

티스토리 뷰
Paper/Conversion
[Paper 리뷰] DRVC: A Framework of Any-to-Any Voice Conversion with Self-Supervised Learning
feVeRin 2024. 8. 14. 09:39반응형
DRVC: A Framework of Any-to-Any Voice Conversion with Self-Supervised Learning
- Any-to-Any voice conversion은 training data에서 벗어난 source/target speaker에 대해 voice conversion을 수행하는 것을 목표로 함
- BUT, 기존의 disentangle-based model은 speaker/content style information를 얻는 과정에서 untangle overlapping 문제가 발생함 - DRVC (Disentangled Representation Voice Conversion)
- Content encoder, timbre encoder, generator로 구성된 end-to-end self-supervised model을 활용
- 추가적으로 cylce reconstruction loss, same loss로 disentanglement를 restricting 하는 cycle을 도입
- 논문 (ICASSP 2022) : Paper Link
1. Introduction
- Voice Conversion (VC)는 source voice content와 target speaker timbre를 통해 새로운 음성을 생성하는 것을 목표로 함
- 일반적으로 VC system은 $\text{multiple}_{1}\text{-to-}\text{multiple}_{2}$ 방식으로 구성할 수 있음
- $\text{multiple}_{1}, \text{multiple}_{2}$ : 각각 source/target speaker이고, $\text{multiple}_{1}, \text{multiple}_{2} \in \{\text{one},\text{many}, \text{any}\}$
- $\text{many}, \text{any}$ : 각각 training 과정에서 seen/unseen speaker 인지를 의미 - 여기서 $\text{one-to-one}$ VC의 경우 CycleGAN-VC와 같이 fixed source-target speaker pair에 대한 음성만 변환할 수 있으므로 비효율적임
- $\text{any-to-one}, \text{many-to-one}$은 unseen source speaker를 활용할 수 있지만, target speaker가 fix 됨
- 따라서 대부분의 VC model은 disentanglement-based method를 활용하여 uncertain speaker pair를 활용할 수 있는 $\text{many-to-many}, \text{any-to-any}$ model을 구축함
- Disentangle-based model의 경우, speech가 content/speaker style information으로 구성되어 있다고 가정함
- 일반적으로 VC system은 $\text{multiple}_{1}\text{-to-}\text{multiple}_{2}$ 방식으로 구성할 수 있음
-> 그래서 content size를 결정할 필요가 없고, untangle overlapping 문제를 해결할 수 있는 DRVC를 제안
- DRVC
- VC task와 비슷한 Image-to-Image (I2I)에서 Disentangled Representation for Image-to-Image Translation (DRIT)를 활용하면 disentanglement overlapping을 줄이고 효과적인 conversion이 가능
- 해당 DRIT와 같이 input speech 간의 content나 style information이 동일하지 않다고 가정 - 추가적으로 cycle loss와 2개의 discriminator를 사용하여 double exchange를 수행하는 cycle framework를 도입
- VC task와 비슷한 Image-to-Image (I2I)에서 Disentangled Representation for Image-to-Image Translation (DRIT)를 활용하면 disentanglement overlapping을 줄이고 효과적인 conversion이 가능
< Overall of DRVC >
- Disentangled representation에 대한 cycle framework를 통해 overlapping 문제를 해결
- 결과적으로 기존보다 뛰어난 conversion 성능을 달성
2. Method
- Overall Architecture
- DRVC는 content encoder $E_{Con}$, speaker style encoder $E_{S}$, generator $G$, voice discriminator $D_{v}$, domain classifier $D_{S}$로 구성됨
- Target mel-spectrogram $B$가 있을 때,
- Content encoder $E_{Con}$은 $E_{Con}:B\rightarrow C_{B}$와 같이 mel-spectrogram을 content representation으로 mapping 함
- Speaker encoder $E_{S}$는 $E_{S}:B\rightarrow S_{B}$와 같이 mel-spectrogram을 timbre representation으로 mapping 함
- 구조적으로 content encoder는 LSTM layer와 3개의 CNN layer로 구성되고, style encoder는 AdaIN-VC의 speaker encoder를 사용
- Voice discriminator $D_{v}$는 input voice가 real/fake인지 distinguish 하고, Domain classifier $D_{S}$는 embedding speaker style information이 어떤 speaker에 속하는지를 identify 함
- 구조적으로 voice discriminator, domain classifier는 2개의 hidden layer를 가지는 multi-layer perceptron과 같음 - 최종적으로 generator $G$는 $G:[C_{A},S_{B}]\rightarrow \hat{B}$와 같이 content, timbre vector에 따라 converted speech를 합성함
- Target mel-spectrogram $B$가 있을 때,

- Disentangle Content and Style Representations
- 논문에서는 2개의 input voice $a,b$가 2명의 speaker $A, B$에 의해 spoken 된다고 가정함
- 여기서 speaker $A$를 content를 제공하는 source speaker, speaker $B$를 style을 제공하는 target speaker라고 하자
- 그러면 DRVC는 input mel-spectrogram을 specific content space $C_{A}, C_{B}$와 specific style space $S_{A}, S_{B}$에 embed 함 - 즉, content encoder는 input speech의 content information을 embed 하고 timbre encoder는 speech를 specific style information에 mapping 함:
(Eq. 1) $\{a_{C},a_{S}\}=\{E_{Con}(a),E_{S}(a)\},\,\,a_{C}\in C_{A},a_{S}\in S_{A}$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, \{b_{C},b_{S}\}=\{E_{Con}(b),E_{S}(b)\},\,\,b_{C}\in C_{B},b_{S}\in S_{B}$
- $a,b$ : 각각 input source/target mel-spectrogram - 여기서 논문은 representation disentanglement를 달성하고 overlapping 문제를 해결하기 위해, 다음의 2가지 strategy를 도입
- Same Embedding Loss
- Content와 speaker style information은 embedding process나 input speech에 관계없이 unalter 되어야 함:
(Eq. 2) $\mathcal{L}_{same}^{C_{n}}=\mathbb{E}[|a_{C}-\tilde{a_{C}}|],\,\, \mathcal{L}_{same}^{S_{n}}=\mathbb{E}[|a_{S}-\tilde{a_{S}}|]$
- $\mathcal{L}_{same}^{C_{n}},\mathcal{L}_{same}^{S_{n}}$ : 각각 content/style information에 대한 same loss, $n\in\{a,b\}$ : 각각 source/target domain, $\tilde{a_{C}},\tilde{a_{S}}$ : second conversion 이후의 content/style information
- Content same loss의 합은 $\mathcal{L}_{same}^{C}=\sum_{n}^{2}\mathcal{L}_{same}^{C_{n}}$, Style same loss의 합은 $\mathcal{L}_{same}^{S}=\sum_{n}^{2}\mathcal{L}_{same}^{S_{n}}$
- 결과적으로 total same loss는, $\mathcal{L}_{same} = \mathcal{L}_{same}^{C}+\mathcal{L}_{same}^{S}$ - Domain Discriminator $D_{v}$
- Input style hidden vector가 어떤 speaker에 속하는지를 identify 하는 역할:
(Eq. 3) $p_{a}=D_{v}(a_{S}),\,\,p_{b}=D_{v}(b_{S})$
(Eq. 4) $\mathcal{L}_{domain}=-\frac{1}{2}\left(\sum_{i} y_{a}(i)\log (p_{a}(i))+ \sum_{i}y_{b}(i)\log (p_{b}(i))\right)$
- $y$ : real traget, $p$ : predicted target
- Same Embedding Loss
- 여기서 speaker $A$를 content를 제공하는 source speaker, speaker $B$를 style을 제공하는 target speaker라고 하자
- Cycle Loss
- DRVC는 source voice content $a_{C}$와 target voice timbre $b_{S}$를 결합하여 voice conversion을 수행함
- 이때 CycleGAN-VC와 유사하게 generator $G$를 학습하도록, $B\rightarrow \tilde{A}\rightarrow \hat{B}$와 같은 cycle process를 도입함
- 이때 timbre, content information을 double exchange 하고, cross-cycle consistency를 loss function $\mathcal{L}_{cycle}$로 사용 - First Conversion
- Non-corresponding voice pair에 대한 mel-spectrogram $a,b$가 주어지면, content information $\{a_{C},b_{C}\}$와 style information $\{a_{S},b_{S}\$}를 얻을 수 있음
- 이때 style information $\{a_{S},b_{S}\}$를 exchange 하여 $\{\tilde{a},\tilde{b}\}$를 생성함:
(Eq. 5) $\tilde{b}=G(b_{C},a_{S}),\,\, \tilde{a}=G(a_{C},b_{S})$
- $\tilde{a}\in\text{Target Domain},\tilde{b}\in\text{Source Domain}$
- Second Conversion
- $\tilde{b},\tilde{a}$를 $\{\tilde{b_{C}},\tilde{b_{S}}\}$와 $\{\tilde{a_{C}},\tilde{a_{S}}\}$로 encoding 하기 위해, style information $\{\tilde{a_{S}},\tilde{b_{S}}\}$를 다시 exchange 함:
(Eq. 6) $\hat{a}=G(\tilde{a_{C}},\tilde{b_{S}}), \,\, \hat{b}=G(\tilde{b_{C}},\tilde{a_{S}})$ - 해당 conversion 이후 output $\hat{a},\hat{b}$는 input $a,b$에 대한 reconstruction이 되어야 함
- 즉, input/output 간의 relation은 $\hat{a}=a, \hat{b}=b$가 되어야 함
- $\tilde{b},\tilde{a}$를 $\{\tilde{b_{C}},\tilde{b_{S}}\}$와 $\{\tilde{a_{C}},\tilde{a_{S}}\}$로 encoding 하기 위해, style information $\{\tilde{a_{S}},\tilde{b_{S}}\}$를 다시 exchange 함:
- 이때 앞선 constraint를 적용하기 위해 cross-cycle consistency loss $\mathcal{L}_{cycle}$를 도입:
(Eq. 7) $\mathcal{L}_{cycle}=\mathbb{E}_{a,b}\left[ ||G(E_{Con}(\tilde{a}), E_{S}(\tilde{b}))-a ||_{1}+||G(E_{Con}(\tilde{b}),E_{S}(\tilde{a}) )-b ||_{1}\right]$ - 추가적으로 generator의 over-fitting을 방지하기 위해 identity loss를 적용:
(Eq. 8) $\mathcal{L}_{id}=\mathbb{E}_{a,b}\left[ || G(E_{Con}(a),E_{S}(a) )-a||_{1}+||G(E_{Con}(b),E_{S}(b))-b ||_{1}\right]$
- Identity loss는 generator에 original speech content/style information이 input 되었을 때, original speech를 합성하는 것을 restrict 함
- 이때 CycleGAN-VC와 유사하게 generator $G$를 학습하도록, $B\rightarrow \tilde{A}\rightarrow \hat{B}$와 같은 cycle process를 도입함
- Adversarial Loss
- 논문은 합성 결과의 naturalness를 향상하기 위해 adversarial loss $\mathcal{L}_{adv}$를 추가함
- 구체적으로, real voice $\{a,b\}$와 synthesis speech $\{\tilde{a},\tilde{b}\}$를 input 하여 voice discriminator를 training 함:
(Eq. 9) $F\left( \frac{\partial \mathcal{L}_{c}}{\partial \theta_{G}}\right)=-\lambda\left( \frac{\partial \mathcal{L}_{R}}{\partial\theta_{G}}+\frac{\partial \mathcal{L}_{F}}{\partial \theta_{G}}\right)$
- $F(\cdot)$ : gradient reversal layer, $\lambda$ : weight adjustment parameter, $\theta_{G}$ : generator parameter
- $\mathcal{L}_{R}, \mathcal{L}_{F}$ : 각각 real/fake classification loss ($R$ : real, $F$ : fake) - 그러면 adversarial loss $\mathcal{L}_{adv}$는:
(Eq. 10) $\mathcal{L}_{adv}=\mathbb{E}_{R\sim p(a)}[\log D_{S}(a)]+\mathbb{E}_{F\sim p(\tilde{a})}[\log D_{S}(\tilde{a})]+\mathbb{E}_{R\sim p(b)}[\log D_{S}(b)]+\mathbb{E}_{F\sim p(\tilde{b})}[\log D_{S}(\tilde{b})]$
- Discriminator는 real $A$ speech $a$, real $B$ speech $b$, fake $A$ speech $\tilde{a}$, fake $B$ speech $\tilde{b}$를 통해 train 됨 - 결과적으로 DRVC의 total objective는:
(Eq. 11) $\mathcal{L}_{all}=\lambda_{cycle}\mathcal{L}_{cycle}+ \lambda_{id}\mathcal{L}_{id}+\lambda_{S}\mathcal{L}_{adv}+\lambda_{domain}\mathcal{L}_{domain}+\lambda_{same}\mathcal{L}_{same}$
- $\lambda_{cycle}=5,\lambda_{id}=2,\lambda_{S}=1,\lambda_{domain}=10,\lambda_{same}=50$
- 구체적으로, real voice $\{a,b\}$와 synthesis speech $\{\tilde{a},\tilde{b}\}$를 input 하여 voice discriminator를 training 함:
3. Experiments
- Settings
- Results
- 전체적으로 DRVC가 가장 우수한 MCD, MOS 성능을 달성함

- Similarity 측면에서도 DRVC가 가장 우수함
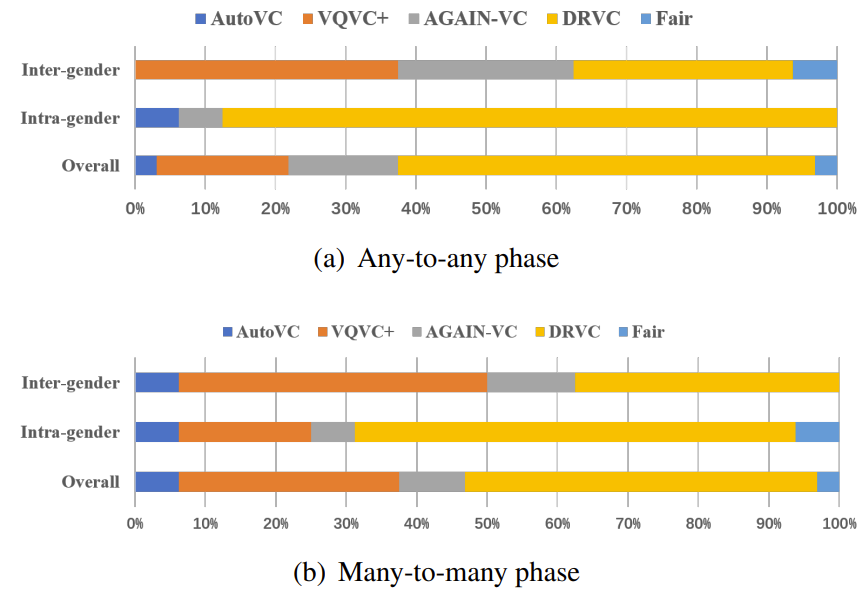
- Ablation Study 측면에서 각 loss를 제거하는 경우 성능 저하가 발생함

반응형
'Paper > Conversion' 카테고리의 다른 글
댓글