
티스토리 뷰
Paper/Representation
[Paper 리뷰] XLS-R: Self-Supervised Cross-Lingual Speech Representation Learning at Scale
feVeRin 2025. 4. 21. 19:05반응형
XLS-R: Self-Supervised Cross-Lingual Speech Representation Learning at Scale
- 영어 외의 다양한 language에 대한 speech processing task도 지원할 수 있어야 함
- XLS-R
- Wav2Vec 2.0을 기반으로 한 cross-lingual speech representation learning method
- 128 language에 대한 large-scale speech audio를 활용
- 논문 (INTERSPEECH 2022) : Paper Link
1. Introduction
- Self-supervised learning은 다양한 domain, language에 대한 general representation을 제공함
- 특히 high-resource language를 활용하여 low-resource language에 대한 성능을 개선할 수 있음
- 대표적으로 Wav2Vec 2.0, XLSR 등은 cross-lingual transfer를 활용해 low-resource data에 대한 better representation을 얻음 - 이때 large-scale speech dataset을 활용하면 해당 cross-lingual 성능을 더욱 향상할 수 있음
- 특히 high-resource language를 활용하여 low-resource language에 대한 성능을 개선할 수 있음
-> 그래서 large-scale cross-lingually pre-trained self-supervised learning model인 XLS-R을 제안
- XLS-R
- Wav2Vec 2.0을 기반으로 large-scale cross-lingual pre-training을 수행
- VoxPopuli, CommonVoice, BABEL 등 128 language에 대한 436K hours의 dataset을 활용
< Overall of XLS-R >
- Wav2Vec 2.0을 기반으로 한 large-scale cross-lingual self-supervised learning model
- 결과적으로 다양한 downstream task에 대해 기존보다 우수한 성능을 달성
2. Method
- 논문은 multiple language에 대한 Wav2Vec 2.0 model pre-training을 기반으로 함
- 먼저 Wav2Vec 2.0은 raw audio $\mathcal{X}$를 latent speech representation $z_{1},...,z_{T}$로 mapping 하는 convolutional feature encoder $f:\mathcal{X}\mapsto\mathcal{Z}$를 가짐
- 이후 해당 representation은 Transformer $g:\mathcal{Z}\mapsto \mathcal{C}$에 전달되어 context representation $c_{1},...,c_{T}$를 output 함 - 한편으로 training을 위해서는 masked feature encoder output에 대한 contrastive task를 solve 해야 함
- 특히 training 시에는 random starting index가 있는 10 time-step span이 mask 됨 - 결과적으로 objective는 other masked time-step에서 sampling 된 $K=100$ distractors set $Q_{t}$ 내에서 masked time-step에 대한 true quantized latent $q_{t}$를 identifying 함
- Training batch에는 $l=1,...,L$인 $p_{l}\sim \left(\frac{n_{1}}{N}\right)^{\alpha}$ distribution에서 sampling 된 multiple language $L$의 sample이 포함됨
- $n_{l}$ : 각 language에 대한 unlabeled data의 양, $\alpha$ : pre-training 시 high-/low-resource language 간의 trade-off를 control 하는 upsampling factor
- 먼저 Wav2Vec 2.0은 raw audio $\mathcal{X}$를 latent speech representation $z_{1},...,z_{T}$로 mapping 하는 convolutional feature encoder $f:\mathcal{X}\mapsto\mathcal{Z}$를 가짐
3. Experiments
- Settings
- Dataset : VoxPopuli, Multilingual LibriSpeech, CommonVoice, VoxLingua107, BABEL
- Comparisons : XLSR, VP, XMEF
- Results
- Speech Translation
- $\text{X}\rightarrow\text{EN}$ 측면에서 XLS-R의 성능이 가장 우수함

- $\text{EN}\rightarrow\text{X}$ 측면에서도 XLS-R이 가장 뛰어남
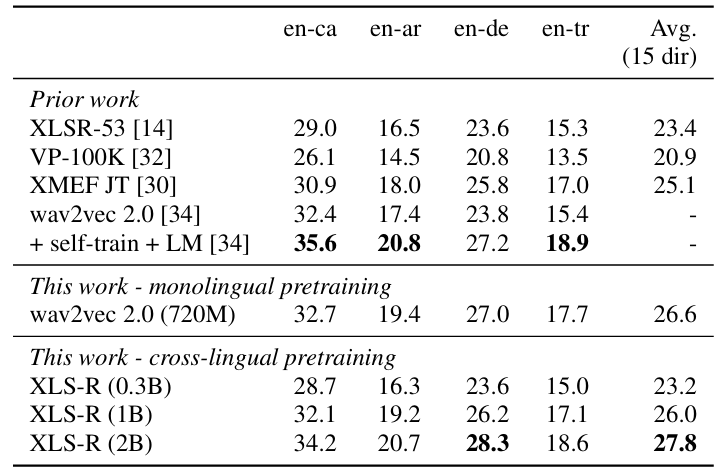
- Speech Recognition
- BABEL dataset에 대해 XLS-R의 recognition 성능이 가장 우수함

- CommonVoice Dataset에 대해서도 마찬가지의 결과를 보임

- Language Identification
- Language Identification task에 대해서도 가장 낮은 Error Rate를 달성함

반응형
'Paper > Representation' 카테고리의 다른 글
댓글