

티스토리 뷰
Paper/Conversion
[Paper 리뷰] StreamVoice: Streamable Context-Aware Language Modeling for Real-time Zero-Shot Voice Conversion
feVeRin 2024. 10. 13. 12:19반응형
StreamVoice: Streamable Context-Aware Language Modeling for Real-time Zero-Shot Voice Conversion
- Language Model을 활용하여 zero-shot voice conversion 성능을 향상할 수 있음
- BUT, 기존 방식은 offline conversion으로 인해 complete source speech 만을 요구하므로 real-time application에서 활용하기 어려움 - StreamVoice
- Streaming capability를 위해 temporal independent acoustic predictor를 포함한 fully causal context-aware Language Model을 도입
- 이를 통해 complete source speech에 대한 dependency를 제거하면서 autoregression의 각 time step에서 semantic/acoustic feature를 alternately processing 함 - 추가적으로 streaming 과정에서 incomplete context로 인한 성능 저하를 방지하기 위해 teacher-guided context foresight와 semantic masking strategy를 채택
- Streaming capability를 위해 temporal independent acoustic predictor를 포함한 fully causal context-aware Language Model을 도입
- 논문 (ACL 2024) : Paper Link
1. Introduction
- Voice Conversion (VC)는 linguistic content를 변경하지 않으면서 speaker voice를 다른 target voice로 transfer 하는 것을 목표로 함
- 특히 AutoVC와 같은 zero-shot VC는 speaker utterance가 단 하나뿐인 arbitrary target speaker로 변환함
- BUT, 기존의 zero-shot VC model은 offline system 전용으로 설계되어 real-time application에 적합하지 않고, streaming capability가 떨어짐 - Zero-Shot VC를 위해서는 speech를 semantic content, speaker timbre 등으로 disentangling 해야 함
- 최근에는 Language Model (LM) framework와 training data scaling up을 통해 bulit-in in-context learning ability를 갖춘 LM-based VC model이 뛰어난 zero-shot VC 성능을 보이고 있음
- BUT, 해당 LM-based VC model은 complete source speech를 요구하기 때문에 real-time application에서 사용할 수 없다는 단점이 있음 - ALO-VC와 같은 non-LM-based method는 unseen speaker에 대해 잘 generalize 되지 못한다는 한계가 있음
- Model capacity가 제한적이고, streaming scenario에서 future information이 missing 되어 성능이 저하되기 때문
- 최근에는 Language Model (LM) framework와 training data scaling up을 통해 bulit-in in-context learning ability를 갖춘 LM-based VC model이 뛰어난 zero-shot VC 성능을 보이고 있음
- 특히 AutoVC와 같은 zero-shot VC는 speaker utterance가 단 하나뿐인 arbitrary target speaker로 변환함
- 한편으로 streaming VC를 위해 LM의 feasibility를 확인해 보면,
- Recognize-Synthesis framework를 따라:
- Speech를 각각 streaming ASR, audio codec에서 추출된 semantic BNF와 acoustic feature로 표현할 수 있음
- LM-based VC model은 target speaker timbre를 사용하여 semantic information을 acoustic feature로 변환함
- 즉, streaming zero-shot VC을 위해 LM-based model은 다음의 문제점을 해결해야 함:
- Streamable Architecture
- Streaming model은 future time step에 의존하지 않고 current input을 receive 했을 때 ouptut을 즉시 생성함
- BUT, 기존의 LM-based VC model은 source speech의 full-utternace를 전달받은 경우에만 conversion을 수행하므로 streaming에 적합하지 않음 - Performance Gap
- Streaming model은 future information 없이 frame-wise/chunked input을 causal 하게 처리해야 하므로 context missing과 performance degradation이 발생할 수 있음
- 특히 VC model은 ASR의 semantic feature에 의존하므로 semantic feature의 중요성이 상당히 큼
- BUT, streaming ASR은 non-streaming model에 비해 성능이 떨어지므로 low-quality semantic information을 전달할 수 있음
- Streamable Architecture
- Recognize-Synthesis framework를 따라:
-> 그래서 위 문제를 해결한 streamable LM-based Zero-Shot VC model인 StreamVoice를 제안
- StreamVoice
- Streamable architecture를 위해 Acoustic Predictor를 기반으로 acoustic codec을 causally generate 하는 single-stage Language Model을 채택
- 각 time step에서 semantic/acoustic feature를 alternating input 하여 seamless streaming을 보장함 - 추가적으로 missing contextual information으로 인한 performance gap을 완화하기 위해 다음의 strategy를 도입:
- Teacher-Guided Context Foresight
- VC model은 teacher가 summarize 한 present/future semantic information을 추론하기 위해 non-streaming ASR을 통해 teaching 됨
- 결과적으로 해당 information은 acoustic prediction을 향상하는 데 사용됨 - Semantic Masking
- Preceding acoustic, corrupted semantic input으로부터 acoustic prediction을 encourage 함
- Implicit 하게 information bottelneck을 생성하여 source speaker information을 줄이고 input history로부터 context learning을 향상함
- Teacher-Guided Context Foresight
- Streamable architecture를 위해 Acoustic Predictor를 기반으로 acoustic codec을 causally generate 하는 single-stage Language Model을 채택
< Overall of StreamVoice >
- Streaming VC를 위한 LM-based zero-shot VC model
- 결과적으로 기존보다 뛰어난 stream VC 성능을 달성

2. Method
- Overview
- StreamVoice는 recognition-synthesis framework를 따름
- 해당 framework에서 speech는 pre-trained streaming ASR model과 speech codec model에 의해 semantic feature $\mathbf{s}=\{s_{1},s_{2},...,s_{T_{s}}\}$와 acoustic feature $\mathbf{a}=\{a_{1},a_{2},...,a_{T_{a}}\}$로 represent 됨
- $T_{s},T_{a}$ : sequence length - 이후 $\mathbf{s},\mathbf{a}$는 same length $T$에 대해 align 되고, StreamVoice는 Context-Aware Lanugage Model과 Acoustic Predictor를 결합하여 single lanugage modeling을 수행함
- 즉, target speaker의 semantic/acoustic feature $\{\tilde{\mathbf{s}},\tilde{\mathbf{a}}\}$를 speaker prompt로 사용하여:
- LM은 source speech의 semantic information $\mathbf{s}_{1:t}$으로 hidden output $^{c}\mathbf{h}$를 autoregressively predict 함
- LM의 각 autoregression time-step에서 Acoustic Predictor는 hidden output $^{c}\mathbf{h}$를 converted speech의 codec feature $\hat{\mathbf{a}}$로 변환함 - 최종적으로 codec model은 예측된 codec feature로부터 waveform을 reconstruct 함
- 즉, target speaker의 semantic/acoustic feature $\{\tilde{\mathbf{s}},\tilde{\mathbf{a}}\}$를 speaker prompt로 사용하여:
- 해당 framework에서 speech는 pre-trained streaming ASR model과 speech codec model에 의해 semantic feature $\mathbf{s}=\{s_{1},s_{2},...,s_{T_{s}}\}$와 acoustic feature $\mathbf{a}=\{a_{1},a_{2},...,a_{T_{a}}\}$로 represent 됨

- Streamable Architecture
- Streaming VC를 위해서는 streamable architecture가 필요함
- 따라서 StreamVoice에서 Language Model은 VC task에 대해 full causal processing을 수행하도록 설계되고,
- Acoustic Predictor는 temporal information에 의존하지 않고 frame-wise prediction을 수행하도록 설계됨
- Fully Causal Language Model
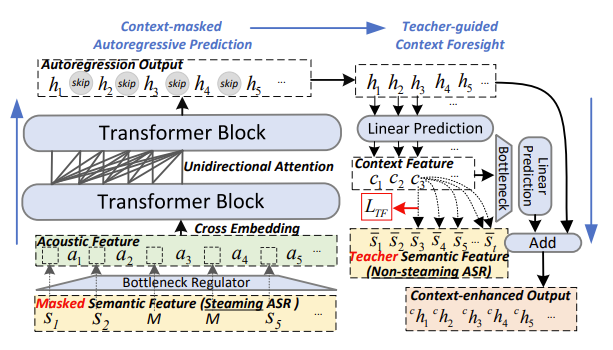
- StreamVoice는 아래 그림과 같이 Language Model을 활용하여 streaming zero-shot VC를 수행함
- 특히 기존 방식은 VC를 위해 source speech의 complete semantic feature $\mathbf{s}$가 요구되고, 각 time step에 대해 $p(a_{t}|\mathbf{s}_{1:T_{s}},\mathbf{a}_{1:t-1})$과 같이 formulate 되므로 real-time application에 사용할 수 없음
- 따라서 streaming을 위해서는 LM의 어떠한 component도 future information에 의존하지 않아야 함 - 이를 위해 논문은 unidirectional attention을 가지는 decoder-only LM을 통해 causal generation을 충족함
- 이때 complete semantic input의 dependency를 제거하기 위해 semantic/acoustic feature $\{\mathbf{s},\mathbf{a}\}$는 same sequence length $T$에 대해 align 된 다음,
- LM에 alternatively input 되어 $\{s_{1},a_{1},s_{2},a_{2},...,s_{T},a_{T}\}$와 같은 cross-embedding을 생성함
- 결과적으로 해당 modification을 통해 LM은 streaming processing과 $p(a_{t}|\mathbf{s}_{1:t},\mathbf{a}_{1:t-1})$ modeling이 가능해짐
- 구체적으로,
- ASR model을 통해 얻어진 semantic feature $\mathbf{s}$는 $\{s_{1},s_{2},...,s_{T}\}$와 같은 embedding sequence로 구성됨
- 한편으로 $L$-layer codec에서 얻어진 codec token은 $\mathbf{a}\in\mathcal{R}^{T\times L}$과 같은 discrete unit으로 represent 됨 - 여기서 acoustic embedding sequence를 얻기 위해 각 layer의 codec token은 embedding space에 개별적으로 embedding 된 다음, embedding dimension을 따라 concatenate 되어 fused acoustic embedding을 생성함
- 이후 fused acoustic embedding과 semantic feature는 linear layer를 사용하여 same dimension으로 변환됨
- 최종적으로 language model에 alternately input 되어 cross-embedding을 생성함
- ASR model을 통해 얻어진 semantic feature $\mathbf{s}$는 $\{s_{1},s_{2},...,s_{T}\}$와 같은 embedding sequence로 구성됨
- Acoustic Predictor
- 앞선 LM을 통해 content, speaker를 output $^{c}\mathbf{h}$에 encoding 할 수 있으므로 acoustic predictor는 temporal-irrelevant 하게 설계되어 $^{c}\mathbf{h}$를 acoustic codec space로 변환함
- 여기서 speech는 neural codec에 의해 continuous/discrete form으로 represent 될 수 있으므로, 논문은 continuous projection과 discrete projection 모두를 고려
- Continuous Projection
- 우선 codec model에 의해 encode 된 $D$-dimensional quantized latent vector $\mathbf{a}\in\mathcal{R}^{T\times D}$를 continuous acoustic representation으로 사용함
- Continuous representation prediction에는 아래 그림과 같이 linear layer stack을 사용함
- 결과적으로 continuous projection loss는 predicted acoustic feature $\hat{\mathbf{a}}$와 ground-truth acoustic feature $\mathbf{a}$ 간의 $L2$ distance로 계산됨:
(Eq. 1) $\mathcal{L}_{Cont}=|| \mathbf{a}-\hat{\mathbf{a}}||_{2}^{2}$
- Discret Projection
- 일반적으로 codec은 low bitrate에서 original speech를 $L$-layer discrete index $\mathbf{a}\in\mathcal{R}^{T\times L}$로 compress 하기 위해 multi-layer quantizer로 설계됨
- 기존의 LM-based model은 multiple LM을 stack 하여 discrete feature를 예측하므로 pipeline이 복잡해지고 streaming이 어려움
- 따라서 StreamVoice는 MQTTS의 stream-lined multi-layer codec prediction을 도입해 language model을 streaming process에 통합함 - 구체적으로, 논문은 single-layer transformer를 사용하여 codec의 hierarchical conditional distribution을 모델링함
- 이때 time $t$에서 transformer는 $^{c}\mathbf{h}$를 input condition으로 사용하고 layer $1$에서 $L$까지 sequential 하게 $a_{t}^{l}$를 생성함
- 해당 process는 preceding/future $^{c}\mathbf{h}$와 independent 하므로 streaming scenario에 적합함 - 결과적으로 discrete projection loss는:
(Eq. 2) $\mathcal{L}_{Disc}=-\log \prod_{t=1}^{T}\prod_{l=1}^{L}p( a_{t}^{l}|\mathbf{a}_{1:t-1}, ^{m}\mathbf{s}_{1:t},t,a_{t}^{1:l-1})$
- 앞선 LM을 통해 content, speaker를 output $^{c}\mathbf{h}$에 encoding 할 수 있으므로 acoustic predictor는 temporal-irrelevant 하게 설계되어 $^{c}\mathbf{h}$를 acoustic codec space로 변환함

- Context-Aware Enhancement
- Streaming framework은 causality disadvantage로 인해 future reception을 missing 할 수 있고 streaming ASR의 low-quality semantic input으로 인해 고품질 변환이 어려움
- 따라서 논문은 semantic input에서 발생하는 incomplete contextual information과 future information absence를 해결하기 위해 Context-Aware Enhancement를 도입함
- 구체적으로,
- StreamVoice는 LM에 Context-Masked Autoregressive Prediction을 도입하여 주어진 semantic input에서 historical context를 capture 하는 능력을 향상함
- 추가적으로 Teacher-Guided Context Foresight를 통해 model이 historical context를 기반으로 future context를 고려할 수 있도록 함
- Context-Masked Autoregressive Prediction
- StreamVoice의 LM은 Llama에 기반한 unidirectional attention을 가지는 multi-layer Transformer로 구현됨
- 이때 주어진 semantic input에서 contextual awareness를 향상하기 위해 LM에 semantic masking을 도입하여 corrupted semantic에서 acoustic prediction을 ecourage 함
- 먼저 semantic token $\mathbf{s}=\{s_{1},s_{2},...,s_{T}\}$의 sequence에서 $r$의 ratio로 여러 index를 start index로 randomly select 하고, $l$ step의 span을 $[M]$으로 mask 함
- Masking 이후, LM은 corrupted semantic feature $^{m}\mathbf{s}$를 input으로 하여 autoregression을 수행함
- 해당 방식을 적용하면 speaker information을 줄이기 위해 semantic feature에 bottleneck information이 implicitly create 되고, training 중에 speaker prompt에 대한 explicit speech clip이 필요하지 않음
- 대신 LM은 previous sequence $\{\mathbf{s}_{1:t-1},\mathbf{a}_{1:t-1},s_{t}\}$를 prompt로 활용하여 further acoustic prediction을 위한 hidden representation $h_{t}$ autoregressive 하게 생성함 - 특히 current input이 $\mathbf{a}_{t}$일 때, 해당 output은 skip 되고 further step을 involve 하지 않음
- Teacher-Guided Context Foresight
- Future information absence는 context information loss를 발생시키므로 conversion 성능을 저해함
- 따라서 논문은 non-streaming ASR에 의해 guide 되는 teacher-guided context foresight를 도입하여 autoregressive output을 개선함
- 이를 통해 StreamVoice는 envisioned future information을 포함하는 context vector를 학습할 수 있음 - 구체적으로,
- Context representation $\mathbf{c}$는 LM이 historical context를 통해 생성한 hidden feature $\mathbf{h}$에서 linear prediction으로 얻어짐
- 다음으로 $c_{t}$는 future time step $\bar{s}_{t+1},...,\bar{s}_{t+k}$의 $k$ semantic feature와 current semantic $s_{t}$를 사용하여 $L2$ distance를 최소화함으로써 general future context를 discover 함
- 해당 dual minimization을 통해 precise content delivery와 future context forecast를 향상할 수 있음 - 이때 loss는 다음과 같이 구성됨:
(Eq. 3) $\mathcal{L}_{TF}=\frac{1}{T-k}\sum_{1}^{T-k}|| c_{t}-\text{Concat}(\bar{s}_{t},\bar{s}_{t+1},...,\bar{s}_{t+k})||_{2}^{2}$
- $\text{Concat}(\cdot)$ : dimensional axis에 대한 feature concatenation
- 기존 Autoregressive Predictive Coding (APC)와 달리 StreamVoice는 non-streaming ASR model을 teacher로 사용하여 foresight process를 guide 하는 semantic information $\mathbf{s}$를 제공함
- Dimension transformation 이후 context representation $\mathbf{c}$는 $\mathbf{h}$와 결합되어 context-enhanced $^{c}\mathbf{h}$를 형성한 다음, acoustic predictor로 전달됨 - 추가적으로 semantic feature $\{\mathbf{s},\bar{\mathbf{s}}\}$는 speaker-related information을 포함할 수 있으므로, speech decoupling을 강화하기 위해 AutoVC의 bottleneck regulator를 $\mathbf{s},\mathbf{c}$에 적용함
- 즉, linear layer로 dimension size를 reduce 하여 speaker information을 squeeze out 함
- Training & Inference Procedure
- Training
- Training 중에는 context-enhanced language model과 acoustic predictor가 함께 training 됨
- 그러면 total loss는:
- Continous codec의 경우 $\mathcal{L}_{total}=\mathcal{L}_{TF}+\mathcal{L}_{Cont}$
- Discrete codec의 경우 $\mathcal{L}_{total}=\mathcal{L}_{TF}+\mathcal{L}_{Disc}$
- Streaming Inference
- 논문은 target speaker의 short speech clip에서 semantic, acoustic prompt를 speaker prompt로 사용함
- 이때 clip은 randomly select 되고 clip end에 unfinished pronunciation이 포함될 수 있으므로 silence clip을 pad 하여 unexpected continuation을 방지 - 결과적으로 해당 prompt를 사용하여 StreamVoice는 source speech를 stream convert 함
- Discrete projection에서는 greedy decoding을 사용하여 probability가 가장 높은 codec token을 선택함
- 추가적으로 real-time 추론을 보장하기 위해 LM에서 key-value cache를 사용하여 redundant calculation을 줄임
- 여기서 source speech의 start/end는 ASR이나 Voice Activity Detection (VAD)로 확인할 수 있으므로 input에 window attention이나 slide attention은 사용되지 않음
- 논문은 target speaker의 short speech clip에서 semantic, acoustic prompt를 speaker prompt로 사용함
3. Experiments
- Settings
- Results
- Zero-Shot Evaluation
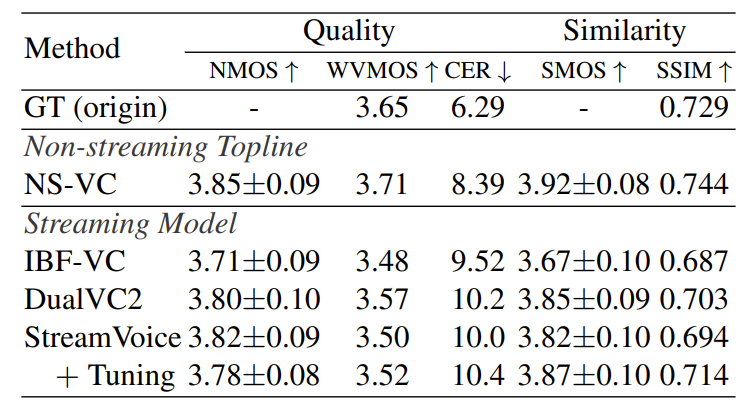
- Unseen speaker에 대한 non-streaming/streaming VC 설정 모두에서 StreamVoice가 가장 우수한 성능을 보임

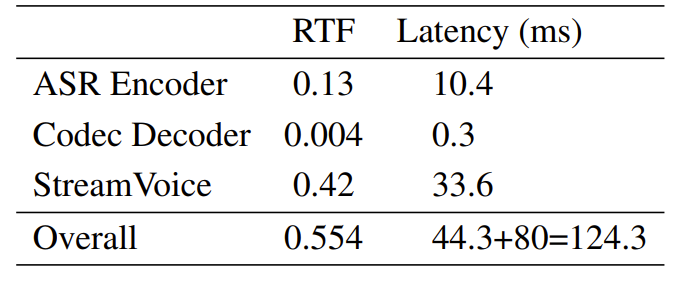
- StreamVoice의 전체 pipeline RTF는 1 미만으로 real-time requirement를 충족함
- In-dataset Evaluation
- Seen speaker에 대해서도 StreamVoice의 성능이 가장 뛰어남
- Ablation Study
- StreamVoice의 각 component를 제거하는 경우 성능 저하가 발생함

- Dependency Analysis
- ASR, codec selection과 StreamVoice 성능 간의 관계를 확인해 보면,
- Non-streaming ASR의 semantic feature를 사용하는 StreamVoice가 streaming ASR을 사용하는 경우보다 더 뛰어난 성능을 보임

- Codec 측면에서 Large w/ 8kpbs Audiodec을 사용하면 성능 향상을 달성할 수 있지만, 추론 속도가 크게 저하됨
- 즉, StreamVoice에서 codec 구성은 conversion 품질과 추론 속도에 모두 영향을 줌

반응형
'Paper > Conversion' 카테고리의 다른 글
댓글