

티스토리 뷰
반응형
DDSP: Differentiable Digital Signal Processing
- 대부분의 audio 생성 모델은 time 또는 frequency domain 중 하나에서 sampling을 생성함
- Signal을 표현하는 데는 적합하지만 sound가 생성되고 인식되는 방식에 대한 knowledge를 활용하지 않음 - Vocoder의 경우 domain knowledge를 성공적으로 반영할 수 있지만 auto-differentiable-based 방식과는 통합하기 어려움
- Differentiable Digital Signal Processing (DDSP)
- 기존의 signal processing 요소를 deep learning 방식과 통합
- Neural network의 expressive power를 잃지 않으면서 강력한 inductive bias를 활용 가능
- Interpretable module을 결합하여 pitch/loudness의 제어, extrapolation, blind dereverberation, transfer 등이 가능
- 논문 (ICLR 2020) : Paper Link
1. Introduction
- Neural network는 asymptotic limit에 대한 universal function approximator로 볼 수 있음
- 하지만 nerual network는 convolution, recurrence, self-attention과 같은 structural prior에 의존적임
- 이러한 architectrue 제약은 data domain 범위 내에서의 일반화를 촉진함
- 결과적으로 neural network는 scale에 대한 structural prior에 의존적이고 differentiable 한 function으로 제한됨 - 실제로 대부분의 object는 periodically vibrate 하는 경향이 있고, 이를 인식하는 인간의 청력은 neural network의 동작과는 다름
- 특히 인간의 청력은 phase-coherent oscillation에 매우 민감하기 때문에, basilar membrance의 resonant property와 auditory cortex의 tonotopic mapping을 통해 audio를 spectrotemporal response로 decompose 하는 방식으로 동작함
- BUT, neural network는 audio 합성을 위해 위와 같은 peridoic structure를 활용하지 않음
- 하지만 nerual network는 convolution, recurrence, self-attention과 같은 structural prior에 의존적임
- Challenges of Neural Audio Synthesis
- 아래 그림과 같이 대부분의 neural audio synthesis 모델은 time-domain에서 직접 waveform을 생성하거나 frequency-domain의 Fourier coefficient로부터 waveform을 생성함
- 이러한 방식은 일반적으로 waveform을 나타내는 방식이지만, bias에서 자유롭지 못함
- Oscillation이 아닌 aligned wave packet을 사용하기 때문 - For example,
- SING, WaveGAN과 같은 stride convolution 모델은 frame이 overlap된 waveform을 생성함
- BUT, audio는 고정된 frame hop size이 아닌 서로 다른 period를 가지는 다양한 frequency에서 oscillate 됨
- 결과적으로 이를 위해 모델은 서로 다른 frame 간의 waveform을 align 하고 가능한 모든 phase variation을 cover 할 수 있는 filter를 학습해야 함 - Tacotron, GANSynth와 같은 Fourier-based 모델도 마찬가지로 STFT의 phase-alignment 문제를 겪음
- Fourier-based frequency가 audio와 완벽하게 일치하지 않을 때, spectral leakage 문제가 발생
- 이때 single sinusoid를 나타내기 위해 여러 neighboring frequency와 phase의 sinusoid들을 결합해야 함 - WaveNet, WaveRNN과 같은 autoregressive 모델은 time에 따라 single sample을 생성하는 방식을 활용
- Wave packet 생성에 대한 bias 제약을 받지 않고 arbitrary waveform을 합성할 수 있지만 oscillation에 대한 bias를 활용하지 않기 때문에 더 크고 많은 data를 필요로 함
- 특히 학습 중에 teacher-forcing 방식을 사용하면 exposure bias가 발생하여 feedback error가 심화됨
- 추가적으로 spectral feature, pretrained model, discriminator에 대한 loss가 서로 incompatible 하므로 비효율성이 증가함
- SING, WaveGAN과 같은 stride convolution 모델은 frame이 overlap된 waveform을 생성함

- Oscillator Models
- Waveform이나 Fourier coefficient를 예측하는 대신 oscillator를 사용하여 audio를 생성할 수 있음
- Expert knowledge와 hand-tuned heuristic을 반영하여 interpretable 한 합성 parameter를 추출할 수 있음 - 이때 analysis parameter는 hand-tuning이 필요하므로 합성 과정에서 neural network를 통한 gradient flow가 불가능함
- 결과적으로 backpropagation이 불가능하여 network의 학습이 어려워지고 audio expressivity가 제한됨
- Waveform이나 Fourier coefficient를 예측하는 대신 oscillator를 사용하여 audio를 생성할 수 있음
-> 그래서 fully differentiable 한 audio 합성을 가능하게 하는 Differentiable Digital Signal Processing (DDSP)를 제안
- Differentiable Digital Signal Processing (DDSP)
- DDSP는 audio 합성 모델에 있어 아래와 같은 interpretability와 modularity를 제공 가능:
- 합성 과정에서의 pitch와 loudness에 대한 독립적인 제어
- Unseen pitch에 대한 realistic extrapolation
- Room acoustics의 separate modelling을 통한 blind dereverberation
- 새로운 environment로 추출된 room acoustics의 transfer
- Disparate source 간의 timbre transfer (Singing voice to Violin)
- 비슷한 neural synthesizer 보다 더 작은 network size
- DDSP는 audio 합성 모델에 있어 아래와 같은 interpretability와 modularity를 제공 가능:
< Overall of DDSP >
- DDSP의 fully differentiable synthesizer의 구현을 통한 audio 합성 제약의 극복
- Oscillator 사용에 inductive bias를 활용하면서 neural network의 expressive power를 유지
- DDSP component 사용을 통해 autoregressive/adversarial loss 없이 high-fidelity audio를 합성 가능
2. DDSP Components
- 많은 Digital Signal Processing (DSP) operation은 automatic differentiation software의 function으로써 표현될 수 있음
- DSP의 핵심 component를 feedforward function으로 구현하여 GPU/TPU 등에서 활용가능하도록 함
- 이를 위한 component로써 oscillator, envelope, filter (Linear-Time-Varying Finite-Impulse-Response, LTV-FIR)를 포함
- Spectral Modelling Synthesis
- 논문에서는 DDSP 모델을 위해 Spectral Modelling Synthesis (SMS)의 differentialbe version을 구현
- Additive synthesizer와 subtractive synthesizer를 결합하여 audio를 생성하는 방식
- SMS는 parameteric 하면서도 expressivity가 뛰어나다는 이점이 있음
- Spectral morphing, time stretching, pitch shifting, source separation, audio codec 등에 널리 사용됨 - 이때 SMS의 뛰어난 expressivity는 많은 parameter를 가지고 있기 때문임
- 따라서 SMS의 모든 parameter를 수동으로 지정하는 것은 불가능하므로 neural network를 활용하여 제어할 수 있음 - 이를 위해 monophonic source 만을 고려하여 sinusoid를 fundamental frequency의 integer 배수로 제한하는 Harmonic plus Noise 모델을 사용
- Harmonic Oscillator / Additive Synthesizer
- DDSP는 sinusoidal oscillator를 핵심으로 함
- 먼저, discrete time step $n$에 걸쳐 signal $x(n)$을 output 하는 oscillator bank는:
(Eq. 1) $x(n) = \sum_{k=1}^{K} A_{k}(n) \sin(\phi_{k}(n))$
- $A_{k}(n)$ : $k$-th sinusoidal component의 time-varying amplitude
- $\phi_{k}(n)$ : instantaneous phase - 이때 phase $\phi_{k}(n)$은 instantaneous frequency $f_{k}(n)$를 적분함으로써 얻을 수 있음:
(Eq. 2) $\phi_{k}(n) = 2\pi \sum_{m=0}^{n}f_{k}(m)+\phi_{0,k}$
- $\phi_{0,k}$ : randomized, fixed, learned 될 수 있는 initial phase
- 먼저, discrete time step $n$에 걸쳐 signal $x(n)$을 output 하는 oscillator bank는:
- Harmonic oscillator는,
- 모든 sinusoidal frequency를 fundamental frequency $f_{0}(n)$의 interger 배수로 표현 가능 ($f_{k}(n) = kf_{0}(n)$)
- 따라서 harmonic oscillator의 output은 time-varying frequency $f_{0}(n)$과 harmonic amplitude $A_{k}(n)$에 의해 parameterize 됨
- 이때, interpretability를 위해 harmonic amplitude를 factorize 하여, loudness를 제어하는 global amplitude $A(n)$과 spectral variation을 결정하는 harmonics $c(n)$으로 변환
(Eq. 3) $A_{k}(n) = A(n)c_{k}(n)$
- $\sum_{k=0}^{K} c_{k}(n) = 1, c_{k}(n) \geq 0$ - 추가적으로 modified sigmoid nonlinearity를 사용하여 amplitude와 harmonic 분포의 component를 모두 양수로 제한
- 결과적으로 additive synthesizer는,
- Fundamental frequency의 harmonic (interger) 배수에서 sinusoids의 합으로 audio를 생성하고 이후 neural network는 time-varying parameter (fundamental frequency, amplitude, harmonic distribution)를 출력함
- 아래 그림의 linear-frequency log-magnitude spectrogram은:
- harmonics가 처음에는 fundamental frequency의 contour를 따르고,
- loudness를 제어하는 amplitude envelope을 거쳐,
- spectral variation을 결정하는 harmonics 간의 normalized distribution을 따르는 것을 보여줌

- Envelopes
- 앞선 oscillator formulation은 audio sampling rate에서 time-varying amplitude와 frequency가 필요하지만, nerual network는 더 느린 frame rate에서 동작 가능함
- Instantaneous frequency upsampling의 경우, bilinear interpolation이 적절함
- 이때 additive synthesizer의 amplitude, harmonics 분포에서 artifcat를 방지하기 위해서는 smoothing이 필요
- 이를 위해 각 frame의 중앙에 overlapping Hamming window를 추가하고,
- Amplitude에 따라 scale 하여 smoothed amplitude envelope를 얻음
- Filter Design: Frequency Sampling Method
- Linear filter는 DSP 기술의 기반이 됨
- Standard convolution layer는 Linear-Time-Invariant Finite-Impulse-Response (LTI-FIR) filter와 동일함
- DDSP는 interpretability를 보장하고 phase distorion을 방지하기 위해, frequency sampling을 사용하여 network output을 linear-phase filter의 impulse response로 변환
- 이를 위해 모든 output frame에 대해 FIR filter의 frequency-domain transfer function을 예측하는 neural network를 설계
- 이때 neural network는, output의 $l$-th frame에 대해 vector $\mathbf{H}_{l}$을 출력 ($h_{1} = IDFT(\mathbf{H}_{l})$)
- $\mathbf{H}_{l}$을 해당 FIR filter의 frequency-domain transfer function으로 볼 수 있음
- 따라서 이에 기반하여 time-varying FIR filter를 구현 - Time-varying FIR filter를 input에 적용하기 위해 audio를 non-overlapping frame $x_{l}$로 나누어 impulse response $h_{l}$과 match시킴
- 이후 Fourier-domain에서 frame multiplication을 통해 frame-wise convolution을 수행하면:
$\mathbf{Y}_{l} = \mathbf{H}_{l}\mathbf{X}_{l}$
- $\mathbf{X}_{l} = DFT(x_{l})$, $\mathbf{Y}_{l} = DFT(y_{1})$ - 그리고 frame-wise filtered audio $y_{l} = IDFT(\mathbf{Y}_{l})$을 recover 한 다음, original input audio과 동일한 hop size, rectangular window를 사용하여 resulting frame을 overlap-add
- Hop size는 각 conditioning frame에 대해 audio를 동일한 간격으로 나누어서 제공됨
- i.g.) 64000 sample과 250 frame이면 256 hop size
- 이때 neural network는, output의 $l$-th frame에 대해 vector $\mathbf{H}_{l}$을 출력 ($h_{1} = IDFT(\mathbf{H}_{l})$)
- 실적용에서는 neural network ouptut을 $\mathbf{H}_{l}$로 직접 사용하지 않음
- 대신 $\mathbf{H}_{l}$을 계산하기 위해 network ouput에 window function $\mathbf{W}$를 적용
- Window size와 shape는 filter의 time-frequency resolution trade-off를 제어하기 위해 독립적으로 결정될 수 있음
- 논문에서는 Hann window size를 257로 사용
- 이때 Window를 사용하지 않으면 resolution은 적합하지 않은 rectangular window를 기본적으로 적용함 - Window를 적용하기 전에 IR을 zero-phase (symmetric) form으로 shift 하고 filter를 적용하기 전에 casual form으로 revert
- 대신 $\mathbf{H}_{l}$을 계산하기 위해 network ouput에 window function $\mathbf{W}$를 적용
- Filtered Noise / Subtractive Synthesizer
- Natural sound에는 harmonic, stochastic component가 모두 포함되어 있음
- Harmonic plus Noise 모델은 additive synthesizer의 output을 filtered noise stream과 결합하여 이를 capture 함
- 이때 uniform noise $\mathbf{Y}_{l} = \mathbf{H}_{l}\mathbf{N}_{l}$의 stream 위에 LTV-FIR filter를 적용함으로써 differentiable filtered noise synthesizer를 구현할 수 있음
- $\mathbf{N}_{l}$ : domain $[-1,1]$ 내 uniform noise의 IDFT
- Reverb: Long Impulse Responses
- Room reverbation (Reverb)는 realistic audio를 위한 필수적인 특성으로, 일반적으로 neural synthesis algorithm에 의해 implicitly modelling 됨
- DDSP는 이와 대조적으로, room acoustics를 post-synthesis convolution step으로 explicitly factorizing 함으로써 interpretability를 얻음
- Realistic room impulse response (IR)은 매우 긴 convolutional kernel size에 해당함
- 이때 matrix multiplication을 통한 convolution은 $\mathcal{O}(n^{3})$으로 늘어나므로 큰 kernel size에는 적합하지 않음
- 따라서 DDSP는 frequency-domain에서 convolution multiplication을 explicitly performing 하여 $\mathcal{O}(n\, \log\,n)$으로 증가하는 reverb를 구현
3. Experiments
- Supervised DDSP autoencoder는 audio에서 추출된 fundamental frequency ($F_{0}$)와 loudness feature로 condition 됨
- Unsupervised DDSP autoencoder는 $F_{0}$를 network의 나머지 부분과 함께 jointly learning

- DDSP AutoEncoder
- DDSP component는 생성 모델 종류 (VAE, GAN, Flow 등) 선택에 제한이 없음
- 다만 논문에서는 DDSP component의 strength를 확인하기 위해 deterministic autoencoder를 활용
- 특히 convolution layer를 활용하는 autoencoder는 DDSP component를 통해 audio-domain에서 autoencoder의 성능을 향상 가능
- 이때 GAN, VAE, Flow와 같은 stochastic latent를 반영하면 그 성능을 더 향상할 수 있음 - Standard autoencoder는,
- Encoder network $f_{enc}(\cdot)$은 input $x$를 latent representation $z= f_{enc}(x)$에 mapping
- Decoder network $f_{dec}(\cdot)$은 input $\hat{x} = f_{dec}(z)$를 reconstruct - DDSP autoencoder는 DDSP component와 decomposed latent representation을 사용
- 다만 논문에서는 DDSP component의 strength를 확인하기 위해 deterministic autoencoder를 활용
- Encoder
- Supervised autoencoder의 경우
- Loudness $l(t)$는 audio에서 직접 추출되고, fundamental frequency를 추출하기 위해 pretrained CREPE 모델을 $f(t)$ encoder로 사용
- Optional encoder는 residual information의 time-varying encoding $z(t)$를 추출
- $z(t)$ encoder의 경우,
- Harmonics에 대한 smoothed spectral envelope에 해당하는 MFCC coefficient를 추출한 다음,
- Single GRU layer를 통해 frame 당 16개의 latent variable로 변환
- Unsupervised autoencoder의 경웅
- Pretrained CREPE 모델은 audio의 mel-scale log spectrogram에서 $f(t)$를 추출하는 ResNet architecture로 대체됨
- 이후 network의 나머지 부분과 함께 jointly train
- Supervised autoencoder의 경우
- Decoder
- Decoder network는 additive, filtered noise synthesizer를 제어하기 위해 tuple $(f(t), l(t), z(t))$를 mapping
- Synthesizer는 해당 parameter를 기반으로 audio를 생성하고 합성된 audio와 original audio 사이의 reconstruction loss를 최소화함
- Network architecture는 일반적인 single recurrent layer를 포함한 fully connected network를 사용 - 추가적으로 latent $f(t)$는 additive synthesizer에 직접 제공됨
- 주어진 dataset의 context의 바깥에서 synthesizer에 대한 structural meaning을 가지기 때문
- 해당 disentangled representation을 통해 모델은 interpolation 뿐만 아니라 data 분포 바깥의 extrapolation을 가능하게 함
- Model Size
- DDSP는 GANSynth, WaveRNN, WaveNet Autoencoder와 비교하여 가장 적은 parameter를 가짐
- 초기 실험에서 사용된 WaveNet Autoencoder 보다 300배 작은 DDSP 모델은 합리적인 품질과 low-latency를 보임

- Multi-scale Spectral Loss
- AutoEncoder는 reconstruction loss를 최소화하는 것을 목표로 함
- Audio waveform의 경우, raw waveform에 대한 point-wise loss가 이상적이지 않음
- 지각적으로 동일한 audio sample이라도 서로 다른 waveform을 가질 수 있고, 결과적으로 point-wise similarity가 다를 수 있기 때문 - 따라서 multi-scale spectral loss를 채택
- Original audio와 합성된 audio가 주어지면, 주어진 FFT size $i$를 사용하여 각각의 magnitude spectrogram $S_{i}$, $\hat{S}_{i}$를 계산함
- 이때 loss는 $S_{i}$와 $\hat{S}_{i}$ 간의 $L_{1}$ distance와 $\log S_{i}$와 $\log \hat{S}_{i}$ 사이의 $L_{1}$ distance의 합:
(Eq. 4) $L_{i} = ||S_{i}-\hat{S}_{i}||_{1} + \alpha ||\log S_{i}-\log \hat{S}_{i}||_{1}$
- $\alpha$ : weighting term (논문에서는 1.0으로 사용)
- Total reconstruction loss는 모든 spectral loss의 합으로써, $L_{reconstruction} = \sum_{i} L_{i}$
- 결과적으로 $L_{i}$는 다양한 spatial-temporal resolution에 대해 orignial audio와 합성 audio 사이의 차이점을 반영
- Audio waveform의 경우, raw waveform에 대한 point-wise loss가 이상적이지 않음
4. Results
- Settings
- Datasets : NSynth, Solo Violin
- Comparisons : WaveRNN
- High-Fidelity Synthesis
- DDSP autoencoder는 Solo Violin dataset를 정확하게 재합성하는 방식을 학습할 수 있음
- 특히 DDSP는 기존의 large autoregressive 모델이나 adversarial loss와 비교하여 비교적 간단한 $L_{1}$ spectrogram loss와 적은 양의 data 만으로도 우수한 결과를 달성
- DDSP 모델이 neural network의 expressive power를 잃지 않으면서 DSP component의 bias를 효율적으로 활용할 수 있음을 의미

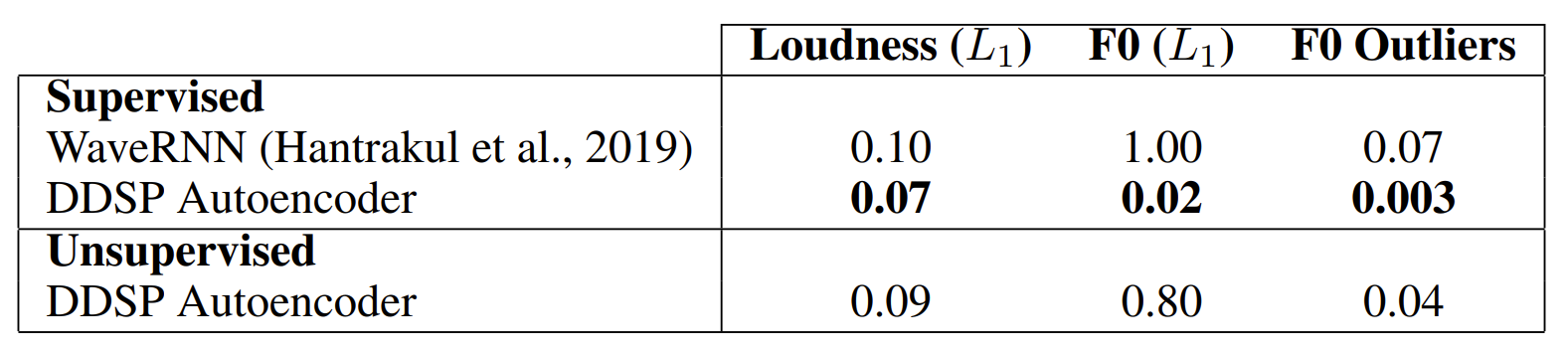
- NSynth dataset의 경우도 마찬가지로 DDSP가 WaveRNN과 비교하여 더 우수한 합성 품질을 제공함
- Unsupervised DDSP autoencoder의 경우 audio에서 직접 $F_{0}$ conditioning signal을 추론하는 방법을 학습해야 함
- Unsupervised DDSP의 경우 Supervised DDSP 만큼의 합성 품질을 보이지는 못했지만, 여전히 WaveRNN 보다는 우수한 합성이 가능
- Independent Control of Loudness and Pitch
- Interpolation
- DDSP는 interpretable structure를 통해 generative factor에 대한 독립적인 제어가 가능
- Factorized latent variable $(f(t), l(t), z(t))$는 일치하는 perceptual axis를 따라 sample을 독립적으로 변경 - 아래 그림과 같이 $l(t)$를 통한 loudness conditiong의 경우, 다른 variable을 일정하게 유지하면 합성된 audio와 interpolated input이 거의 일치하게 나타나는 것을 확인 가능
- 추가적으로 loudness와 pitch가 $(f(t), l(t))$에 의해 explicitly control 되는 경우, 모델은 residual $z(t)$를 활용하여 timbre를 encoding 함
- DDSP는 interpretable structure를 통해 generative factor에 대한 독립적인 제어가 가능

- Extrapolation
- $f(t)$는 additive synthesizer를 제어하고 dataset 외부에서 structural meaning을 가짐
- 따라서 DDSP는 data point 간의 interpolation 외에도 unseen condition을 extrapolate 할 수 있음 - 아래 그림에서 가장 오른쪽은 $f(t)$를 한 옥타브 shifting 하여 training data의 바깥으로 옮긴 경우에 대한 합성 결과를 보여줌
- 결과적으로 audio는 extrapolation 상황에 대해서도 coherent를 유지하는 것을 보임
- $f(t)$는 additive synthesizer를 제어하고 dataset 외부에서 structural meaning을 가짐

- Dereverberation and Acoustic Transfer
- Blind setting에서 reverb removing을 실험
- DDSP는 modular approach를 제공하기 때문에 source audio를 room effect와 완전히 분리하는 것이 가능함
- 위 그림의 왼쪽면에 나타난 것처럼 DDSP의 합성과정에서 reverb module을 bypass 하면, anechoic chamber에서 녹음하는 것과 비슷하게 완전한 dereverberated audio를 생성해냄
- Timbre Transfer
- Singing voice를 violin으로 변환하는 timbre transfer 결과를 확인해 보면,
- Violin dataset의 timbre와 room acoustic을 사용하여 노래의 여러 subtleties를 capture 가능
- 특히 노래에서 unvoiced syllable에 해당하는 silence에 대해 DDSP는 breathing artifact를 생성함

반응형
'Paper > ETC' 카테고리의 다른 글
댓글