaussian distribution이라고 했을 때, reconstruction loss는:
(Eq. 1) $\mathcal{L}_{rec}(\theta_{E_{s}},\theta_{E_{c}},\theta_{D})=\mathbb{E}_{x\sim p(x), z_{c}\sim p(z_{c}|x)}\left[|| D(E_{s}(x),z_{c})-x||_{1}^{1}\right]$
- Training process 동안 $\mathcal{X}$에서 acoustic segment $x$를 uniformly sampling하므로, (Eq. 1)의 $p(x)$는 $\mathcal{X}$에 대한 uniform distribution과 같음 - Posterior distribution $p(z_{c}|x)$를 prior distribution $\mathcal{N}(0,I)$에 match 하기 위해 KL divergence loss를 최소화함
- 논문은 unit variance를 가정하므로 KL divergence는 $L2$ regularization으로 reduce 될 수 있음
- 이때 KL divergence term은:
(Eq. 2) $\mathcal{L}_{kl}(\theta_{E_{c}})=\mathbb{E}_{x\sim p(x)}\left[|| E_{c}(x)^{2}||_{2}^{2}\right]$
- 결과적으로 VAE training을 위한 objective는 weighted hyperparameter $\lambda_{rec},\lambda_{kl}$을 사용해 다음과 같이 얻어짐:
(Eq. 3) $\min_{\theta_{E_{s}},\theta_{E_{c}},\theta_{D}}\mathcal{L}(\theta_{E_{s}},\theta_{E_{c}},\theta_{D})= \lambda_{rec}\mathcal{L}_{rec}+\lambda_{kl}\mathcal{L}_{kl}$

- Instance Normalization for Feature Disentanglement
- Affine transformation 없이 $E_{c}$에 instance normalization을 추가하면 content information을 preserving 하면서 speaker information을 제거할 수 있음
- Instance normalization을 적용하기에 앞서 $c$-th channel의 mean $\mu_{c}$와 standard deviation $\sigma_{c}$를 계산해야 함:
(Eq. 4) $\mu_{c}=\frac{1}{W}\sum_{w=1}^{W}M_{c}[w],\,\,\, \sigma_{c}=\sqrt{\frac{1}{W}\sum_{w=1}^{W}(M_{c}[w]-\mu_{c})^{2}+\epsilon}$
- $M$ : previous convolutional layer의 feature map, $M_{c}$ : $W$-dimensional array의 $c$-th channel
- $\epsilon$ : numerical instability를 방지하기 위한 small value
- 여기서 각 channel은 1D convolution이 적용되므로 matrix가 아닌 array로 취급됨 - 그러면 affine transformation이 제거된 instance normalization (IN)은 array $M_{c}$의 각 element를 다음과 같이 $M'_{c}$로 normalize 함:
(Eq. 5) $M'_{c}[w]=\frac{M_{c}[w]-\mu_{c}}{\sigma_{c}}$
- $M_{c}[w]$ : $M_{c}$의 $w$-th element - Content encoder에 해당 IN layer를 적용하면 content encoder가 domain information을 학습하는 것을 방지함
- 이를 통해 speaker encoder에서 speaker information을 추출하고 content encoder에서는 content information만 각각 추출되도록 enforcing 할 수 있음
- 추가적으로 speaker encoder가 speaker representation을 효과적으로 얻을 수 있도록 Adaptive Instance Normalization (AdaIN)을 채택하여 decoder에 speaker information을 제공함
- 결과적으로 AdaIN layer에서 decoder는 IN을 통해 speaker encoder에서 전달된 global information을 다음과 같이 normalize 함:
(Eq. 6) $M'_{c}[w]=\gamma_{c}\frac{M_{c}[w]-\mu_{c}}{\sigma_{c}}+\beta_{c}$
- $\mu_{c},\sigma_{c}$ : (Eq. 4)에서 계산되는 값
- $\gamma_{c}, \beta_{c}$ : Speaker encoder $E_{s}$ output의 linear transformation
- Instance normalization을 적용하기에 앞서 $c$-th channel의 mean $\mu_{c}$와 standard deviation $\sigma_{c}$를 계산해야 함:
- Architecture
- Encoder, decoder는 Conv1D layer를 사용하여 frequency information을 처리함
- ConvBank layer는 speaker encoder, content encoder에서 long-term information을 capture 하기 위해 사용됨
- 이때 speaker encoder에 time에 따른 average pooling을 적용하여 speaker encoder가 global information만을 학습하도록 함
- Instance normalization layer는 content encoder에서 global information을 normalize 하는 데 사용됨 - PixelShuffle1D layer는 decoder에서 upsampling을 수행하는데 사용되고, AdaIN layer는 global information을 decoder에 제공함
- Speaker representation $z_{s}$는 residual DNN을 통해 처리된 다음, AdaIN layer 이전에 affine layer를 통해 변환됨

3. Experiments
- Settings
- Dataset : VCTK
- Results
- Evaluation of Disentanglement
- Content encoder에서 IN layer의 효과를 확인하기 위해 ablation study를 수행
- IN을 content encoder에 적용하면 classification accuracy가 낮아짐
- 특히 speaker encoder는 AdaIN으로 decoder의 channel statistics를 control 하므로 전체 모델은 speaker encoder에서 speaker information을 학습하게 됨

- Speaker Embedding Visualization
- t-SNE를 통해 embedding을 시각화하면, 다른 speaker에 대한 utterance가 well-separate 되어 나타나는 것을 확인할 수 있음

- Objective Evaluation
- Global variance, spectrogram 모두에서 AdaIN-VC는 phonetic content를 유지하면서 효과적인 conversion을 수행하는 것으로 나타남


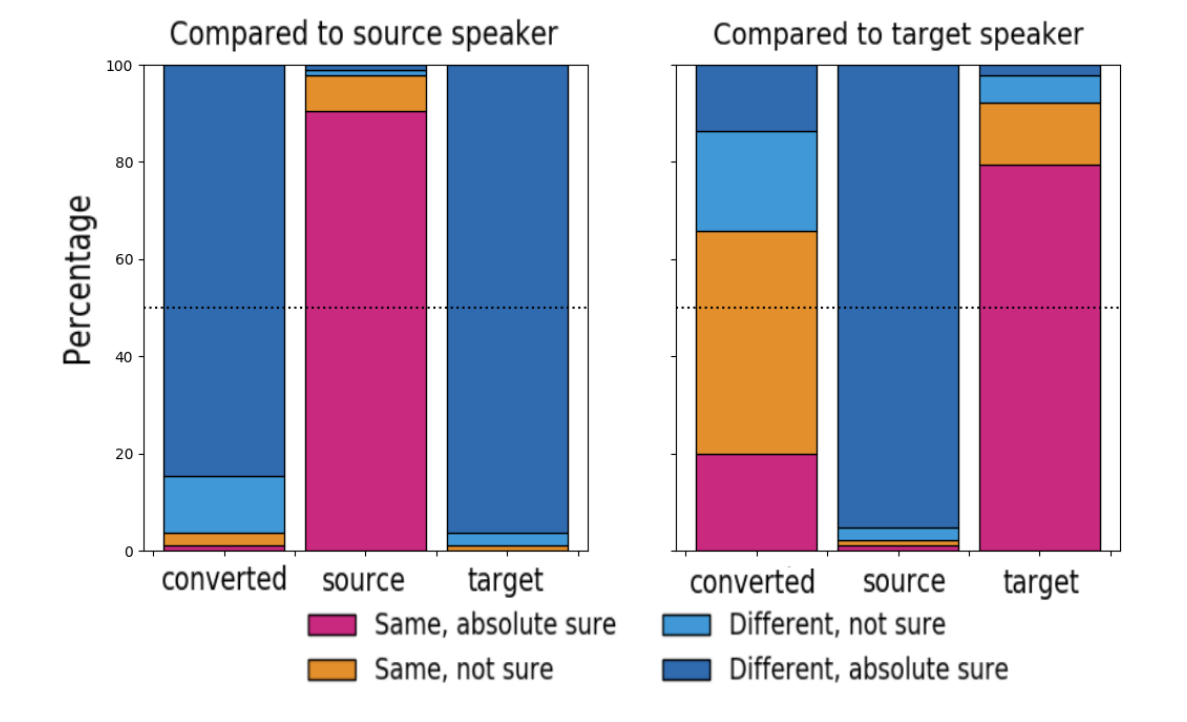
- Subjective Evaluation
- Similarity test 측면에서 AdaIN-VC의 결과는 높은 유사도를 보임
반응형
'Paper > Conversion' 카테고리의 다른 글
댓글