

티스토리 뷰
Paper/SVS
[Paper 리뷰] VISinger2: High-Fidelity End-to-End Singing Voice Synthesis Enhanced by Digital Signal Processing Synthesizer
feVeRin 2024. 7. 24. 09:17반응형
VISinger2: High-Fidelity End-to-End Singing Voice Synthesis Enhanced by Digital Signal Processing Synthesizer
- Singing Voice Synthesis에서 VISinger는 우수한 합성 성능을 달성했지만 다음의 한계점이 존재함
- Text-to-Phase problem, Glitches, Low sampling rate - VISinger2
- Digital signal processing synthesizer를 통해 VISinger의 latent representation $z$로부터 periodic/aperiodic signal을 생성
- Phase information 없이 latent representation을 추출하도록 posterior encoder를 supervise 하고, text-to-phase mapping을 방지하도록 prior encoder를 모델링함 - Glitch artifact를 방지하기 위해 digital signal processing synthesizer의 waveform을 condition으로 HiFi-GAN을 수정
- Digital signal processing synthesizer를 통해 VISinger의 latent representation $z$로부터 periodic/aperiodic signal을 생성
- 논문 (INTERSPEECH 2023) : Paper Link
1. Introduction
- Singing Voice Synthesis (SVS)는 주어진 music score와 lyrics를 기반으로 singing voice를 합성하는 것을 목표로 함
- Text-to-Speech (TTS)와 비슷하게 대부분의 SVS system은 two-stage 방식을 따름
- Acoustic model을 통해 music score, lyrics로부터 low-dimensional spectral representation (mel-spectrogram)을 생성하고, vocoder를 통해 해당 representation을 waveform으로 변환 - BUT, 이러한 two-stage model에서 human-crafted intermediate representation인 mel-spectrogram은 expressiveness를 저해할 수 있음
- 한편으로 two-stage 방식의 한계를 극복하기 위해 VISinger는 VITS를 기반으로 end-to-end SVS system을 구축함
- 여기서 posterior encoder는 linear spectrum에서 latent representation $z$를 추출하고, decoder는 $z$를 waveform으로 restore 하고, prior encoder는 text에 따라 $z$에 prior constraint를 제공함
- 추가적으로 $F0$ guidance에 따라 $z$에 accurate frame-level prior constraint를 제공하고 duration predictor를 통한 prior information을 반영
- 결과적으로 end-to-end 기반의 VISinger는 기존 two-stage 방식보다 뛰어난 SVS 성능을 달성했지만, 다음의 몇가지 한계점이 여전히 남아있음
- Quality artifact
- Spectral discontinuity나 mispronunciation 같은 audible glitch가 종종 발생함
- 이는 waveform modeling 시에 posterior encoder에 의해 추출된 latent representation $z$가 decoder에서 재전달된 gradient로 인해 phase information을 가지게 되기 때문 - Low sampling rate
- VISinger의 singing voice는 24kHz이므로 44.1kHz 이상의 high-fidelity desire를 만족하지 못함
- 이는 VISinger에서 채택된 HiFi-GAN architecture가 SVS task에 적합하지 않기 때문
- Quality artifact
- Text-to-Speech (TTS)와 비슷하게 대부분의 SVS system은 two-stage 방식을 따름
-> 그래서 44.1kHz의 high-fidelity SVS를 위해 VISinger를 개선한 VISinger2를 제안
- VISinger2
- Differential Digital Signal Processing (DDSP)를 기반으로 DSP synthesizer를 VISinger에 결합
- 해당 DSP synthesizer는 latent representation $z$로부터 periodic/aperiodic signal을 각각 생성하는 harmonic synthesizer와 noise synthesizer로 구성됨 - Periodic/aperiodic signal을 HiFi-GAN에 대한 conditional input으로 concatentate 하고, 두 signal의 합은 loss function을 계산하기 위한 waveform을 생성하는데 사용됨
- 이때 두 synthesizer는 signal 생성을 위한 input으로 amplitude information만 사용하므로 $z$의 phase component를 fully compressing 하여 text-to-phase 문제를 방지 가능
- Periodic/aperiodic signal composition을 통해 HiFi-GAN에 대한 strong condition을 제공함으로써 higher sampling rate에서도 효과적인 모델링이 가능
- Differential Digital Signal Processing (DDSP)를 기반으로 DSP synthesizer를 VISinger에 결합
< Overall of VISinger2 >
- DSP synthesizer를 통해 periodic/aperiodic signal을 반영하는 fully end-to-end SVS model
- 결과적으로 기존 방식과 비교하여 뛰어난 합성 품질을 달성
2. Method
- VISinger2는 conditional Variational AutoEncoder (cVAE)를 기반으로함
- 이때 VITS와 같이 posterior encoder, prior encoder, decoder로 구성됨
- Posterior encoder는 spectral feature에서 latent representation $z$를 추출하고, decoder는 $z$에서 waveform $y$를 생성하고, prior conditional encoder는 $z$의 추출을 constrain 함
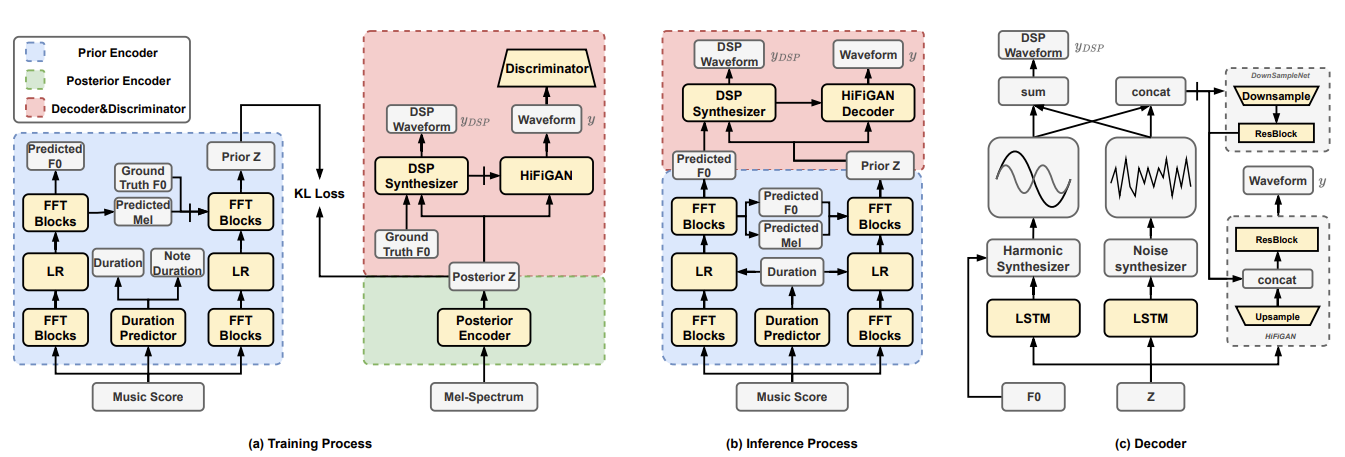
- Posterior Encoder
- Posterior encoder는 mel-spectrum에서 latent representation $z$를 추출하는 multi-layer 1D convolution으로 구성됨
- 마지막 layer는 posterior distribution의 평균, 분산을 생성하고 posterior $z$를 얻기 위해 resampling method가 적용됨
- Decoder
- Decoder는 latent representation $z$로부터 waveform을 생성하고, text-to-phase 문제를 방지하기 위해 DSP synthesizer를 decoder에 도입함
- 구체적으로 VISinger2는 harmonic synthesizer와 noise synthesizer를 사용하여 posterior $z$로부터 waveform의 periodic/aperiodic part를 각각 생성함
- 이후 생성된 waveform은 HiFi-GAN input에 대한 auxiliary condition으로 사용되어 modeling capability를 향상하고 glitch를 완화
- 특히 해당 synthesizer의 input에는 amplitude information만 포함되므로, posterior $z$는 phase information이 포함되지 않아 text-to-phase 문제를 방지 가능
- Harmonic Synthesizer
- DDSP의 harmonic oscillator와 동일한 harmonic component를 생성하기 위해 harmonic synthesizer를 도입함
- Harmonic synthesizer는 sine signal을 사용하여 single sound source audio의 각 fromant에 대한 waveform을 simulation 함
- 이때 harmonic synthesizer에 의해 생성된 $k$-th sinusoidal component signal $y_{k}$는:
(Eq. 1) $y_{k}(n)=H_{k}(n)\sin(\phi_{k}(n))$
- $n$ : sample sequence의 time step, $H_{k}$ : $k$-th sinusoidal component의 time-varying amplitude - Phase $\phi_{k}(n)$은 sample sequence를 integrating 하여 얻어짐:
(Eq. 2) $\phi_{k}(n)=2\pi \sum_{m=0}^{n}\frac{f_{k}(m)}{Sr}+\phi_{0,k}$
- $f_{k}$ : $k$-th sinusoidal component의 frequency, $Sr$ : sampling rate, $\phi_{0,k}$ : initial phase
- 즉, fundamental frequency $f_{k}$에 대한 accumulation을 통해 sine signal $y_{k}$의 phase를 얻을 수 있음
- 이때 harmonic synthesizer에 의해 생성된 $k$-th sinusoidal component signal $y_{k}$는:
- 한편으로 frequency $f_{k}$는 $f_{k}(n)=kf_{0}(n)$으로 계산됨
- $f_{0}$ : fundamental frequency로 Harvest algorithm을 통해 추출됨
- Time-varying $f_{k}$와 $H_{k}$는 frame-level feature로 interpolate 됨
- Noise Synthesizer
- Noise synthesizer에서는 iSTFT를 사용하여 DDSP의 filtered noise와 유사한 stochastic component를 생성함
- 특히 aperiodic component는 noise와 비슷하지만, energy distribution은 서로 다른 frequency band에 대해 uneven 함 - 이때 생성된 stochastic component signal $y_{noise}$는:
(Eq. 3) $y_{noise}=\text{iSTFT}(N,P)$
- $P$ : iSTFT의 phase spectrogram으로써, domain $[-\pi, \pi]$의 uniform noise
- $N$ : network로 예측된 amplitude spectrogram
- Noise synthesizer에서는 iSTFT를 사용하여 DDSP의 filtered noise와 유사한 stochastic component를 생성함
- Loss Function of Decoder
- DSP synthesizer에서 생성된 DSP waveform에는 harmonic, stochastic component가 모두 포함되어 있음
- 이때 complete DSP waveform $y_{DSP}$와 DSP synthesizer의 loss $\mathcal{L}_{DSP}$는:
(Eq. 4) $y_{DSP}=\sum_{k=0}^{K}y_{k}+y_{noise}$
(Eq. 5) $\mathcal{L}_{DSP}=\lambda_{DSP}|| \text{Mel}(y_{DSP})-\text{Mel}(y)||_{1}$
- $K$ : sinusoidal component의 수, $\text{Mel}$ : waveform에서 mel-spectrogram을 추출하는 operation - 논문은 downsampling network를 사용하여 DSP waveform을 frame-level feature로 downsampling 함
- 이를 통해 HiFi-GAN은 downsampling network에서 생성된 posterior $z$와 intermediate feature를 기반으로 final waveform $\hat{y}$를 생성 - 결과적으로 generator $G$에 대한 GAN loss는:
(Eq. 6) $\mathcal{L}_{G}=\mathcal{L}_{adv}(G)+\lambda_{fm}\mathcal{L}_{fm}+\lambda_{mel}\mathcal{L}_{mel}$
- $\mathcal{L}_{adv}$ : adversarial loss, $\mathcal{L}_{fm}$ : feature matching loss, $\mathcal{L}_{mel}$ : mel-spectrogram loss
- Discriminator
- VISinger2는 다음 3가지의 discriminator를 채택
- UnivNet의 Multi-Resolution Spectrogram Discriminator, HiFi-GAN의 Multi-Period Discriminator, Multi-Scale Discriminator
- Prior Encoder
- Prior encoder는 cVAE에 대한 prior constraint를 제공하기 위해 music score를 input으로 사용함
- 한편으로 posterior $z$는 decoder에서 $H, N$을 예측하는데 사용됨
- $H$ : sinusoidal formant의 amplitude, $N$ : aperiodic component의 amplitude spectrum
- $H, N$ 모두 amplitude information만 가지므로 posterior $z$에는 phase information이 포함되지 않음 - 따라서 prior encoder는 posterior $z$를 예측할 때 text-to-phase mapping을 모델링할 필요가 없음
- 구조적으로 prior encoder는 VISinger와 동일한 structure를 따름
- 이때 flow module은 많은 parameter를 요구하므로 VISinger2에서는 flow를 사용하지 않고 prior와 posterior 간의 KL-divergence $\mathcal{L}_{kl}$을 계산함
- 한편으로 frame-level prior network를 guide 하기 위해, fundamental frequency와 mel-spectrum을 예측하는 FastSpeech를 활용하여 auxiliary feature loss를 정의함:
(Eq. 7) $\mathcal{L}_{af}=|| LF0-\widehat{LF0}||_{2}+|| Mel-\widehat{Mel}||_{1}$
- $\widehat{LF0}$ : predicted $\log\text{-}F0$, $\widehat{Mel}$ : predicted mel-spectrogram - Training/inference 과정에서 예측된 mel-spectrogram을 frame-level prior network의 auxiliary feature로 사용하므로 mismatch 문제를 완화할 수 있음
- 특히 frame-level prior network는 text-to-mapping 문제를 완화하기 위해 auxiliary mel-spectrum guide를 활용하여 prior를 예측함
- Harmonic synthesizer는 ground-truth fundamental frequency로 training 되고, 추론 시에는 periodic signal generation을 guide 하기 위해 예측된 fundamental frequency를 input으로 사용함
- 추가적으로 music score에서 phoneme duration과 note duration을 예측하기 위해 duration loss를 채택함:
(Eq. 8) $\mathcal{L}_{dur}=|| d_{phone}-\widehat{d_{phone}}||_{2}+|| d_{note}-\widehat{d_{note}}||_{2}$
- $d_{phone}$ : ground-truth phoneme duration, $\widehat{d_{phone}}$ : predicted phoneme duration
- $d_{note}$ : ground-truth note duration, $\widehat{d_{note}}$ : predicted note duration
- 한편으로 posterior $z$는 decoder에서 $H, N$을 예측하는데 사용됨
- Final Loss
- VISinger2의 final loss는:
(Eq. 9) $\mathcal{L}(G)=\mathcal{L}_{G}+\mathcal{L}_{kl}+\mathcal{L}_{DSP}+\mathcal{L}_{dur}+\mathcal{L}_{af}$
(Eq. 10) $\mathcal{L}(D)=\mathcal{L}_{adv}(D)$
- $\mathcal{L}_{G}$ : generator $G$의 GAN loss, $\mathcal{L}_{kl}$ : prior, posterior 간의 KL-divergence
- $\mathcal{L}_{af}$ : auxiliary feature loss, $\mathcal{L}_{adv}(D)$ : discriminator $D$의 GAN loss
3. Experiments
- Settings
- Dataset : OpenCPop
- Comparisons : CpopSing, VISinger, RefineSinger (FastSpeech + RefineGAN)
- Results
- 전체적인 성능 측면에서 VISinger2가 가장 우수한 성능을 달성함

- 합성된 mel-spectrogram을 확인해 보면, periodic/aperiodic component는 각각 harmonic synthesizer와 noise synthesizer로 생성됨
- 특히 final waveform은 conditional input인 DSP waveform에 의해 guide 됨

- Ablation study 측면에서 각 component를 제거하는 경우 성능 저하가 나타남

반응형
'Paper > SVS' 카테고리의 다른 글
댓글