

티스토리 뷰
Paper/Vocoder
[Paper 리뷰] BiVocoder: A Bidirectional Neural Vocoder Integrating Feature Extraction and Waveform Generation
feVeRin 2024. 6. 16. 12:59반응형
BiVocoder: A Bidirectional Neural Vocoder Integrating Feature Extraction and Waveform Generation
- STFT domain 내에서 feature extraction과 reverse waveform generation이 가능한 vocoder를 구성할 수 있음
- BiVocoder
- Feature extraction을 위해 STFT에서 파생된 amplitude, phase spectrea를 input으로 사용하고, 이를 convolution network를 통해 long-frame-shift, low-dimensional feature로 변환
- Waveform generation을 위해 symmetric network를 채택하여 amplitude, phase spectra를 restore 한 후, inverse STFT를 수행
- 논문 (INTERSPEECH 2024) : Paper Link
1. Introduction
- Neural vocoder는 text-to-speech (TTS), singing voice synthesis (SVS), voice conversion (VC) 등의 다양한 task에서 활용되고 있음
- WORLD, STRAIGHT와 같은 signal processing을 기반으로 한 bidirectional vocoder는 feature extraction과 waveform generation을 모두 가지고 있음
- e.g.) STRAIGHT는 waveform에서 fundamental frequency ($F0$)와 mel-cepstral coefficient를 추출한 다음, 해당 feature를 기반으로 speech resynthesize를 수행함
- BUT, 이러한 signal processing 기반의 방식들은 합성 품질의 한계가 있음 - 한편으로 HiFi-GAN, APNet과 같은 neural vocoder는 기존 vocoder의 성능을 크게 개선했음
- 이러한 neural vocoder는 대부분 waveform generation만 수행하는 unidirectional 방식으로 동작하기 때문에 중요한 phase information을 discard 할 수 있다는 문제점이 있음
- 이를 해결하기 위해 AutoVocoder는 feature extraction 단계를 추가하여 bidirectional neural vocoder를 구성함
- Phase information을 discard하지 않고 Differentiable Digital Signal Processing (DDSP)을 적용해 learned feature로부터 waveform을 resynthesize 하는 방식 - BUT, AutoVocoder에서 추출된 feature는 기존의 mel-spectrogram 보다 높은 dimensionality를 가지고 있기 때문에 computational complexity 측면에서 한계가 있음
- 특히, AutoVocoder는 waveform에서 정의된 mel-spectrogram loss와 Generative Adversarial Network (GAN) loss를 사용하므로 여전히 explicit phase optimization을 neglecting 함
- WORLD, STRAIGHT와 같은 signal processing을 기반으로 한 bidirectional vocoder는 feature extraction과 waveform generation을 모두 가지고 있음
-> 그래서 더 효과적인 feature extraction과 waveform generation을 수행하는 bidirectional neural vocoder인 BiVocoder를 제안
- BiVocoder
- Feature extraction module은 ConvNeXt v2를 backbone으로 사용하여 STFT를 통해 speech waveform에서 추출된 amplitude와 phase spectra에 대한 deep processing을 수행
- Long-frame-shift와 low-dimensional feature를 encode 하기 위해 downsampling과 dimension reduction이 적용됨 - Waveform generation module은 추출된 feature를 amplitude, phase spectrum으로 restore 하고, inverse STFT (iSTFT)를 통해 speech waveform을 reconstruction 함
- 이를 통해 precise amplitude, phase prediction과 고품질의 waveform reconstruction을 지원
- Feature extraction module은 ConvNeXt v2를 backbone으로 사용하여 STFT를 통해 speech waveform에서 추출된 amplitude와 phase spectra에 대한 deep processing을 수행
< Overall of BiVocoder >
- Feature extraction을 위해 STFT에서 파생된 amplitude, phase spectrea를 input으로 사용하고, 이를 convolution network를 통해 long-frame-shift, low-dimensional feature로 변환
- Waveform generation을 위해 symmetric network를 채택하여 amplitude, phase spectra를 restore 한 후, iSTFT를 적용
- 결과적으로 기본적인 analysis-synthesis task 뿐만 아니라 TTS task에서도 뛰어난 음성 합성 성능을 달성
2. Method
- BiVocoder architecture는 크게 feature extraction module과 waveform generation module로 나누어짐
- Feature extraction module에서는 input speech waveform을 STFT로 처리하고, resulting amplitude/phase spectra를 병렬처리하여 long-frame-shift, low-dimensional feature를 얻음
- Waveform generation module에서는 추출된 feature를 병렬로 reconstruct 한 다음, iSTFT를 통해 raw speech waveform을 생성함

- Model Structure
- BiVocoder의 feature extraction, waveform generation은 mirror process이므로 각 module은 symmetrical structure를 가짐
- 여기서 두 module 모두 dual-branch architecture로 설계되어 prallel branch를 통해 amplitude와 phase information을 acoustic feature로 couple 한 다음, 다시 amplitude와 phase를 decouple 함
- 각 module에서 amplitude, phase branch는 ConvNeXt v2를 backbone network로 사용함
- 이때 ConvNeXt v2 network는 아래 그림과 같이, expansive receptive field에서 information을 capture 하는 large kernel을 가지는 convolution layer를 기반으로 한 여러 개의 ConvNeXt v2 block으로 구성됨
- Layer normalization은 각 block의 output을 normalizing 하고, 이후 $1\times 1$ pointwise convolution을 통해 high-dimensional space의 feature를 추출함
- 해당 feature는 GELU activation과 Global Residual Normalization (GRN)을 통해 추가적으로 normalize 되고, $1\times 1$ convolution을 통해 input level로 dimensionally reduce 됨
- ConvNeXt v2 block의 output은 residual connection을 통해 input과 integrate 되어 subsequent layer로 전달됨
- 한편으로 ConvNeXt v2 network에서 처리된 feature는 downsampling을 위해 output convolution layer와 large-stride convolution layer로 전달됨
- 결과적으로 두 branch의 output을 concatenating 한 다음, dimension-reducing convolution을 사용하여 amplitude와 phase information이 integrate 된 long-frame-shift, low-dimensional feature를 얻음 - Waveform generation module에서는
- 먼저 dimension-expanding convolution layer를 사용하여 low-dimensional feature space를 expand 하고, amplitude와 phase branch를 분리함
- 각 branch에서 input은 input convolution layer와 upsampling을 위한 deconvolution layer를 통과함
- 이때, feature extraction module과 마찬가지로 ConvNeXt v2 block을 backbone으로 사용
- 최종적으로 amplitude spectrum은 output convolution layer로 얻어지고, phase spectrum prediction을 위해 parallel specturm estimation architecture를 채택함

- Training Criteria
- BiVocoder는 GAN training strategy를 채택하고 hinge GAN loss를 활용함
- TTS Application
- TTS task에서 text/phoneme sequence는 먼저 acoustic model을 거친 다음 BiVocoder를 통해 예측됨
- 이때 BiVocoder의 waveform generation module은 input predicted feature로부터 speech waveform을 합성함
- Acoustic model의 training phase에서 BiVocoder의 feature extraction module은 acoustic model에 대한 training target을 제공함
3. Experiments
- Settings
- Dataset : VCTK, LJSpeech
- Comparisons : STRAIGHT, HiFi-GAN, APNet, AutoVocoder
- Results
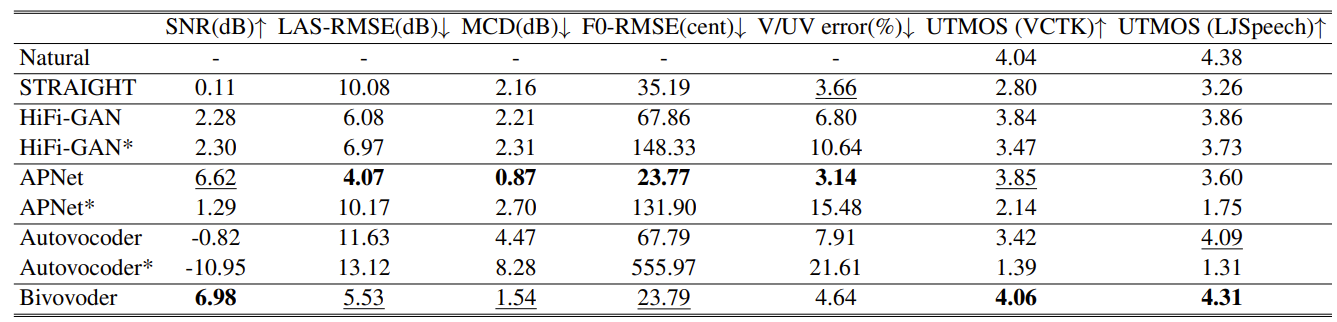
- BiVocoder는 기존의 bidirectional vocoder인 AutoVocoder, STRAIGHT보다 뛰어난 성능을 달성함
- Unidirectional vocoder인 APNet과 비교하여 BiVocoder는 LAS-RMSE, MCD 같은 amplitude-related metric에서 우수한 성능을 보임
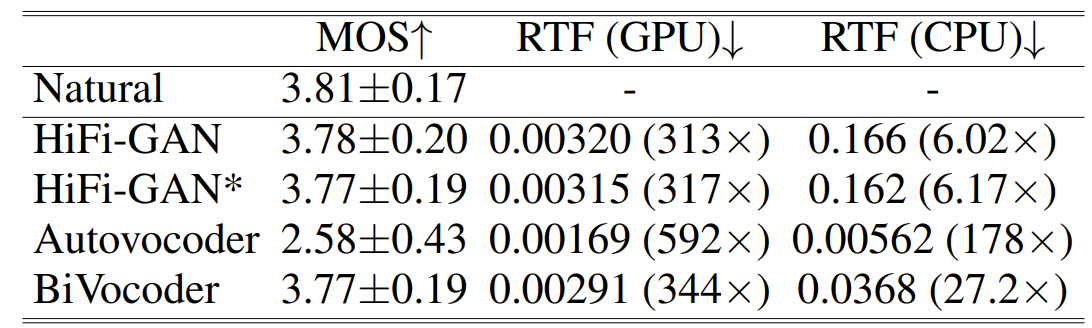
- DiffGAN-TTS 모델을 기반으로 TTS 작업에 각 vocoder를 적용해 보면, BiVocoder는 우수한 MOS 품질을 달성하면서도 빠른 RTF 속도를 보임
- 추가적으로 generalization 측면에서도 BiVocoder는 각 dataset에서 가장 높은 UTMOS를 달성함
반응형
'Paper > Vocoder' 카테고리의 다른 글
댓글