

티스토리 뷰
Paper/ETC
[Paper 리뷰] Score-based Generative Modeling through Stochastic Differential Equations
feVeRin 2024. 5. 18. 14:58반응형
Score-based Generative Modeling through Stochastic Differential Equations
- Generative modeling은 noise로부터 data를 생성하는 것을 목표로 함
- Score-based Generative Modeling with SDE
- Noise를 inject 하여 complex data distribution을 known prior distribution으로 변환하는 Stochastic Differential Equation (SDE)와 denoising을 통해 prior를 data distribution으로 변환하는 reverse-time SDE를 활용
- Score-based modeling을 활용하여 neural network를 통해 time-dependent gradient field를 추정하고 numerical SDE solver를 사용해 sample을 생성
- Discretized reverse-time SDE의 evolution 과정에서 error를 correct 하는 predictor-corrector framework를 도입
- 논문 (ICLR 2021) : Paper Link
1. Introduction
- Probabilistic generative model은 noise를 통해 training data를 sequentially corrupt 한 다음, 생성을 위해 해당 corruption을 reverse 하는 방식을 학습함
- 이때 대표적인 score-based generative model로써 다음의 2가지 approach가 제시됨:
- Score Matching with Langevin Dynamics (SMLD)는 각 noise scale에서 data에 대한 log probability density의 gradient (i.e., score)를 추정한 다음, Langevin dynamics를 통해 sampling 함
- Denoising Diffusion Probabilistic Model (DDPM)은 reverse distribution을 tractable 하게 만들고, probabilistic model을 활용해 각 noise corruption을 reverse 함
- Continuous state space의 경우, DDPM은 각 noise scale에서 score를 implicitly compute 함
- 특히 이러한 score-based generative model은 image를 비롯한 여러 생성 작업에서 우수한 성능을 보이고 있음
- 한편으로 Stochastic Differential Equation (SDE)를 활용하면 새로운 sampling method를 통해 기존 score-based model을 generalize 할 수 있음
- 이때 finite noise distribution으로 perturbing 하는 대신, diffusion process에 따라 time-evolving continuous distribtuion을 고려함
- 해당 process를 통해 data point를 random noise로 diffuse 하고, trainable parameter가 필요 없는 prescribed SDE를 사용할 수 있음 - 반대로 reverse process를 수행하면 sample 생성을 위한 data에 random noise를 mold 할 수 있음
- 해당 reverse process는 reverse-time SDE를 만족하고, marginal probability density가 주어졌을 때 forward SDE로부터 유도됨
- 이때 finite noise distribution으로 perturbing 하는 대신, diffusion process에 따라 time-evolving continuous distribtuion을 고려함
- 결과적으로 아래 그림과 같이 time-dependent neural network를 training 하여 score를 추정한 다음, numerical SDE solver를 사용하여 sample을 생성함으로써 reverse-time SDE를 근사할 수 있음
- 이때 대표적인 score-based generative model로써 다음의 2가지 approach가 제시됨:

-> 그래서 score-based model에 SDE를 적용한 새로운 generative modeling 방식을 제안
- Score-based Generative Modeling with SDE
- Flexible Sampling and Likelihood Computation
- General-purpose SDE solver를 사용하여 sampling을 위한 reverse-time SDE를 통합
- 한편으로 numerical SDE solver와 score-based MCMC solver를 결합한 Predictor-Corrector (PC) sampler를 도입해 기존의 sampling 방식을 개선
- 추가적으로 Ordinary Differential Equation (ODE)에 기반한 deterministic sampler는 exact likelihood computation, flexible data manipulation을 지원 - Controllable Generation
- Conditional reverse-time SDE는 unconditional score을 통해 추정할 수 있기 때문에, training 중에 사용할 수 없는 information을 condition으로 사용할 수 있음
- 결과적으로 이를 통해 class-conditional generation, image inpainting 등을 re-training 없이 지원 가능 - Unified Framework
- Score-based generative model을 개선하기 위해 다양한 SDE에 대한 unified framework를 제시
- 특히 SMLD와 DDPM은 2개의 개별적인 SDE를 discretization 하여 framework에 통합됨
- Flexible Sampling and Likelihood Computation
< Overall of This Paper >
- Score-based generative model과 SDE를 결합한 generation framework를 제시
- Discretized reverse-time SDE 과정에서 error를 correct 하는 predictor-corrector framework를 도입
- 결과적으로 기존보다 뛰어난 image 생성 성능을 달성
2. Background
- Denoising Score Matching with Langevin Dynamics (SMLD)
- $p_{\sigma}(\tilde{\mathbf{x}}|\mathbf{x}):=\mathcal{N}(\tilde{\mathbf{x}};\mathbf{x},\sigma^{2}I)$를 perturbation kernel, $p_{data}(\mathbf{x})$가 data distribution일 때 $p_{\sigma}(\tilde{\mathbf{x}}):=\int p_{data}(\mathbf{x})p_{\sigma}(\tilde{\mathbf{x}}|\mathbf{x})d\mathbf{x}$라 하자
- 여기서 positive noise scale $\sigma_{\min}=\sigma_{1}<\sigma_{2}<...<\sigma_{N}=\sigma_{\max}$를 고려하면,
- 일반적으로 $\sigma_{\min}$은 $p_{\sigma_{\min}}(\mathbf{x})\approx p_{data}(\mathbf{x})$와 같이 매우 작고 $\sigma_{\max}$는 $p_{\sigma_{\max}}(\mathbf{x})\approx\mathcal{N}(\mathbf{x};0,\sigma^{2}_{\max}I)$와 같이 매우 큼 - Noise Conditional Score Network (NCSN) $s_{\theta}(\mathbf{x},\sigma)$는 denoising score matching objective의 weighted sum으로써:
(Eq. 1) $\theta^{*}=\arg\min_{\theta}\sum_{i=1}^{N}\sigma_{i}^{2}\mathbb{E}_{p_{data}(\mathbf{x})}\mathbb{E}_{p_{\sigma_{i}}(\tilde{\mathbf{x}}|\mathbf{x})}\left[ || s_{\theta}(\tilde{\mathbf{x},\sigma_{i}})-\nabla_{\tilde{\mathbf{x}}}\log p_{\sigma_{i}}(\tilde{\mathbf{x}}|\mathbf{x}) ||_{2}^{2}\right]$
- 충분한 data와 model capacity가 주어지면, optimal score-based model $s_{\theta^{*}}(\mathbf{x},\sigma)$는 $\sigma\in\{\sigma_{i}\}_{i=1}^{N}$의 모든 곳에서 $\nabla_{\mathbf{x}}\log p_{\sigma}(\mathbf{x})$와 일치함 - 여기서 sampling을 위해 $M$ step의 Langevin MCMC를 수행하여, $p_{\sigma_{i}}(\mathbf{x})$에 대한 sample을 sequential 하게 얻음:
(Eq. 2) $\mathbf{x}_{i}^{m}=\mathbf{x}_{i}^{m-1}+\epsilon_{i}s_{\theta^{*}}(\mathbf{x}_{i}^{m-1},\sigma_{i})+\sqrt{2\epsilon_{i}}\mathbf{z}_{i}^{m},\,\,\, m=1,2,...,M$
- $\epsilon_{i}>0$ : step size, $\mathbf{z}_{i}^{m}$ : standard normal
- 위 식은 $i <N$일 때 $i=N,N-1,...,1$에 대해 $\mathbf{x}_{N}^{0}\sim\mathcal{N}(\mathbf{x}|0,\sigma_{\max}^{2}I)$를 적용하고, $\mathbf{x}_{i}^{0}=\mathbf{x}_{i+1}^{M}$ - 모든 $i$에 대해 $M\rightarrow \infty, \epsilon_{i}\rightarrow \infty$이면, $\mathbf{x}_{1}^{M}$은 regularity condition하에서 $p_{\sigma_{\min}}(\mathbf{x})\approx p_{data}(\mathbf{x})$의 exact sample이 됨
- 여기서 positive noise scale $\sigma_{\min}=\sigma_{1}<\sigma_{2}<...<\sigma_{N}=\sigma_{\max}$를 고려하면,
- Denoising Diffusion Probabilistic Models (DDPM)
- Positive noise scale sequence $0<\beta_{1},\beta_{2},...,\beta_{N}<1$을 고려해 보자
- 각 training data point $\mathbf{x}_{0}\sim p_{data}(\mathbf{x})$에 대해 discrete Markov chain $\{\mathbf{x}_{0},\mathbf{x}_{1},...,\mathbf{x}_{N}\}$은 $p(\mathbf{x}_{i}|\mathbf{x}_{i-1})=\mathcal{N}(\mathbf{x}_{i};\sqrt{1-\beta_{i}}\mathbf{x}_{i-1},\beta_{i}I)$과 같이 구성됨
- 따라서 $\alpha_{i}:=\prod_{j=1}^{i}(1-\beta_{j})$일 때 $p_{\alpha_{i}}(\mathbf{x}_{i}|\mathbf{x}_{0})=\mathcal{N}(\mathbf{x}_{i};\sqrt{\alpha_{i}}\mathbf{x}_{0},(1-\alpha_{i})I)$ - 이때 앞선 SMLD와 비슷하게, DDPM은 perturbed data distribution을 $p_{\alpha_{i}}(\tilde{\mathbf{x}}):=\int p_{data}(\mathbf{x})p_{\alpha_{i}}(\tilde{\mathbf{x}}|\mathbf{x})d\mathbf{x}$와 같이 나타낼 수 있고, noise scale은 $\mathbf{x}_{N}$이 $\mathcal{N}(0,I)$에 따라 근사적으로 분포되도록 prescribe 됨
- 그러면 reverse direction에서 variational Markov chain은 $p_{\theta}(\mathbf{x}_{i-1}|\mathbf{x}_{i})=\mathcal{N}\left(\mathbf{x}_{i-1};\frac{1}{\sqrt{1-\beta_{i}}}(\mathbf{x}_{i}+\beta_{i}s_{\theta}(\mathbf{x}_{i},i)),\beta_{i}I\right)$로 parameterize 되고 Evidence Lower BOund (ELBO)의 re-weighted version으로 training 됨:
(Eq. 3) $\theta^{*}=\arg\min_{\theta}\sum_{i=1}^{N}(1-\alpha_{i})\mathbb{E}_{p_{data}(\mathbf{x})}\mathbb{E}_{p_{\alpha_{i}}(\tilde{\mathbf{x}}|\mathbf{x})}\left[ || s_{\theta}(\tilde{\mathbf{x}}_{i},i)-\nabla_{\tilde{\mathbf{x}}}\log p_{\alpha_{i}}(\tilde{\mathbf{x}}|\mathbf{x})||_{2}^{2}\right]$ - (Eq. 3)을 solve 하면 optimal model $s_{\theta^{*}}(\mathbf{x},i)$를 얻을 수 있고, $\mathbf{x}_{N}\sim\mathcal{N}(0,I)$에서 시작하여 다음의 추정된 reverse Markov chain을 따라 sample을 생성할 수 있음:
(Eq. 4) $\mathbf{x}_{i-1}=\frac{1}{\sqrt{1-\beta_{i}}}(\mathbf{x}_{i}+\beta_{i}s_{\theta^{*}}(\mathbf{x}_{i},i))+\sqrt{\beta_{i}}\mathbf{z}_{i},\,\,\, i=N,N-1,...,1$
- 해당 방식은 graphical model $\prod_{i=1}^{N}p_{\theta}(\mathbf{x}_{i-1}|\mathbf{x}_{i})$에서 ancestral sampling을 수행하는 것과 같으므로, ancestral sampling이라고 함 - (Eq. 1)과 마찬가지로 (Eq. 3) 역시 denoising score matching objective의 weighted sum으로써, optimal model $s_{\theta^{*}}(\tilde{\mathbf{x}},i)$가 perturbed data distribution의 score $\nabla_{\mathbf{x}}\log p_{\alpha_{i}}(\mathbf{x})$와 match 됨을 나타냄
- 특히 (Eq. 1)과 (Eq. 3)의 $i$-th summand의 weight $\sigma_{i}^{2}$와 $(1-\alpha_{i})$는 동일한 functional form에 해당하는 perturbation kernel $\sigma_{i}^{2}\propto 1/\mathbb{E}[||\nabla_{\mathbf{x}}\log p_{\sigma_{i}}(\tilde{\mathbf{x}}|\mathbf{x}) ||_{2}^{2}], \,\, (1-\alpha_{i})\propto 1/\mathbb{E}[||\nabla_{\mathbf{x}}\log p_{\alpha_{i}}(\tilde{\mathbf{x}}|\mathbf{x}) ||_{2}^{2}]$과 관련되어 있음
- 각 training data point $\mathbf{x}_{0}\sim p_{data}(\mathbf{x})$에 대해 discrete Markov chain $\{\mathbf{x}_{0},\mathbf{x}_{1},...,\mathbf{x}_{N}\}$은 $p(\mathbf{x}_{i}|\mathbf{x}_{i-1})=\mathcal{N}(\mathbf{x}_{i};\sqrt{1-\beta_{i}}\mathbf{x}_{i-1},\beta_{i}I)$과 같이 구성됨
3. Score-based Generative Modeling with SDEs
- 논문은 아래 그림과 같이 기존의 data perturbation을 infinite noise scale로 generalize 하여 noise가 증가함에 따라 perturbed data distribution이 SDE에 따라 evolve 하는 것을 목표로 함
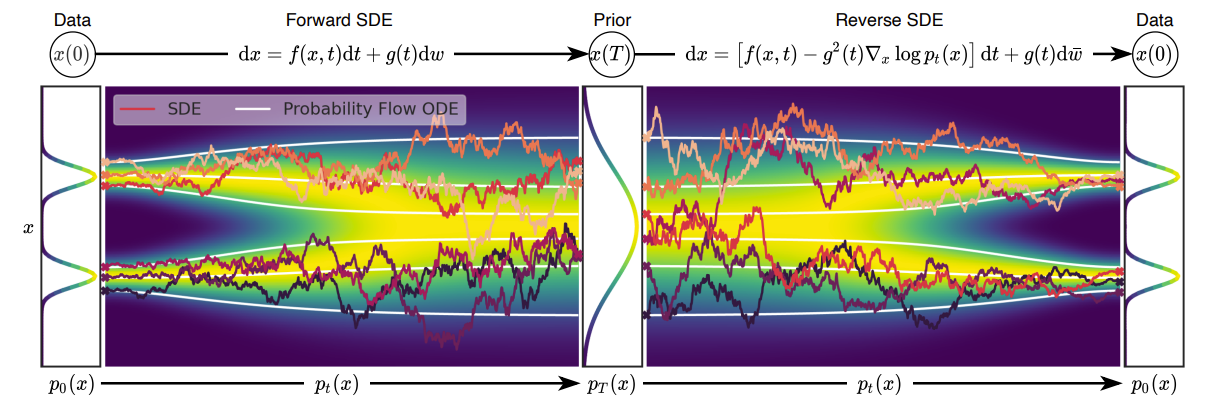
- Perturbing Data with SDEs
- 먼저 $i.i.d.$ sample의 dataset에 대해 $\mathbf{x}(0)\sim p_{0}$와 같은 continuous time variable $t \in [0,T]$로 index 된 diffusion process $\{\mathbf{x}(t)\}_{t=0}^{T}$를 구성하자
- 이때 $\mathbf{x}(T)\sim p_{T}$는 tractable form을 가지고 $p_{0}$는 data distribution이고 $p_{T}$는 prior distribution
- 따라서 diffusion process는 Ito SDE에 대한 solution으로 모델링 될 수 있음:
(Eq. 5) $d\mathbf{x}=f(\mathbf{x},t)dt+g(t)d\mathbf{w}$
- $\mathbf{w}$ : standard Wiener process (Brownian motion)
- $f(\cdot, t) : \mathbb{R}^{d}\rightarrow \mathbb{R}^{d}$ : $\mathbf{x}(t)$의 drift coefficient로써 vector-valued function
- $g(\cdot):\mathbb{R}\rightarrow\mathbb{R}$ : $\mathbf{x}(t)$의 diffusion coefficient로써 scalar function - 쉬운 계산을 위해 diffusion coefficient가 $d\times d$ matrix가 아닌 scalar이고 $\mathbf{x}$에 의존하지 않는다고 가정하자
- 이때 SDE는 coefficient가 state, time 모두에서 globally Lipschitz인 unique strong solution을 가짐
- 그러면 $\mathbf{x}(t)$의 probability density를 $p_{t}(\mathbf{x})$로, $0\leq s < t \leq T$에 대해 $\mathbf{x}(s)$에서 $\mathbf{x}(t)$까지의 transition kernel을 $p_{st}(\mathbf{x}(t)|\mathbf{x}(s))$로 나타낼 수 있음 - 일반적으로 $p_{T}$는 fixed mean과 variance를 가지는 Gaussian distribution과 같이 $p_{0}$에 대한 information이 포함되지 않은 unstructured prior distribution임
- 따라서 data distribution을 fixed prior distribution으로 diffuse 하는 (Eq. 5)에 대해 다양한 SDE를 설계할 수 있음
- Generating Samples by Reversing the SDE
- $\mathbf{x}(T)\sim p_{T}$ sample에서 시작해 reverse process를 수행하면 $\mathbf{x}_{0}\sim p_{0}$의 sample을 얻을 수 있음
- 이때 diffusion process의 reverse 역시 diffusion process이고, 이는 reverse-time SDE를 통해 계산 가능함:
(Eq. 6) $d\mathbf{x}=[f(\mathbf{x},t)-g(t)^{2}\nabla_{\mathbf{x}}\log p_{t}(\mathbf{x})]dt+g(t)d\bar{\mathbf{w}}$
- $\bar{\mathbf{w}}$ : time이 $T$에서 $0$으로 backward로 진행될 때의 standard Wiener process
- $dt$ : infinitesimal negative timestep - 각 margnial distribution의 score $\nabla_{\mathbf{x}}\log p_{t}(\mathbf{x})$가 모든 $t$에 대해 known이면, (Eq. 6)에서 reverse diffusion process를 유도하고 $p_{0}$에서 sampling 하도록 simulate 할 수 있음
- 이때 diffusion process의 reverse 역시 diffusion process이고, 이는 reverse-time SDE를 통해 계산 가능함:
- Estimating Scores for the SDE
- Distribution의 score는 score matching을 통해 score-based model을 training 함으로써 얻을 수 있음
- 즉, $\nabla_{\mathbf{x}}\log p_{t}(\mathbf{x})$를 추정하기 위해 (Eq. 1), (Eq. 3)에 대한 continuous generalization을 통해 time-dependent score-based model $s_{\theta}(\mathbf{x},t)$을 training 함:
(Eq. 7) $\theta^{*}=\arg\min_{\theta}\mathbb{E}_{t}\left\{ \lambda(t)\mathbb{E}_{\mathbf{x}(0)}\mathbb{E}_{\mathbf{x}(t)|\mathbf{x}(0)}\left[ || s_{\theta}(\mathbf{x}(t),t)-\nabla_{\mathbf{x}(t)}\log p_{0t}(\mathbf{x}(t)|\mathbf{x}(0)) ||_{2}^{2}\right]\right\}$
- $\lambda : [0,T]\rightarrow \mathbb{R}_{>0}$ : positive weighting function
- $t$ : $[0,T]$에서 uniformly sample 되는 값
- $\mathbf{x}(0)\sim p_{0}(\mathbf{x})$, $\mathbf{x}(t) \sim p_{0t}(\mathbf{x}(t)|\mathbf{x}(0))$ - 충분한 data와 model capacity를 갖춘 score matching은 (Eq. 7)에 대한 optimal solution $s_{\theta^{*}}(\mathbf{x},t)$이 거의 모든 $\mathbf{x}, t$에 대해 $\nabla_{\mathbf{x}}\log p_{t}(\mathbf{x})$와 동일하다는 것을 보장함
- 이때 SMLD와 DDPM에서는 일반적으로 $\lambda \propto 1/\mathbb{E}\left[|| \nabla_{\mathbf{x}(t)}\log p_{0t}(\mathbf{x}(t)|\mathbf{x}(0))||_{2}^{2}\right]$를 사용
- (Eq. 7)은 denoising score matching을 사용하지만 sliced score matching, finite-difference score matching을 사용할 수도 있음 - 한편으로 (Eq. 7)을 solve 하기 위해서는 transition kernel $p_{0t}(\mathbf{x}(t)|\mathbf{x}(0))$이 필요함
- 이때 $f(\cdot,t)$가 affine이면 transition kernel은 항상 Gaussian distribution임
- 이때 평균과 분산은 closed-form으로 알려지고, standard technique을 통해 얻을 수 있음 - General SDE의 경우, Kolmogorov forward equation을 solve 하여 $p_{0t}(\mathbf{x}(t)|\mathbf{x}(0))$를 얻어짐
- 또는 SDE를 simulate 하여 $p_{0t}(\mathbf{x}(t)|\mathbf{x}(0))$에서 sampling 하고 (Eq. 7)의 denoising score matching을 대체하는 sliced score matching을 적용할 수도 있음
- 즉, $\nabla_{\mathbf{x}}\log p_{t}(\mathbf{x})$를 추정하기 위해 (Eq. 1), (Eq. 3)에 대한 continuous generalization을 통해 time-dependent score-based model $s_{\theta}(\mathbf{x},t)$을 training 함:
- Examples: VE, VP SDEs and Beyond
- SMLD와 DDPM에서 사용된 perturbation은 두 가지의 서로 다른 SDE의 discretization으로 볼 수 있음
- $N$개의 noise scale을 사용하는 경우 SMLD의 각 perturbation kernel $p_{\sigma_{i}}(\mathbf{x}|\mathbf{x}_{0})$은 다음의 Markov chain에서 $\mathbf{x}_{i}$의 distribution에 해당함:
(Eq. 8) $\mathbf{x}_{i}=\mathbf{x}_{i-1}+\sqrt{\sigma_{i}^{2}-\sigma^{2}_{i-1}}\mathbf{z}_{i-1},\,\, i=1,...,N$
- $\mathbf{z}_{i-1}\sim\mathcal{N}(0,I)$, $\sigma_{0}=0$ - $N\rightarrow \infty$의 극한을 취하면, $\{\sigma_{i}\}_{i=1}^{N}$은 $\sigma(t)$가 되고, $\mathbf{z}_{i}$는 $\mathbf{z}(t)$가 되고, Markov chain $\{\mathbf{x}_{i}\}_{i=1}^{N}$은 continuous time variable $t\in[0,1]$에 대해 continuous stochastic process $\{\mathbf{x}(t)\}_{t=0}^{1}$이 됨
- 그러면 process $\{\mathbf{x}(t)\}_{t=0}^{1}$은 다음의 SDE로 주어짐:
(Eq. 9) $d\mathbf{x}=\sqrt{\frac{d[\sigma^{2}(t)]}{dt}}d\mathbf{w}$ - DDPM의 perturbation kernel $\{p_{\alpha_{i}}(\mathbf{x}|\mathbf{x}_{0})\}_{i=1}^{N}$과 마찬가지로 discrete Markov chain은:
(Eq. 10) $\mathbf{x}_{i}=\sqrt{1-\beta_{i}}\mathbf{x}_{i-1}+\sqrt{\beta_{i}}\mathbf{z}_{i-1},\,\,i=1,...,N$ - 이때 $N\rightarrow \infty$이면, (Eq. 10)은 다음의 SDE로 수렴함:
(Eq. 11) $d\mathbf{x}=-\frac{1}{2}\beta(t)\mathbf{x}dt+\sqrt{\beta(t)}d\mathbf{w}$
- 그러면 process $\{\mathbf{x}(t)\}_{t=0}^{1}$은 다음의 SDE로 주어짐:
- 결과적으로 SMLD와 DDPM의 noise perturbation은 (Eq. 9), (Eq. 11)의 SDE에 대한 discretization에 해당함
- 여기서 (Eq. 9)의 SDE는 $t\rightarrow \infty$일 때 항상 exploding variance를 가지는 process이지만, (Eq. 11)의 SDE는 initial distribution에 unit variance가 있을 때, fixed variance를 가지는 process를 제공함
- 따라서 (Eq. 9)를 Variance Exploding (VE) SDE, (Eq. 11)을 Variance Preserving (VP) SDE라고 함
- $N$개의 noise scale을 사용하는 경우 SMLD의 각 perturbation kernel $p_{\sigma_{i}}(\mathbf{x}|\mathbf{x}_{0})$은 다음의 Markov chain에서 $\mathbf{x}_{i}$의 distribution에 해당함:
4. Solving the Reverse SDE
- Time-dependent score-based model $s_{\theta}$를 training 한 다음, 해당 모델을 사용하여 reverse-time SDE를 구성하고 numerical approach로 simulate 하여 $p_{0}$에서 sample을 생성할 수 있음
- General-Purpose Numerical SDE Solvers
- Numerical solver는 SDE에 대한 approximate trajectory를 제공함
- 이때 Euler-Maruyama, Stochastic Runge-Kutta method와 같은 general-purpose solver를 reverse-time SDE에 적용하여 sample을 생성할 수 있음
- (Eq. 4)에 해당하는 DDPM의 ancestral sampling은, (Eq. 11)의 reverse-time VP SDE의 특수한 discretization에 해당하지만, 그 외에 새로운 SDE에 대한 ancestral sampling을 유도하는 것은 어려움
- 따라서 논문은 forward SDE와 동일한 방식으로 reverse-time SDE를 discretize 한 reverse diffusion sampler를 사용함 - 결과적으로 아래 표와 같이 reverse diffusion sampler는 CIFAR-10의 SMLD, DDPM 모두에서 ancestral sampling보다 더 나은 성능을 발휘하는 것으로 나타남

- Predictor-Corrector Samplers
- 일반적인 SDE와 달리 score-based model $s_{\theta^{*}}(\mathbf{x},t)\approx \nabla_{\mathbf{x}}\log p_{t}(\mathbf{x})$가 있으므로 Lagnevin MCMC나 HMC를 사용해 $p_{t}$에서 직접 sampling 하고 numerical SDE solver의 solution을 correct 할 수 있음
- 구체적으로 아래 [Algorithm 1]과 같이,
- 먼저 각 time step에서 numerical SDE solver는 next time step의 sample estimate를 제공하는 predictor 역할을 수행함
- 그러면 score-based MCMC approach는 추정된 sample의 marginal distribution을 correct 하는 corrector 역할을 수행함
- 이는 equation solving을 위한 numerical continuation technique인 Predictor-Corrector method와 유사하므로, 해당 방식을 Predictor-Corrector (PC) sampler라고 함
- PC sampler는 SMLD에서 identity function을 predictor로, annealed Langevin dynmaics를 corrector로 사용
- DDPM에서는 ancestral sampling을 predictor로, identity를 corrector로 사용
- 구체적으로 아래 [Algorithm 1]과 같이,

- SMLD와 DDPM에서 PC sampler의 효과를 확인해 보면
- 모든 predictor에 대해 각 predictor step에 하나의 corrector step을 추가하면 computation이 두배로 증가하지만, sample 품질은 향상되는 것으로 나타남
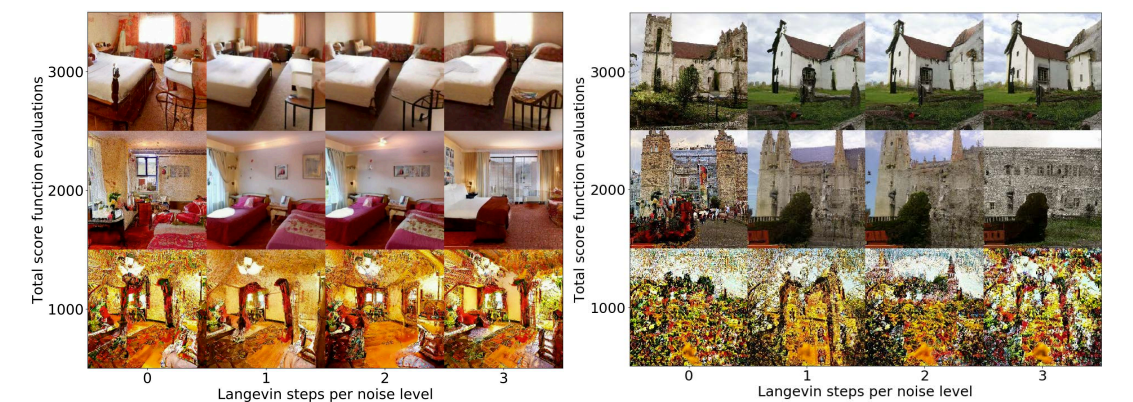
- 아래 그림과 같이 LSUN image에 대해 (Eq. 7)의 VE SDE로 training 된 모델의 합성 결과를 확인해 보면 PC sampler를 사용하는 것이 predictor-only sampler를 사용하는 것보다 우수한 결과를 보임
- Predictor와 Corrector 간에 computation이 split 될 때 가장 우수한 sample이 얻어짐
- Probability Flow and Connection to Neural ODEs
- Score-based model에서 reverse-time SDE를 solve 하기 위해 또 다른 numerical method를 활용할 수도 있음
- 특히 모든 diffusion process에 대해 SDE와 동일한 trajcetory의 margina probability density $\{p_{t}(\mathbf{x})\}_{t=0}^{T}$를 share 하는 deterministic process가 존재하고, 이는 ODE를 만족함:
(Eq. 13) $d\mathbf{x} = \left[ f(\mathbf{x}, t) - \frac{1}{2} g(t)^{2} \nabla_{\mathbf{x}} \log p_{t}(\mathbf{x})\right] dt$ - 즉, score가 known이면 SDE를 통해 결정론적으로 얻어지고, 이때 (Eq. 13)의 ODE를 probability flow ODE라고 함
- 이때 neural network에 기반한 time-dependent score-based model을 score function으로 근사하는 neural ODE를 통해 (Eq. 13)의 density를 계산할 수 있음
- 특히 모든 diffusion process에 대해 SDE와 동일한 trajcetory의 margina probability density $\{p_{t}(\mathbf{x})\}_{t=0}^{T}$를 share 하는 deterministic process가 존재하고, 이는 ODE를 만족함:

- Exact Likelihood Computation
- Nerual ODE를 사용해 input data에 대한 exact likelihodd를 계산할 수 있음
- 실제로 위 표와 같이 동일한 DDPM에 대해 probability flow를 사용하면 ELBO 보다 더 나은 성능을 얻을 수 있음
- Manipulating Latent Representation
- (Eq. 13)을 통합함으로써 모든 data point $\mathbf{x}(0)$를 latent space $\mathbf{x}(T)$로 encoding 하고, reverse SDE에 대한 ODE를 통해 decoding을 수행할 수 있음
- 결과적으로 아래 그림과 같이 iterpolation, temperature scaling을 위해 해당 latent representation을 manipulate 할 수 있음
- Efficient Sampling
- Neural ODE를 통해 서로 다른 final condition $\mathbf{x}(T)\sim p_{T}$에서 (Eq. 13)을 solve 하여 $\mathbf{x}(0)\sim p_{0}$를 sampling 함
- 특히 fixed discretization strategy와 corrector를 함께 사용했을 때, 우수한 sample을 얻을 수 있음
- Black-box ODE solver의 경우, 더 나은 sample을 생성하면서 efficiency를 위한 trade-off를 만족할 수 있음
- 아래 왼쪽 그림과 같이 large error tolerance를 사용하면, visual quality에 영향을 주지 않으면서 function evaluation 수를 90% 줄이는 것이 가능함

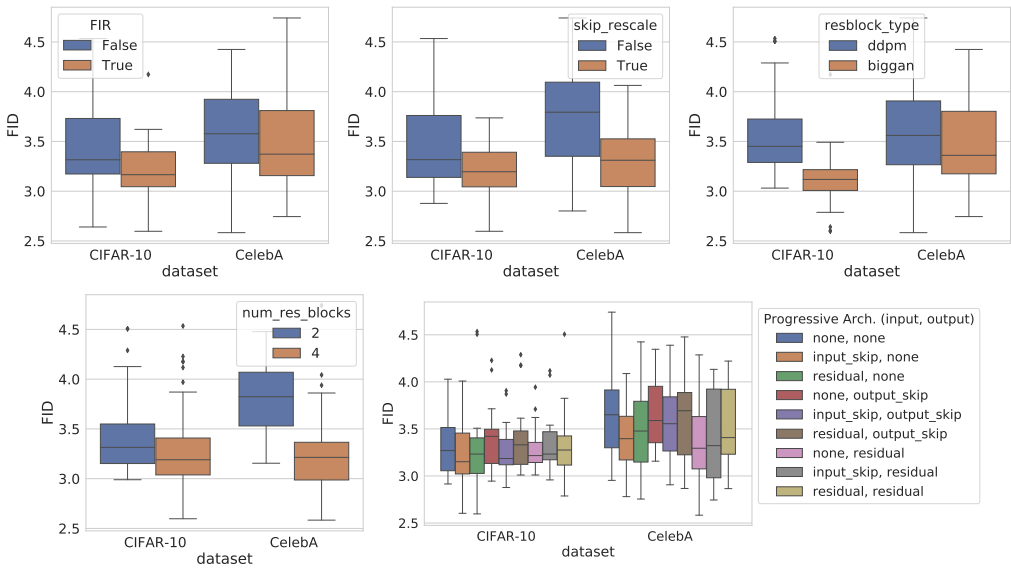
- Architecture Improvements
- VE, VP SDE를 사용하여 score-based model에 대한 몇 가지 architecture design을 explore 해보면
- VE SDE에 대한 optimal architecture인 NCSN++는 PC sampler를 사용하여 CIFAR-10에서 2.45 FID를 달성함
- 한편으로 VP SDE에 대한 optimal architecture인 DDPM++는 2.78 FID를 달성하는 것으로 나타남
- 특히 (Eq. 7)의 continuous training objective를 적용하고 network depth를 늘리는 경우, sample 품질을 더욱 향상할 수 있음
- 실제로 해당하는 NCSN++ cont.나 DDPM++ cont.가 다른 architecture 보다 가장 우수한 성능을 보임
5. Controllable Generation
- 논문에서 제안된 framework의 continuous structure를 통해 $p_{0}$ 뿐만 아니라 $p_{t}(\mathbf{y}|\mathbf{x}(t))$가 알려진 경우 $p_{0}(\mathbf{x}(0)|\mathbf{y})$에서도 sampling을 수행할 수 있음
- (Eq. 5)와 같이 forward SDE가 주어지면, $p_{T}(\mathbf{x}(T)|\mathbf{y})$에서 시작해 conditional reverse-time SDE를 solving 하여 $p_{t}(\mathbf{x}(t)|\mathbf{y})$에서 sampling 함:
(Eq. 14) $d\mathbf{x}=\{f(\mathbf{x},t)-g(t)^{2}[\nabla_{\mathbf{x}}\log p_{t}(\mathbf{x})+\nabla_{\mathbf{x}}\log p_{t}(\mathbf{y}|\mathbf{x})]\}dt+g(t)d\bar{\mathbf{w}}$ - 일반적으로 forward process의 gradient estimates $\nabla_\mathbf{x}\log p_{t}(\mathbf{y}|\mathbf{x}(t))$가 주어지면, score-based model을 통해 inverse problem을 solve 하기 위해 (Eq. 14)를 사용할 수 있음
- 이때 일부 case에 대해서는 $\log p_{t}(\mathbf{y}|\mathbf{x}(t))$를 학습하기 위해 개별적인 모델을 training 하거나 heuristics, domain knowledge를 사용하여 gradient를 추정할 수 있음 - 따라서 논문은 위 approach를 통해 class-conditional generation, image imputation, colorization task에 접근함
- 결과적으로 아래 그림과 같이 뛰어난 controllable generation 성능을 보이는 것을 확인할 수 있음
- (Eq. 5)와 같이 forward SDE가 주어지면, $p_{T}(\mathbf{x}(T)|\mathbf{y})$에서 시작해 conditional reverse-time SDE를 solving 하여 $p_{t}(\mathbf{x}(t)|\mathbf{y})$에서 sampling 함:

반응형
'Paper > ETC' 카테고리의 다른 글
댓글