

티스토리 뷰
Paper/Representation
[Paper 리뷰] Data2Vec-AQC: Search for the Right Teaching Assistant in the Teacher-Student Training Setup
feVeRin 2025. 4. 10. 17:53반응형
Data2Vec-AQC: Search for the Right Teaching Assistant in the Teacher-Student Training Setup
- Unlabeled speech data로부터 speech representation을 얻기 위해 Self-Supervised Learning을 활용할 수 있음
- Data2Vec-AQC
- Data2Vec을 기반으로 data augmentation, quantized representation, clustering을 도입
- 각 module의 interaction을 통해 additional self-supervised objective인 cross-contrastive loss를 solve
- 논문 (ICASSP 2023) : Paper Link
1. Introduction
- Self-Supervised Learning (SSL)은 Wav2Vec 2.0과 같이 unlabeled data로부터 speech representation을 학습하는데 효과적임
- 이를 위해 대부분의 방식은 Masked Acoustic Modeling (MAM)을 활용함
- 특히 Data2Vec은 latent target에 대한 SSL-based representation을 얻을 수 있음 - BUT, SSL은 limited unlabeled data에서 효과적인 representation을 얻기 어려움
- 이때 data augmentation을 도입하면 SSL model의 generalizability를 향상할 수 있음
- 이를 위해 대부분의 방식은 Masked Acoustic Modeling (MAM)을 활용함
-> 그래서 low-resource unlabeled speech에서도 효과적인 representation을 얻을 수 있는 SSL-based pre-training method인 Data2Vec-AQC를 제안
- Data2Vec-AQC
- Data2Vec을 기반으로 randomly augmented audio sample을 전달하여 teacher/student network 간의 MAM-based cross-contrastive task를 개선
- Quantized representation에서 negatives를 sampling 하기 위해 quantizer module을 도입
- 추가적으로 quantized representation을 cluster 하고 contrastive loss computation에서 negatives의 영향을 control 하는 clustering module을 적용
< Overall of Data2Vec-AQC >
- Data2Vec을 기반으로 augmentation, quantization, clustering을 적용한 SSL method
- 결과적으로 unlabeled speech에 대해 기존보다 우수한 성능을 달성
2. Method
- Data2Vec은 raw speech를 input으로 사용하는 student/teacher network로 구성되고, teacher parameter는 student의 exponential moving average를 통해 update 됨
- 특히 $L_{2}$ loss는 linear projection으로 얻어지는 student embedding과 teacher network의 top-8 layer에 대한 average embedding을 통해 compute 됨
- $L_{1}$ loss를 사용할 수도 있지만, simple $L_{2}$ loss가 speech processing 더 효과적임 - 여기서 논문은 Data2Vec student-teacher learning framework에 대한 적절한 teaching assistant를 도입하는 것을 목표로 함
- 이를 위해 Augmentation, Quantizer module, Clustering module을 활용함
- 특히 $L_{2}$ loss는 linear projection으로 얻어지는 student embedding과 teacher network의 top-8 layer에 대한 average embedding을 통해 compute 됨

- Augmentations (Data2Vec-A)
- 먼저 Data2Vec-A는 Data2Vec framework의 feature extraction stage 이전에 raw audio에 대한 augmentation을 적용하는 것을 목표로 함
- 해당 augmentation을 Data2Vec setting에 추가해도 loss computation에는 영향을 미치지 않으므로, 기존 loss $\mathcal{L}_{2}=\frac{1}{2}(s_{t}-y_{t})^{2}$을 사용할 수 있음
- $s_{t}$ : masked time-step $t$에 대한 student network embedding
- $y_{t}$ : teacher network의 top-8 layer에 대한 average embedding - 이때 $\mathcal{L}_{2}$ loss 외에도 student/teacher의 latent embedding에 대한 additional contrastive loss를 도입할 수 있음
- Audio sampe $X$가 주어졌을 때, $S_{t}$를 student embedding $Y_{t}$를 모든 masked time-step에 대한 teacher embedding이라고 하자
- 그러면 teacher embedding에서 negatives를 sampling 함으로써, 각 masked time-step $t$에 대한 contrastive loss를 얻을 수 있음:
(Eq. 1) $\mathcal{L}_{con}=-\log \frac{\exp(\text{sim}(s_{t},y_{t})/\kappa)}{\sum_{\tilde{y}\sim Y_{t}} \exp(\text{sim}(s_{t},\tilde{y})/\kappa)}$
- $s_{t}\in S_{t},y_{t}\in Y_{t}$, $\kappa$ : temperature
- $\text{sim}(a,b)=a^{\top}b/||a||\,||b||$ : student/teacher representation 간의 cosine-similarity
- 해당 augmentation을 Data2Vec setting에 추가해도 loss computation에는 영향을 미치지 않으므로, 기존 loss $\mathcal{L}_{2}=\frac{1}{2}(s_{t}-y_{t})^{2}$을 사용할 수 있음
- Quantized Representations (Data2Vec-AQ)
- Wav2Vec 2.0과 같이 discrete quantized representation에서 positive/negative sample에 대한 contrastive loss를 calculate 하면 효과적인 speech representation을 얻을 수 있음
- 따라서 Wav2Vec 2.0의 quantizer module을 활용하여 Data2Vec-AQ를 구성함
- 먼저 $X^{s}, X^{y}$를 각각 student/teacher에서 추출된 feature라고 하자
- 해당 embedding을 quantizer에 전달하면 discrete representation $Q^{s}, Q^{y}$를 얻을 수 있음 - 여기서 Data2Vec-AQ는 augmentation을 사용하므로 cross-contrastive loss $\mathcal{L}_{cc}$를 plug-in 할 수 있음
- 먼저 $X^{s}, X^{y}$를 각각 student/teacher에서 추출된 feature라고 하자
- 즉, $S_{t}$를 student embedding, $Y_{t}$를 teacher embedding이라 하면 모든 masked time-step에 대해 각 masked time-step $t$에 대한 loss term을 얻을 수 있음:
(Eq. 2) $\mathcal{L}_{s\text{-}cross}=-\log \frac{\exp(\text{sim}(s_{t},q_{t}^{y})/\kappa)}{ \sum_{\tilde{q}\sim Q_{t}^{y}}\exp (\text{sim}(s_{t},\tilde{q})/\kappa)} $
(Eq. 3) $\mathcal{L}_{t\text{-}cross}=-\log \frac{\exp(\text{sim}(y_{t},q_{t}^{s})/\kappa)}{\sum_{\tilde{q}\sim Q_{t}^{s}}\exp(\text{sim}(y_{t},\tilde{q})/\kappa)}$
- $s_{t}\in S_{t},y_{t}\in Y_{t}$
- (Eq. 2), (Eq. 3)은 masked time-step에서 student embedding/teacher input의 quantized representation 간의 contrastive loss를 의미함 - 결과적으로 overall cross-contrastive loss를 $\mathcal{L}_{cc}$라고 하면, $\mathcal{L}_{cc}=\alpha\mathcal{L}_{s\text{-}cross}+\beta\mathcal{L}_{t\text{-}cross}$가 됨
- 그러면 Data2Vec-AQ의 total loss는 $\mathcal{L}_{2}+\mathcal{L}_{cc}$이고, $\alpha=\beta=0.5$로 설정함
- 따라서 Wav2Vec 2.0의 quantizer module을 활용하여 Data2Vec-AQ를 구성함
- Clustering of Negatives (Data2Vec-AQC)
- CCC-Wav2Vec 2.0과 같이 $k$-means clustering module을 통해 negative example을 segregate 하고, non-informative negative example effect를 control 하여 contrastive learning을 개선할 수 있음
- 결과적으로 Data2Vec-AQC는 Cluster Factor $CF$와 Scale Factor $SF$를 hyperparameter로 가지는 clustering module을 활용하여 구성됨
- 먼저 $NF$를 audio mini-batch의 speech sample 당 frame 수라고 하면, 해당 mini-batch의 audio 당 cluster 수는 $\text{ceil}(NF/CF)$와 같음
- 다음으로 $Q_{t}$를 clustering 할 때 positive sample $q_{t}$가 속하는 cluster를 identify 함
- 즉, $q_{t}$가 cluster $R$에 속하는 경우 same cluster $R$을 share 하는 speech sample의 influence를 control 하는 것이 objective가 됨 - Anchor $c_{t}$을 기준으로 $R$에서 negative sample의 cosine similarity를 scaling factor $SF$만큼 scale down 함
- 따라서 $Q^{*}$를 sampled negative example set이라고 했을 때, integrated clustering module을 사용한 contrastive loss는:
(Eq. 4) $\mathcal{L}_{c}=-\log \frac{e^{(\text{sim}(c_{t},q_{t})/\kappa )}}{\sum_{q\in R} e^{(\text{sim}(c_{t},q)\cdot SF/\kappa )}+\sum_{q\notin R}e^{(\text{sim}(c_{t},q)/\kappa)}}$
- $Q^{*}=\{\tilde{q}\sim Q_{t}\}$, $q$ : $Q^{*}$의 sample - (Eq. 4)에서 positive와 동일한 cluster를 share 하는 negative example의 influence는 scalar $SF$에 의해 결정됨
- 즉, overall loss function $\mathcal{L}_{2}+\mathcal{L}_{cc}$에서, $\mathcal{L}_{cc}$의 각 contrastive loss term은 (Eq. 4)를 따름
- 이때 논문은 pooled setting에서 $CF=16, SF=0.3$으로 hyperparameter를 설정함
- 결과적으로 Data2Vec-AQC는 Cluster Factor $CF$와 Scale Factor $SF$를 hyperparameter로 가지는 clustering module을 활용하여 구성됨
3. Experiments
- Settings
- Dataset : LibriSpeech
- Comparisons : Data2Vec, Wav2Vec 2.0
- Results
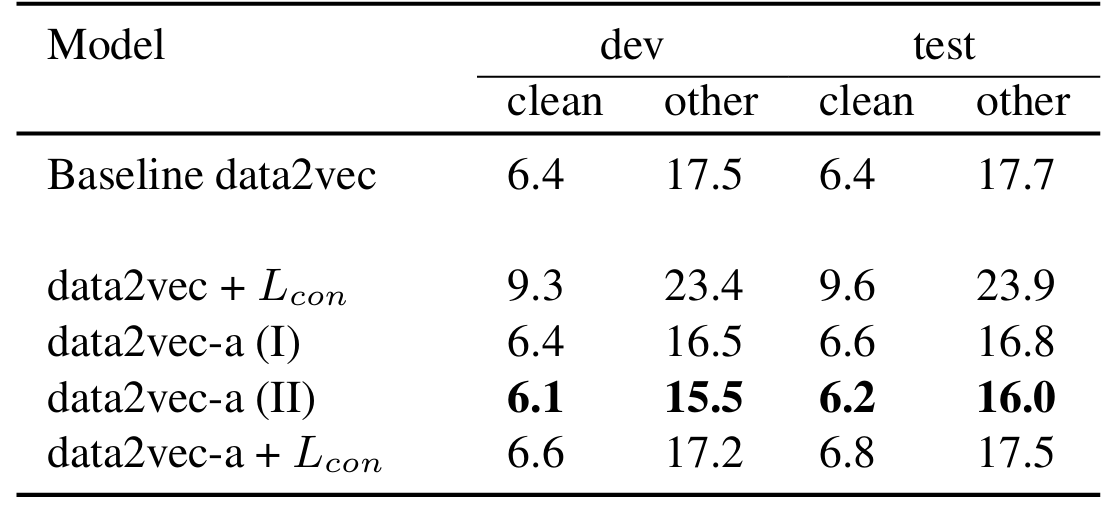
- 전체적으로 Data2Vec-AQC가 가장 우수한 성능을 보임

- Additional contrastive loss $\mathcal{L}_{con}$을 사용하는 경우 성능 저하가 발생함
반응형
'Paper > Representation' 카테고리의 다른 글
댓글