

티스토리 뷰
Paper/TTS
[Paper 리뷰] SALTTS: Leveraging Self-Supervised Speech Representations for Improved Text-to-Speech Synthesis
feVeRin 2024. 6. 25. 09:49반응형
SALTTS: Leveraging Self-Supervised Speech Representations for Improved Text-to-Speech Synthesis
- Text-to-Speech에서 richer representation을 반영하기 위해 Self-Supervised Learning model을 활용할 수 있음
- SALTTS
- Self-Supervised Learning representation을 reconstruct 하기 위해 encoder layer를 통해 FastSpeech2 encoder의 length-regulated output을 전달함
- SALTTS-parallel에서 해당 encoder representation은 auxiliary reconstruction loss로 사용되고, SALTTS-cascade에서는 reconstruction loss 외에 추가적인 decoder에도 해당 representation이 전달됨
- 논문 (INTERSPEECH 2023) : Paper Link
1. Introduction
- Text-to-Speech (TTS)의 합성 품질을 향상하려면 large labeled data가 필요하므로 time-consuming 하고 expansive 함
- 이때 Self-Supervised Learning (SSL)을 활용하면 이러한 labeled data constraint를 해결할 수 있음
- WavLM, HuBERT 등은 emotion, speaker recognition과 같은 downstream speech task에서 우수한 성능을 달성함
- BUT, TTS에서 SSL representation을 사용하는 것은 상대적으로 고려되지 않음 - 대표적인 TTS 모델인 FastSpeech2는 text transcription에서 audio의 pitch, energy information을 예측하는 방식으로 training 되어 다양한 speech variation과 nuance를 반영할 수 있음
- 특히 FastSpeech2는 non-autoregressive 특성으로 빠른 학습과 추론을 지원하고, 수정이 용이한 간단한 architecture을 가짐
- 추가적으로 HiFi-GAN과 같은 pre-trained Generative Adversarial Network (GAN) 기반의 vocoder을 사용하면 합성 품질을 더욱 향상할 수 있음
- 이때 Self-Supervised Learning (SSL)을 활용하면 이러한 labeled data constraint를 해결할 수 있음
-> 그래서 FastSpeech2를 기반으로 음성의 variability를 향상하는 SSL representation을 반영한 SALTTS를 제안
- SALTTS
- FastSpeech2를 기반으로 SSL model에 의해 생성된 embedding을 예측하는 additional encoder block (SSL predictor)를 도입
- 이를 통해 FastSpeech2의 energy, pitch information 외에도 broader range의 variant를 capture 할 수 있도록 함 - 이때 SALTTS-parallel, SALTTS-cacade의 2가지 variant를 구성
- 특히 SALTTS-parallel은 training 중에 SSL representation의 additional information을 학습하면서 FastSpeech2 수준의 속도를 유지하는 것을 목표로 함 - 추가적으로 다양한 sampling rate, window size, hop length를 describe 하기 위한 additional repeater module을 도입
- 해당 module을 통해 예측된 SSL embedding과 ground-truth SSL embedding 간의 더 나은 alignment를 보장
- FastSpeech2를 기반으로 SSL model에 의해 생성된 embedding을 예측하는 additional encoder block (SSL predictor)를 도입
< Overall of SALTTS >
- SSL representation을 FastSpeech2에 도입하는 것을 목표로 SALTTS-parallel과 SALTTS-cacade의 2가지 variant를 구성
- 결과적으로 기존보다 뛰어난 합성 품질을 달성
2. Method
- 논문에서는 acoustic model의 embedding을 향상하기 위해 multi-task loss를 사용하고 SSL representation에 대한 repeater module을 도입함
- Motivation
- FastSpeech2 architecture는 teacher model의 output 대신 ground-truth target을 사용해 training 됨으로써 기존의 FastSpeech를 개선함
- 추가적으로 FastSpeech2는 waveform에서 duration/pitch/energy를 추출하고 training에서 conditional input으로 사용하여 variability를 향상함
- BUT, speech signal은 emotion, intent, emphasis 등의 여러 characteristic 가지므로 본질적으로 complex 함
- 이때 FastSpeech2와 같이 predictor를 사용하면, 각 speech aspect에 대한 rich ground-truth information을 직접적으로 사용할 수 없음 - 한편으로 SSL paradigm을 사용하여 pre-train 된 model은 emotion detection, speaker recognition과 같은 다양한 speech task를 generalize 할 수 있음
- 따라서 논문은 SSL model의 embedding을 활용하여 다양한 speech aspect를 반영하는 것을 목표로 함
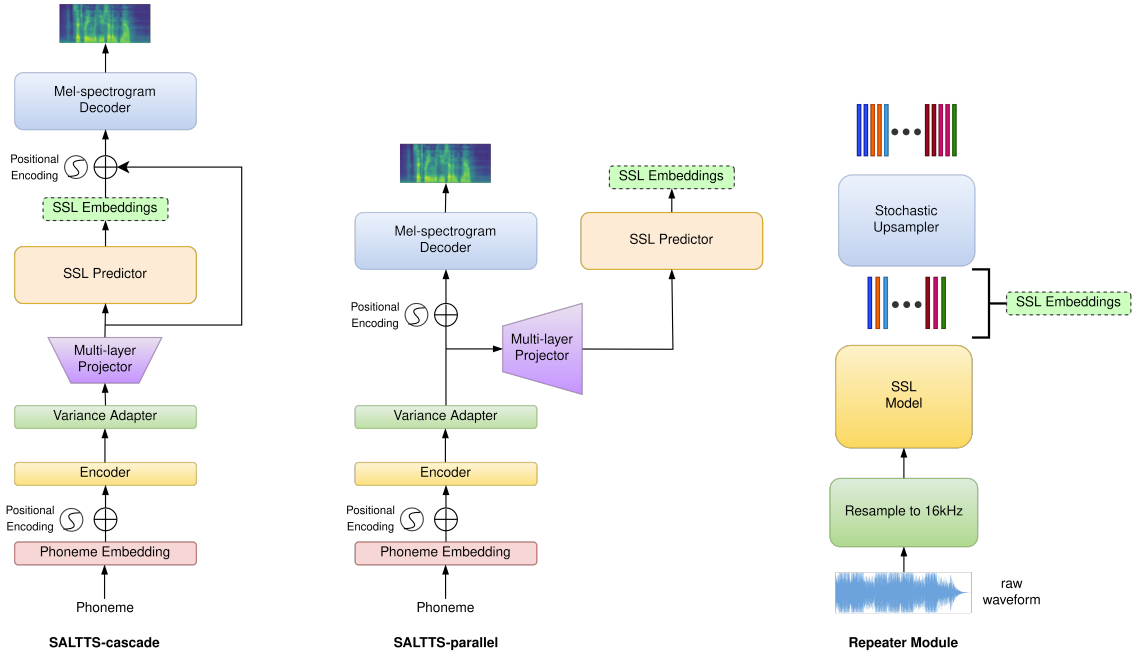
- Architecture and Variants
- 논문은 LJSpeech dataset의 모든 utterance에 대해 SSL representation을 추출함
- 이때 해당 representation은 768-dimension을 가지므로, FastSpeech2의 variance adpator에 의해 생성된 384-dimensional embedding은 multi-layer projector를 통과하여 768-dimensional emedding으로 변환됨
- 4-layer encoder block (SSL predictor)는 multi-layer projector에서 해당 embedding을 가져와 training stage에서 SSL model이 생성한 representation을 예측함
- 여기서 auxiliary $L1$-loss는 encoder에서 예측된 embedding과 SSL model representation으로 계산됨:
(Eq. 1) $\mathcal{L}_{aux} =\sum_{i=1}^{n}|y-\hat{y}_{i}|$
- $\mathcal{L}_{aux}$ : auxiliary SSL embedding loss, $y, \hat{y}$ : 각각 true/predicted SSL emebeding, $n$ : total datapoint 수
- 이때 해당 representation은 768-dimension을 가지므로, FastSpeech2의 variance adpator에 의해 생성된 384-dimensional embedding은 multi-layer projector를 통과하여 768-dimensional emedding으로 변환됨
- SALTTS-parallel
- SALTTS-parallel은 FastSpeech2 구조를 유지하면서 variance adaptor의 representation을 mel-spectrogram decoder로 직접 전달함
- 이때 decoder는 variance adaptor embedding을 처리하고, 동시에 multi-layer projector에서는 SSL representation을 예측한 다음, additional $L1$ loss를 계산함
- 이를 통해 SSL representation의 richness를 활용하면서 FastSpeech2의 속도를 유지할 수 있음 - 한편으로 추론 시에 auxiliary $L1$ loss는 사용되지 않음
- SALTTS-cascade
- SALTTS-cacade에서 mel-spectrogram decoder는 SSL predictor의 768-dimensional representation과 함께 동작함
- 이때 빠른 수렴을 보장하기 위해 multi-layer projector output에 residual connection이 추가됨 - Auxiliary $L1$ loss는 residual connection 이전의 SSL predictor embedding과 SSL model의 representation을 통해 계산됨
- 여기서 decoder의 attention dimension은 SSL predictor로 생성된 768-dimensional embedding과 일치하기 위해 768로 설정됨
- SALTTS-cacade에서 mel-spectrogram decoder는 SSL predictor의 768-dimensional representation과 함께 동작함
- Repeater Module
- SALTTS는 SSL predictor의 representation과 SSL model representation 간의 additional $L1$ loss를 계산하기 위해, FastSpeech2와 SSL model 간의 sampling frequency, hop length를 match 해야 함
- 먼저 대부분의 speech SSL model은 16kHz의 sampling rate에서 동작하지만 FastSpeech2는 22.05kHz sampling rate에서 동작함
- Frame-level embedding 측면에서 SSL model은 25ms window size와 20ms hop length를 사용하지만, FastSpeech2는 45.6ms window size와 11.6ms hop length를 사용함 - 따라서 해당 frame-level information의 mismatch를 해결하기 위해서는 SSL representation set를 SSL predictor의 embedding에 align 해야 함
- 이때 time-level analysis 측면에서 SSL model의 처음 5개 frame은 FastSpeech2의 처음 7개 frame과 일치함 - 여기서 논문은 aligned frame을 생성하기 위해, FastSpeech2의 frame 수와 일치하도록 SSL model의 2번째, 4번째 frame을 repeat 하는 방식을 채택함
- 먼저 SSL model의 매 18개 frame은 time-domain에서 FastSpeech2의 31개 frame과 align 됨
- 여기서 해당 alignment를 보장하기 위해 $\{2,2,1\}$-strategy를 활용함
- 즉, SSL model의 3개 frame 마다 standard Normal distribution에서 sampling 된 Gaussian noise를 추가한 다음
- 첫 번째 frame을 한번, 두 번째 frame을 한번 repeat 하고, 세 번째 frame은 그대로 둠 - 해당 strategy를 기반으로 나머지 frame set에 대해 match 될 때까지 frame 수를 늘린 다음, repetition이 끝나면 end frame을 drop 함
- 먼저 SSL model의 매 18개 frame은 time-domain에서 FastSpeech2의 31개 frame과 align 됨
- 결과적으로 해당 repeater module은 additional $L1$ loss가 계산되기 전에, 두 embedding set 간의 time-domain alignment를 보장함
- 먼저 대부분의 speech SSL model은 16kHz의 sampling rate에서 동작하지만 FastSpeech2는 22.05kHz sampling rate에서 동작함
3. Experiments
- Settings
- Dataset : LJSpeech
- Comparisons : FastSpeech2
- SSL Representations : data2vec-aqc, ccc-wav2vec 2.0, HuBERT
- Results
- MOS, $F_{0}$ RMSE 측면에서 HuBERT를 사용한 SALTTS가 가장 우수한 성능을 보임

반응형
'Paper > TTS' 카테고리의 다른 글
댓글