

티스토리 뷰
Paper/Conversion
[Paper 리뷰] Blow: A Single-Scale Hyperconditioned Flow for Non-Parallel Raw-Audio Voice Conversion
feVeRin 2024. 8. 17. 11:46반응형
Blow: A Single-Scale Hyperconditioned Flow for Non-Parallel Raw-Audio Voice Conversion
- Many-to-Many voice conversion을 위해서는 non-parallel data를 활용할 수 있어야 함
- Blow
- Hypernetwork conditioning과 single-scale normalizing flow를 활용
- Single speaker identifier를 사용하여 frame-by-frame으로 end-to-end training 됨
- 논문 (NeurIPS 2019) : Paper Link
1. Introduction
- Raw audio는 intermediate representation을 사용하는 것보다 더 많은 model capacity와 큰 receptive field를 요구함
- 특히 Voice Conversion (VC)은 spoken content를 preserve 하면서 source speaker identity를 targeted identity로 변환하는 것을 목표로 함
- 이때 대부분의 VC system은 parallel data를 활용하여 supervised 방식으로 training 됨
- 즉, source/target speaker가 accurately temporal align 된 input/output pair가 필요함 - BUT, parallel data는 non-scalable 하고 수집하기 까다로우므로, 다양한 non-parallel data를 활용할 수 있어야 함
-> 그래서 non-parallel, many-to-many, raw-audio voice conversion을 지원하는 Blow를 제안
- Blow
- Mimimal supervision으로 end-to-end training 되는 normalizing flow architecture를 채택
- Individual audio frame과 해당 frame에서 speaker identity를 나타내는 identifier를 활용 - VC를 위한 더 나은 likelihood를 얻기 위해, forward-backward conversion mechanism, hypernetwork conditioning, shared speaker embedding, data augmentation을 도입
- Mimimal supervision으로 end-to-end training 되는 normalizing flow architecture를 채택
< Overall of Blow >
- Hyperconditioning과 normalizing flow architecture를 활용한 VC model
- 결과적으로 기존보다 뛰어난 conversion 성능을 달성
2. Flow-based Generative Models
- Flow-based generative model은 input sample $\mathbf{x}\in\mathcal{X}$에서 latent representation $\mathbf{z}\in\mathcal{Z}$으로의 bijective mapping $\mathbf{z}=f(\mathbf{x}), \mathbf{x}=f^{-1}(\mathbf{z})$를 학습함
- 이때 mapping $f$를 normalizing flow라고 하고, neural network로 parameterize 된 $k$개의 invertible transformation sequence $f=f_{1}\circ...\circ f_{k}$로 구성됨
- 따라서 동일한 dimensionality를 가지는 $\mathbf{x},\mathbf{z}$간의 relationship은:
$\mathbf{x}\triangleq \mathbf{h}_{0}\overset{f_{1}}{\longleftrightarrow} \mathbf{h}_{1} \overset{f_{2}}{\longleftrightarrow}\mathbf{h}_{2}...\overset{f_{k}}{\longleftrightarrow}\mathbf{h}_{k}\triangleq\mathbf{z}$ - 이때 realistic sample을 생성하기 위해서는 probability density $p(\mathcal{X})$를 모델링해야 함
- 일반적으로 해당 과정은 intractable 하지만, $f$를 사용하면 exact log-likelihood를 통해 모델링할 수 있음:
(Eq. 1) $L(\mathcal{X})=\frac{1}{|\mathcal{X}|}\sum_{i=1}^{|\mathcal{X}|}\log (p(\mathbf{x}_{i}))$ - Single sample $\mathbf{x}$에 대한 variable change, inverse function theorem, compositionality를 적용하면:
$\log (p(\mathbf{x}))=\log (p(\mathbf{z}))+\sum_{i=1}^{k}\log \left| \det \left(\frac{\partial f_{i}(\mathbf{h}_{i-1})}{\partial \mathbf{h}_{i-1}}\right)\right|$
- $\frac{\partial f_{i}(\mathbf{h}_{i-1}) }{\partial \mathbf{h}_{i-1}}$ : $\mathbf{h}_{i-1}$에서 $f_{i}$의 Jacobian matrix, Log-determinant는 $f_{i}$에 의해 발생한 log-dentisty의 변화를 나타냄
- 실적용에서는 determinant를 빠르게 계산하고 invertibility를 보장하기 위해 $f_{i}$로 triangular Jacobian matrix를 사용하고, 빠른 sampling을 위해 $p(\mathbf{z})$에 대해 isotropic unit Gaussian을 채택
- 일반적으로 해당 과정은 intractable 하지만, $f$를 사용하면 exact log-likelihood를 통해 모델링할 수 있음:
- $f$와 $f_{i}$의 parameterization을 위한 structure로써 RealNVP와 Glow를 고려할 수 있음
- RealNVP는 batch normalization, masked convolution, affine coupling layer로 구성된 block structure를 활용
- 이때 $2\times 2$ squeezing operation과 alterning checkerboard, channel-wise mask를 combine 함 - Glow는 batch normalization을 activation normalization (ActNorm)으로 대체하고, invertible $1\times 1$ convolution을 통한 channel-wise mixing을 도입
- 구조적으로는 $2\times 2$ squeezing operation과 32~64 flow step으로 구성된 3~6개의 block을 활용함
- 해당 block은 ActNorm, $1\times 1$ invertible convolution, affine coupling layer로 구성됨
- RealNVP는 batch normalization, masked convolution, affine coupling layer로 구성된 block structure를 활용
- Glow, RealNVP 모두 다양한 resoultion에서 $\mathbf{z}$의 component를 factor out 하는 multi-scale structure를 가짐
- 이를 통해 다양한 granularity에서 representation의 intermediary level을 정의할 수 있음
3. Blow
- Blow는 Glow를 기반으로 VC를 위한 추가적인 modification을 적용함
- 이때 single-scale structure, 각각 더 적은 flow를 가지는 many block, forward-backward conversion mechanism, hyperconditioning module, shared speaker embedding, data agumentation의 방법을 활용
- 구조적으로는 alternate pattern과 flow step을 가지는 1D $2\times$ squeeze operation을 사용함
- Flow step은 channel mixer로 사용되는 linear invertible layer와 ActNorm, affine coupling network로 구성됨
- Coupling network는 ReLU activation을 포함한 1D convolution과 hyperconvolution으로 구성됨
- 여기서 $512\times 512$ channel에 대해 last convolution, hyperconvolution은 3의 kernel width를 가지고, intermediate convolution은 1의 kernel width를 사용 - Same speaker embedding은 모든 coupling network에 전달되고 각 hyperconvolution에 대해 independently adapt 됨
- 결과적으로 Blow는 output $\mathbf{z}$를 unit isotropic Gaussian과 비교하고 $\mathbf{z}$의 dimensionality로 normalize 된 (Eq. 1)의 log-likelihood $L$를 최적화함
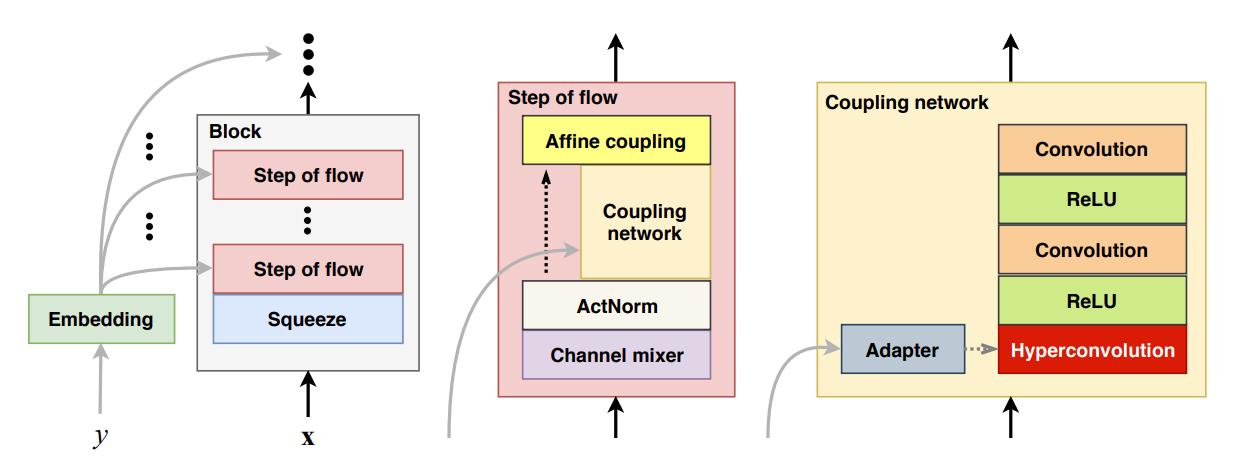
- Single-Scale Structure
- Multi-scale structure는 intermediary level representation을 효과적으로 처리하고 gradient flow를 encourage 해 normalizing flow의 training을 용이하게 함
- BUT, VC task에서 speaker identity trait는 대부분 coarser level representation에 존재함
- 추가적으로, mutli-scale structure 대신 block 전체에 대해 same input dimensionality를 적용해도 gradient flow에는 문제가 없고, 오히려 더 나은 log-likelihood를 얻을 수 있음
- 즉, log-determinant term이 모든 flow step에서 factor out 되기 때문에 gradient가 block activation을 factoring out 하지 않고도 flow 할 수 있음 - 결과적으로 block activation이 subsequent block에서 further processing 되므로, Blow는 single-scale structure 만으로도 더 나은 log-likelihood를 얻게 됨
- Many Blocks
- 기존의 flow-based image generation model은 $32\times 32$와 $256\times 256$ pixel 사이의 image를 처리함
- Raw audio에서 16kHz의 256 sample은 16ms에 해당하므로, speech construct를 capture 하기에 불충분함
- 특히 phoneme duration은 50~180ms 사이에 위치하므로 phoneme transition을 모델링하기 위해서는 더 긴 length가 필요 - 따라서 raw audio 모델링을 위해서는 input/receptive field를 늘려야 함
- 이때 WaveGlow와 같은 flow-based audio model은 최대 28 dilation을 지원하는 WaveNet-style coupling network를 활용함
- Blow에서는 상대적으로 적은 flow step을 가지는 대신 더 많은 block을 사용하도록 구성함
- 특히 12개의 flow를 가지는 8개의 block을 사용 ($8\times 12$ structure)
- 이때 모든 block에 대해 $2\times$ squeeze operation이 있으므로, $2^{8}$ sample의 total squeezing이 필요
- Kernel width 3의 2개의 convolution이 있다고 하면, 해당 $8\times 12$ structure는 12500개 sample의 receptive field를 생성함 (16kHz에서 781ms에 해당)
- 한편으로 논문에서는 더 큰 batch size를 위해 4096 sample의 input frame를 사용함 (16kHz에서 256ms에 해당)
- 기존 WaveNet의 receptive field와 비슷하고 phoneme transition을 accommodate 하기에 충분하기 때문 - 결과적으로 Blow는 context 없이 frame-by-frame으로 동작하게 됨
- Raw audio에서 16kHz의 256 sample은 16ms에 해당하므로, speech construct를 capture 하기에 불충분함
- Forward-Backward Conversion
- Glow-based model에서 manipulation이나 conditioning을 수행하기 위해서는 $\mathbf{z}$ space를 활용해야 하지만, VC task에서는 해당 strategy가 효과적이지 않음
- 따라서 Blow에서는 $\mathbf{z}$에 대한 identity manipulation 대신 $\mathbf{z}$를 identity-agnostic representation으로 고려함
- 이는 $\mathbf{x}$의 real input characteristic을 specifying 하는 supplied condition이 maximum likelihood objective를 고려할 때, $\mathbf{x}$를 $\mathbf{z}$로 변환하는데 유용해야 한다는 것을 의미
- 즉, input condition/characteristic을 알면 해당 condition/characteristic을 통해 hidden similarity를 쉽게 찾을 수 있어야 함 - $\mathbf{x}$에서 $\mathbf{z}$로의 flow에서 multiple level conditioning이 condition-free $\mathbf{z}$ space로 얻어진다면, 다른 condition으로 $\mathbf{z}$를 $\mathbf{x}$로 변환할 때 해당 characteristic도 output $\mathbf{x}$에 imprint 되어야 함
- 이는 $\mathbf{x}$의 real input characteristic을 specifying 하는 supplied condition이 maximum likelihood objective를 고려할 때, $\mathbf{x}$를 $\mathbf{z}$로 변환하는데 유용해야 한다는 것을 의미
- 결과적으로 Blow는 source speaker identifier $y_{S}$를 사용하여 $\mathbf{x}^{(S)}$를 $\mathbf{z}$로 변환하고, target speaker identifier $y_{T}$를 사용하여 $\mathbf{z}$를 converted audio frame $\mathbf{x}^{(T)}$로 변환함
- 따라서 Blow에서는 $\mathbf{z}$에 대한 identity manipulation 대신 $\mathbf{z}$를 identity-agnostic representation으로 고려함
- Hyperconditioning
- Flow-based model에서 coupling network를 도입하면 Jacobian matrix를 계산할 필요가 없고 invertibility constraint가 적용되지 않는다는 장점이 있음
- 특히 affine channel-wise coupling은 coupling network가 대부분의 transformation을 수행하므로 conditioning information으로 boost 될 수 있는 representation power를 가져야 함
- 이때 coupling network를 conditioning 하기 위해 input layer에 representation을 add/concatenate 할 수 있음
- BUT, addition이나 concatenation은 powerful 하지 않으므로, convolution kernel weight로 직접 conditioning을 수행하는 것이 좋음 - 따라서 논문에서는 coupling network의 first layer에서 hyepernetwork와 같이 convolution operator의 weight를 결정하도록 함
- 먼저 1D convolution과 $i$-th convolutional filter에 대한 input activation matrix $\mathbf{H}$가 주어진다고 하면:
(Eq. 2) $\mathbf{h}^{(i)}=\mathbf{W}_{y}^{(i)}*\mathbf{H}+b_{y}^{(i)}$
- $*$ : 1D convolution operation, $\mathbf{W}^{(i)}_{y},b_{y}^{(i)}$ : $y$로 condition 된 $i$-th kernel weight, bias - 그러면 $n$ condition-dependent kernel과 bias에 대한 set $\mathcal{K}_{y}$는:
(Eq. 3) $\mathcal{K}_{y}=\left\{ \left(\mathbf{W}_{y}^{(1)},b_{y}^{(1)}\right)...\left(\mathbf{W}_{y}^{(n)},b_{y}^{(n)} \right)\right\}=g(\mathbf{e}_{y})$
- $g$ : conditioning representation $\mathbf{e}_{y}$를 input으로하는 adapter network로써 condition identifier $y$에 따라 달라짐
- $\mathbf{e}_{y}$ : speaker의 pre-calculated feature representation에서 fix 되거나 initialize 되는 embedding
- 먼저 1D convolution과 $i$-th convolutional filter에 대한 input activation matrix $\mathbf{H}$가 주어진다고 하면:
- Structure-wise Shared Embeddings
- Coupling network 당 하나의 $\mathbf{e}_{y}$를 학습하면 sub-optimal result가 발생할 수 있음
- BUT, 많은 수의 flow step이 주어지더라도 independent conditioning representation은 speaker identity와 같은 condition essence에 focus 할 필요가 없음
- 따라서 model은 condition과 관계없이 negative log-likelihood를 최소화하는 combination을 학습해야 함 - 결과적으로 model의 freedom을 reduce 하기 위해, 논문에서는 해당 reprsentation을 constraint 함
- 이때 StyleGAN과 같이 flow의 모든 step에서 각 coupling network가 share 하는 single learnable embedding $\mathbf{e}_{y}$를 도입
- 이를 통해 model freedom과 parameter 수를 줄여 더 나은 생성이 가능해짐 - 추가적으로 smallest possible adaptor network $g$도 적용
- Dimensionality adjustment 만을 수행하는 bias를 가진 single linear layer
- 이때 StyleGAN과 같이 flow의 모든 step에서 각 coupling network가 share 하는 single learnable embedding $\mathbf{e}_{y}$를 도입
- BUT, 많은 수의 flow step이 주어지더라도 independent conditioning representation은 speaker identity와 같은 condition essence에 focus 할 필요가 없음
- Data Augmentation
- Blow의 training을 위해 silent frame을 discard 한 다음, 나머지 frame에 대해 4가지의 data augmentation을 적용함
- Temporal Jitter
- 각 frame $\mathbf{x}$의 start $j$를 $j'=j+\lfloor U(-\xi,xi)\rceil$로 shift
- $U$ : uniform random number generator, $\xi$ : frame size의 절반
- Random Pre-/De-emphasis Filter
- Speaker identity는 simple filtering으로 변화하지 않음
- 따라서 coefficient $\alpha=U(-0.25, 0.25)$의 emphasis filter를 적용
- Random Amplitude Scaling
- Speaker identity는 scaling을 통해 preserve 되고 model이 $[-1,1]$ 사이의 모든 amplitude를 처리하도록 함
- 이를 위해 $\mathbf{x}'=U(0,1)\cdot \mathbf{x}/\max(|\mathbf{x}|)$를 사용
- Frame Value Random Flip
- Auditory perception은 average pressure level과 관계되어 있으므로, $\mathbf{x}$의 부호를 flip 하여 동일한 perceputal quality를 가지는 다른 input을 얻을 수 있음
- 즉, $\mathbf{x}'=\text{sgn}(U(-1,1))\cdot \mathbf{x}$
- Temporal Jitter
- Implementation Details
- General
- $10^{-4}$의 learning rate, 114 batch size를 사용하여 Adam을 통해 Blow를 training 함
- 구조적으로는 $2\times$ alternate-pattern squeezing operation이 있는 $8\times 12$ structure를 사용
- Coupling network는 channel을 두 부분으로 split 하고, 512 filter와 $[3,1,3]$ kernel width를 가지는 1D convolution을 사용
- Embedding dimension은 128 - Overlap이 없는 16kHz에서 4096의 frame rate로 training 하고, 하나의 data-augmented batch로 ActNorm weight를 initialize 함
- Coupling network는 channel을 두 부분으로 split 하고, 512 filter와 $[3,1,3]$ kernel width를 가지는 1D convolution을 사용
- 추가적으로 Hann window와 50% overlap을 통해 합성을 수행한 다음, $[-1,1]$ range로 utterance를 normalize 함
- Coupling
- Glow와 같이 coupling network의 scaling factor를 constraining 하면 training stability가 향상됨
- 이때 channel-wise concatenation이 있는 affine coupling layer는:
$\mathbf{H}'=\left[\mathbf{H}_{1:c},s'(\mathbf{H}_{1:c})(\mathbf{H}_{c+1:2c}+t(\mathbf{H}_{1:c}))\right]$ - 여기서 $2c$는 total channel 수 이므로:
$s'(\mathbf{H}_{1:c})=\sigma(s(\mathbf{H}_{1:c})+2)+\epsilon$
- $\sigma$ : Sigmoid function, $\epsilon$ : infinite log-determinant를 방지하기 위한 small constant
- Hyperconditioning
- (Eq. 2), (Eq. 3)에 따라 hyperconditioning operation은 large GPU memory footprint와 time-consuming calculation이 요구됨
- 이때 kernel $\mathbf{W}_{y}^{(i)}$의 dimensionality를 restricting 하여 모든 channel이 자체적인 kenel set와 convolve 되도록 하면 GPU footprint를 줄일 수 있음
- 이는 depthwise separable convolution이나 grouped convolution으로 구현됨
4. Experiments
- Settings
- Dataset : VCTK
- Comparisons : Glow, Glow-WaveNet, StarGAN-VC, VQ-VAE
- Results
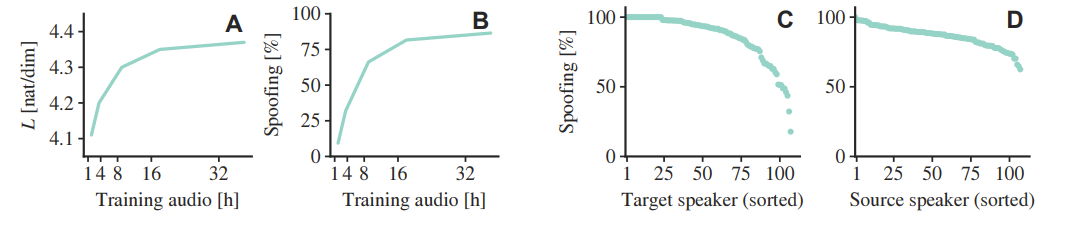
- 전체적으로 Blow가 가장 우수한 성능을 보임

- Ablation study 측면에서 각 configuration을 대체하는 경우 성능 저하가 발생함

- 100 epoch에서 18h의 training set을 활용하는 것과 전체 37h의 training set을 사용하는 것은 거의 동일한 likelihood를 보임
- Normalizing flow가 single input, identifier에 대해서만 likelihood를 최대화하고, target speaker로의 actual conversion을 수행하지 않기 때문
반응형
'Paper > Conversion' 카테고리의 다른 글
댓글