

티스토리 뷰
Paper/SVS
[Paper 리뷰] X-Singer: Code-Mixed Singing Voice Synthesis via Cross-Lingual Learning
feVeRin 2024. 11. 2. 10:10반응형
X-Singer: Code-Mixed Singing Voice Synthesis via Cross-Lingual Learning
- Singing Voice Synthesis는 여전히 musical score의 annotation에 의존적이고 code-mixed singing voice를 생성하는 데는 한계가 있음
- X-Singer
- Phoneme annotation이 없는 code-mixed lyrics로 구성된 music score를 처리하는 music score encoder를 도입
- Music score encoder는 code-mixed lyrics를 encode하기 위해 language code-switching을 채택하고, phoneme annotation에 대한 의존성을 줄이기 위해 mixture alignment를 활용 - 추가적으로 conditional flow matching-based decoder를 사용하여 합성 품질을 향상
- Phoneme annotation이 없는 code-mixed lyrics로 구성된 music score를 처리하는 music score encoder를 도입
- 논문 (INTERSPEECH 2024) : Paper Link
1. Introduction
- Singing Voice Synthesis (SVS)는 lyrics와 note information이 포함된 phoneme-level annotated musical score를 input으로 하여 acoustic feature를 예측함
- 일반적으로 SVS는 mono-lingual task에서는 우수한 성능을 보이지만 Musical Score (MS)의 phoneme-level annotation에 의존적이고 code-mixed singing voice 측면에서는 한계가 있음
- 한편으로 realistic MS는 아래 그림과 같이 phoneme-level annotation이 없는 code-mixed lyrics로 구성되지만, 다음의 한계점을 가짐:
- 대부분의 방식들은 아래 그림의 (b)와 같은 phoneme-level annotation을 사용하여 training됨
- 따라서 unseen singing voice를 추론하기 위해서는 forced alignment나 heuristic을 통해 realistic MS를 phoneme-level annotation으로 변환해주어야 함 - 기존 SVS dataset은 annotation의 어려움으로 인해 multi-lingual song이 부족함
- 따라서 code-mixed lyrics가 포함된 realistic MS를 처리하기 어려움 - 서로 다른 grapheme-/phoneme-based lyrics를 International Phonetic Alphabet (IPA)로 변환하면 imprecise result가 발생하므로 lyrics를 unified token으로 represent 하기 어려움
- 대부분의 방식들은 아래 그림의 (b)와 같은 phoneme-level annotation을 사용하여 training됨
-> 그래서 realistic MS에 대해서도 안정적인 합성이 가능한 code-mixed SVS model인 X-Singer를 제안
- X-Singer
- Realistic MS를 처리하기 위해 MS encoder를 도입
- MS encoder는 code-mixed lyrics와 mixture alignment에 code-switching을 도입하여 phoneme-level annotation에 대한 dependency를 완화 - 추가적으로 합성 품질을 향상하기 위해 Conditional Flow Matching (CFM)-based decoder를 채택
- Realistic MS를 처리하기 위해 MS encoder를 도입
< Overall of X-Singer >
- Cross-lingual language learning을 활용한 code-mixed SVS model
- 결과적으로 기존보다 뛰어난 합성 성능을 달성

2. Method
- Musical Score Encoder
- 논문은 MS encoder를 사용하여 realistic MS에서 musical score representation을 추출함
- 구조적으로 MS encoder는 lyrics encoder, melody encoder, phoneme-to-phoneme cross-attention을 가짐
- 먼저 lyrics encoder는 feed-forward transformer block과 Mix-Layer Normalization (Mix-LN) transformer block으로 구성됨
- 일반적으로 same lyrics를 share 하지 않는 mono-lingual SVS dataset의 mixture로 training 하면 lyrics representation은 singer identity와 associate 될 수 있음
- 따라서 singer identity 내의 language information을 disentangle 하여 code-mixed lyrics representation을 추출하는 것이 필요함 - 이를 위해 논문은 singer에 대한 bias를 줄이고 unseen scenario에 대한 generalization을 향상할 수 있는 Mix-LN transformer를 채택함
- 해당 Mix-LN은 speaker embedding의 feature statistics를 mix 하여 mismatched speaker information을 생성해 model을 confuse 함:
(Eq. 1) $\text{Mix-LN}(h,e_{spk})=\gamma_{mix}(e_{spk})\frac{h-\mu}{\sigma}+\beta_{mix}(e_{spk})$
(Eq. 2) $\gamma_{mix}(e_{spk})=\lambda\gamma(e_{spk})+(1-\lambda)\gamma(\tilde{e}_{spk})$
(Eq. 3) $\beta_{mix}(e_{spk})=\lambda\beta(e_{spk})+(1-\lambda)\beta(\tilde{e}_{spk})$
- $\mu, \sigma$ : hidden representation $h$의 평균, 분산
- $\gamma, \beta$ : speaker embedding $e_{spk}$를 취하는 simple linear layer
- $\tilde{e}_{spk}$ : batch axis를 따라 shuffling operation을 수행하여 얻어짐
- $\lambda$ : Beta distribution $\lambda \sim \text{Beta}(\alpha, \alpha)$에서 sampling 됨 ($\alpha=0.2$)
- 일반적으로 same lyrics를 share 하지 않는 mono-lingual SVS dataset의 mixture로 training 하면 lyrics representation은 singer identity와 associate 될 수 있음
- Lyrics encoder는 positional embedding을 사용하여 lyrics, language embedding sequence를 concatenate함
- Concatenation 이전에 논문은 International Phonetic Alphabet (IPA) symbol을 사용하여 lyrics sequence를 변환함
- 추가적으로 language code-switching을 위해 phoneme-level language embedding을 사용
- Phoneme-to-note encoder의 경우 note-level average pooling operation을 적용하여 lyrics encoder output을 compress 함
- Phoneme-to-note encoder는 compressed lyrics representation에서 note-level lyrics representation을 추출하는 역할 - Melody encoder는 musical scroe의 note-related feature (pitch, duration, tempo)를 사용함
- 결과적으로 melody encoder는 note-level pitch, duration tempo embedding을 positional embedding과 concatenate 한 다음, note-level meolody representation을 추출함
- 이후 note duration에 따라 note-level lyrics representation과 melody representation의 summation을 expand 함
- X-Singer는 note에서 actual phoneme boundary를 얻기 위해 PortaSpeech의 mixture alignment를 도입함
- Musical score는 일반적으로 syllable이나 word를 note로 mapping 하므로 note에서 phoneme-level soft alignment를 사용하고 note-level hard alignment는 keep 함
- Mixture alignment를 얻기 위해 논문은 lyrics representation을 key $K$와 value $V$로 제공하고, frame-level melody representation을 phoneme-to-phoneme cross-attention에 대한 query $Q$로 제공함
- 이때 attention module 이전에 relative positional embedding을 추가하여 attention alignment를 close-to-diagonal로 만듦
- 추가적으로 각 note의 phoneme-level representation이 preceding/succeding note에 모두 attend 하도록 하여 note-level alignment의 hardness를 완화함
- Close-to-diagonal을 위해 guided attention loss $\mathcal{L}_{ga}$를 채택할 수 있음:
(Eq. 4) $\mathcal{L}_{ga}=\mathbb{E}_{nt}[A_{nt}W_{nt}]$
(Eq. 5) $W_{nt}=1-e^{-(n/N-t/T)^{2}/2g^{2}}$
- $A\in\mathbb{R}^{N\times T}$ : attention matrix
- $N, T$ : 각각 lyrics 수, mel-frame 수
- $g=0.3$으로 설정
- Musical score는 일반적으로 syllable이나 word를 note로 mapping 하므로 note에서 phoneme-level soft alignment를 사용하고 note-level hard alignment는 keep 함
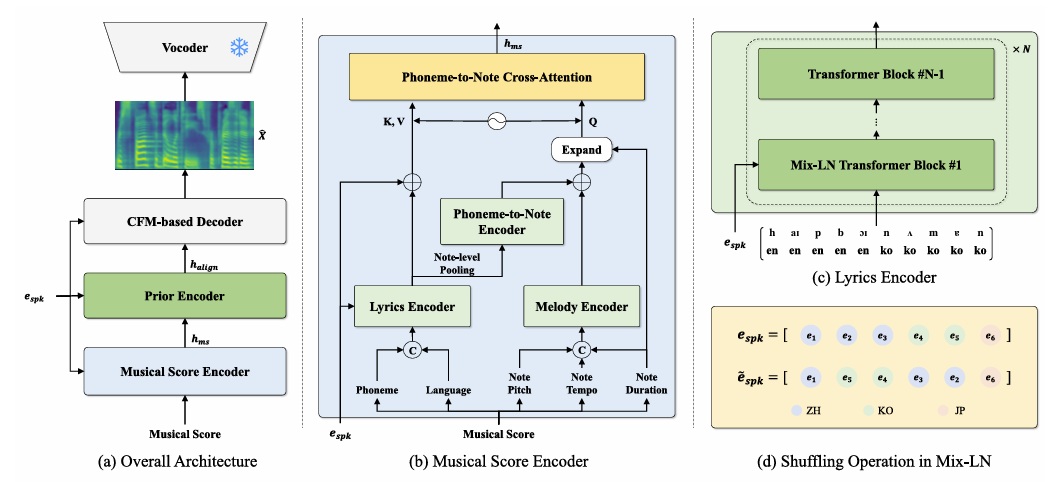
- CFM-based Decoder
- Prior Encoder
- Prior Encoder는 musical score representation $h_{ms}$를 aligned hidden representation $h_{align}$으로 encode 함
- 여기서 논문은 Conditional Layer Normalization을 사용하여 speaker information을 adapt 함:
(Eq. 6) $\text{CLN}(h,e_{spk})=\gamma(e_{spk})\frac{h-\mu}{\sigma}+\beta(e_{spk})$
- $\gamma, \beta$ : speaker embedding $e_{spk}$에 대한 gain, bias
- $h$ : prior encoder의 hidden representation - Aligned hidden representation $h_{align}$은 mel-spectrogram과 같은 averaged acoustic feature를 사용하여 Conditional Flow Matching (CFM)-based deocoder를 conditioning 함
- 그러면 hidden representation $h_{align}$은 다음과 같이 target mel-spectrogram $x$를 사용하여 regularize 됨:
(Eq. 7) $\mathcal{L}_{p}=\text{MSE}(h_{align},x)$
- Decoder
- Matcha-TTS, P-Flow, VoiceBox의 flow matching을 따라 conditional vector field $u_{t}$를 모델링하는 CFM-based decoder를 채택하여 Ordinary Differential Equation (ODE)를 통한 flow를 생성함
- 먼저 conditional flow $\phi_{t,x_{1}}$을 target data $x_{1}\sim q(x)$와 prior distribution $x_{0}\sim \mathcal{N}(0,I)$ 간의 simple linear trajectory로 정의하자:
(Eq. 8) $\phi_{t,x_{1}}(x)=(1-(1-\sigma_{\min})t)x_{0}+tx_{1}$
- $t\in[0,1]$ : flow에 대한 time step
- $\sigma_{\min}$ : small white noise의 perturbation을 위한 hyperparameter - 그러면 CFM-based decoder $v_{\theta}$를 다음의 objective로 training 할 수 있음:
(Eq. 9) $\mathcal{L}_{cfm}=\mathbb{E}_{t,q(x),p_{0}(x_{0})}|| u_{t}(\phi_{t,x_{1}}(x_{0}))-v_{\theta}( \phi_{t,x_{1}}(x_{0}),h_{align},e_{spk},t)||^{2}$
- $h_{align}$ : prior encoder로 얻은 hidden representation
- $e_{spk}$ : speaker embedding - 이후 다음을 solve 하여 target vector field $u_{t}$를 얻을 수 있음:
(Eq. 10) $u_{t}(\phi_{t,x_{1}}(x_{0}))=\frac{d}{dt}\phi_{t,x_{1}}(x_{0})=x_{1}- (1-\sigma_{\min})x_{0}$
- 먼저 conditional flow $\phi_{t,x_{1}}$을 target data $x_{1}\sim q(x)$와 prior distribution $x_{0}\sim \mathcal{N}(0,I)$ 간의 simple linear trajectory로 정의하자:
- 추론 시에는 ODE solver를 사용하여 주어진 predicted vector field $\frac{d}{dt}\phi_{t,x_{1}}(x_{0})=v_{\theta}(\phi_{t,x_{1}}(x_{0}),h_{align},e_{spk},t)$와 initial condition $x_{0}$에 대한 $\phi_{1,x_{1}}(x_{0})$를 얻음
- Matcha-TTS, P-Flow, VoiceBox의 flow matching을 따라 conditional vector field $u_{t}$를 모델링하는 CFM-based decoder를 채택하여 Ordinary Differential Equation (ODE)를 통한 flow를 생성함
- Total Loss
- 결과적으로 X-Singer의 total loss는:
(Eq. 11) $\mathcal{L}=\mathcal{L}_{p}+\mathcal{L}_{cfm}+\lambda_{ga}\mathcal{L}_{ga}$
- $\lambda_{ga} = 10.0$으로 설정
3. Experiments
- Settings
- Dataset : Multi-Speaker Singing Dataset, M4Singer, Ofuton-P Database
- Comparisons : FFTSinger, DiffSinger

- Results
- 전체적으로 X-Singer가 가장 우수한 성능을 보임
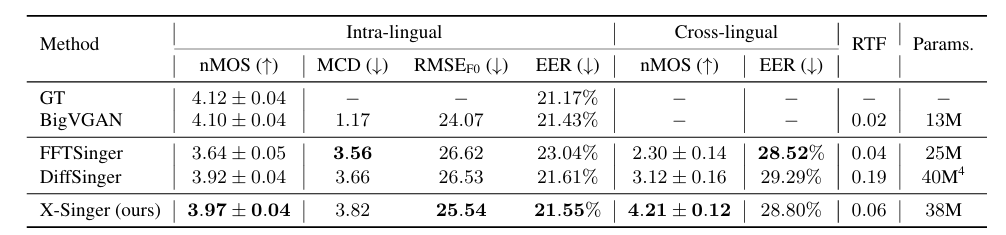
- Ablation Study
- Ablation Study 측면에서 각 component를 제거하는 경우 성능 저하가 발생함

반응형
'Paper > SVS' 카테고리의 다른 글
댓글