

티스토리 뷰
Paper/TTS
[Paper 리뷰] M2-CTTS: End-to-End Multi-Scale Multi-Modal Conversational Text-to-Speech Synthesis
feVeRin 2024. 5. 10. 09:55반응형
M2-CTTS: End-to-End Multi-Scale Multi-Modal Conversational Text-to-Speech Synthesis
- Conversational text-to-speech는 historical conversation을 기반으로 적절한 prosody를 가진 음성을 합성하는 것을 목표로 함
- BUT, 기존 방식들은 대부분 global information 추출에만 초점을 맞추고 있으므로 keyword나 emphasis 같은 fine-grained information이 포함된 local prosody feature가 생략됨
- M2-CTTS
- Historical conversation을 종합적으로 활용하고 prosodic expression을 향상하는 end-to-end multi-scale, multi-modal conversational text-to-speech 모델
- 이를 위해 fine-grained, coarse-grained modeling을 모두 활용하는 text context module과 acoustic context module을 설계
- 논문 (ICASSP 2023) : Paper Link
1. Introduction
- Conversational Text-to-Speech (TTS)는 history conversation에 따라 적절한 prosody로 음성을 합성하는 것을 목표로 함
- 이때 conversational TTS는 historical conversation에 크게 의존하므로 해당 dialogue information을 효과적으로 모델링하는 것이 중요함
- 기존에는 text 측면에서 history context를 반영하기 위해 context encoder를 도입하거나 previous speech에서 acoustic embedding을 추출하는 acoustic encoder를 사용하는 방법들이 제시되었음 - BUT, 해당 conversational TTS 모델들은 주로 single modality 내에서 global level의 prosody embedding을 예측하는 것에만 초점을 둠
- 즉, 다양한 local feature를 고려하지 않으므로 keyword emphasis나 prosody 변화와 같은 human behavior를 제대로 반영하지 못함
- 특히 모델링 과정에서 단순한 concatenation이나 GRU를 사용하는 경우, current/past utterance 간의 관계를 설명하는 능력이 크게 저하될 수 있음
- 이때 conversational TTS는 historical conversation에 크게 의존하므로 해당 dialogue information을 효과적으로 모델링하는 것이 중요함
-> 그래서 text와 acoustic 측면 모두에서 utterance-/phoneme-level을 모두 반영할 수 있는 M2-CTTS를 제안
- M2-CTTS
- Utterance-/phoneme-level module을 포함하는 hierarchical modeling method를 도입
- Multi-head cross-modal attention mechanism을 채택하여 utterance 간의 connection을 강화
- 더 나은 prosody를 얻기 위해 Style-Adaptive Layer Normalization (SALN)을 활용
< Overall of M2-CTTS >
- Global feature 추출 외에도 local information을 사용하여 expressiveness를 향상
- Textual/acoustic conversation information을 모두 활용하고 SALN과 prosody predictor module을 도입하여 prosody embedding을 효과적으로 반영
- 결과적으로 기존보다 우수한 합성 품질을 달성
2. Method
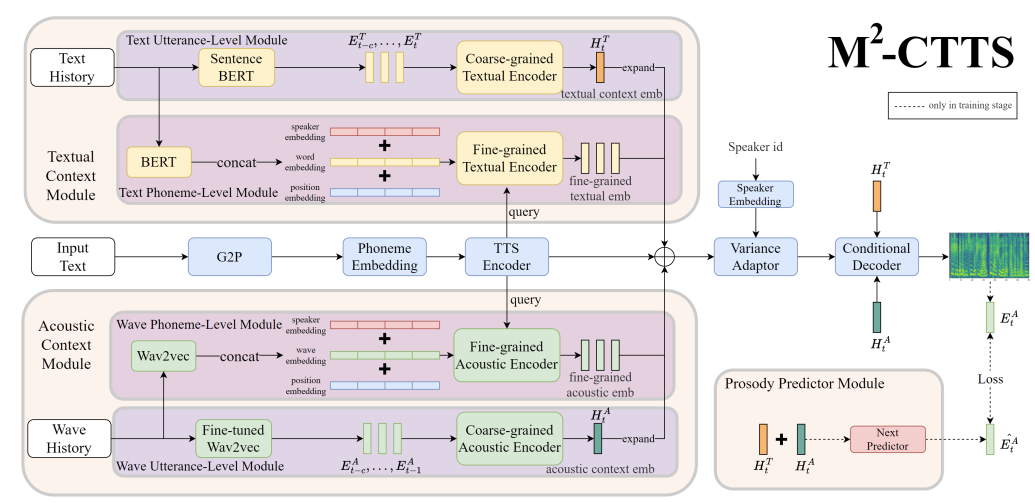
- M2-CTTS는 encoder, decoder, variance adaptor로 구성된 FastSpeech2를 기반으로 함
- 여기서 history conversation에서 text와 acoustic information을 모두 capture 하기 위해 Text Context Module (TCM), Acoustic Context Module (ACM)을 도입
- Hierarchical history context를 반영하기 위해 Text Utterance-level Module (TCM), Text Phoneme-level Moduel (TPM)을 적용하고 Wave Utterance-level Module (WUM), Wave Phoneme-level Module (WPM)을 사용
- 추가적으로 생성된 음성의 expressiveness를 향상하기 위해 conditional decoder와 Prosody Predictor Module (PPM)을 채택
- 이때 history context를 효과적으로 활용하기 위해 conditional decoder로써 Style-Adaptive Layer Normalization (SALN)을 적용
- Multi-scale Dialogue Modeling
- Emotion이나 intention 같은 global information을 통해 모델은 conversation을 이해할 수 있지만, 효과적인 conversational TTS를 위해서는 implicit meaning을 포함하는 detailed information을 강조할 수 있어야 함
- 특히 utterance에서 incosistent 하거나 mixed style은 unnatureal prosody로 이어질 수 있음
- 이때 경험적으로 fixed-length conversation embedding이 제대로 반영되지 않는 경우, average prosody로 나타남 - 따라서 M2-CTTS에서는 fine-grained와 coarse-grained conversational modeling을 결합하고, multi-head attention을 통해 comprehensive history information을 얻음
- 그러면 $t$ time stamp에서의 conversation history를 다음과 같이 나타낼 수 있음:
(Eq. 1) $\text{Conversation}=\{A_{t-c},B_{t-c+1},...,A_{t-1},B_{t}\}$
- $c$ : 두 speaker $A, B$ 사이의 turn을 결정하는 memory capacity parameter
- 특히 utterance에서 incosistent 하거나 mixed style은 unnatureal prosody로 이어질 수 있음
- Coarse-grained Context Modeling
- Coarse-grained context modeling 측면에서 M2-CTTS는 Text Utterance-level Module (TUM)과 Wave Utterance-level Module (WUM)을 사용하여 global context information을 얻음
- 먼저 TUM은 Sentence BERT-based textual utterance-level feature extractor와 coarse-grained textual encoder로 구성되어 textual utternace-level information을 모델링함
- 여기서 Sentence BERT는 semantic information을 capture 하고, 마지막 $c$ turn의 dialogue와 current utterance embedding $E_{t}^{T}$가 포함된 $\text{Conversation}$에서 history sentence embedding $E_{t-c:t-1}^{T}$를 추출함
- Coarse-grained textual encoder에서 GRU layer는 cumulative past conversational information을 고려하기 위해 history embedding $E_{t-c:t-1}^{T}$를 encoding 하는 데 사용됨
- 이후 GRU의 final hidden state를 current utterance embedding $E_{t}^{T}$와 concatenate 하고, 이를 additional attention mechansim을 통해 linear layer에 전달하여 weighted global textual context embedding $H_{t}^{T}$를 얻음
- WUM은 global acoustic context embedding $H_{t}^{A}$를 추출하기 위해, 유사한 architecture를 활용함
- 이때 feature extractor를 제외하고 current utterance $B_{t}$의 음성은 사용하지 않음
- 기존의 Global Style Token (GST) 대신, downstream speech emotion recognition task에 대해 fine-tuning 된 wav2vec 2.0을 채택하여 raw audio로부터 직접적으로 utterance-level prosody information $E_{i}^{A}$를 추출
- 해당 방식은 다음의 2가지 이점을 제공함
- Pre-trained model은 spectral-based feature와 달리 comprehensive 한 acoustic feature를 capture 가능
- Pre-trained model을 통해 training difficulty를 완화하고 robust 한 성능을 얻을 수 있음
- Fine-grained Context Modeling
- Coarse-grained context modeling을 통해 전체 utterance의 connection에 대한 information을 capture 할 수 있지만, 모든 phoneme에 동일한 prosodic embedding을 사용하는 것은 unnatural 함
- Real-world conversation에서는 communication 과정에서 특정 word나 phrase를 강조하기 때문 - 따라서 이를 반영하기 위해 fine-grained history information을 모델링하는 Text Phoneme-level Module (TPM)과 Wave Phoneme-level Module (WPM)을 도입
- TPM과 WPM에서 $i$-th sentence나 utterance의 hidden feature sequence $P_{i}$는 각각 BERT와 wav2vec 2.0을 통해 얻어짐
- 이후 multi-head cross-attention mechanism을 활용하여 context understanding과 expressiveness에 영향을 미치는 essential phrase나 frame을 identify 함
- Coarse-grained context modeling을 통해 전체 utterance의 connection에 대한 information을 capture 할 수 있지만, 모든 phoneme에 동일한 prosodic embedding을 사용하는 것은 unnatural 함
- Multi-modal Context Modeling
- Semantic, syntactic feature 외에도 acoustic, prosodic cue와 같은 paralinguistic information도 context understanding에 중요한 역할을 함
- Real-world에서는 동일한 content나 situation에서도 서로 다른 tone으로 speak 하기 때문에, TTS 모델 역시 모든 modality를 모델링할 수 있어야 함
- Textual Context Modeling
- Textual Context Module에는 TPM과 TUM이 포함되고, TPM은 feature extractor와 fine-grained texutal encoder로 구성됨
- 이를 위해 $i$-th sentence에서 hidden feature sequence $P_{i}$를 얻고 모든 last $c$ dialogue를 long sequence로 aggregate 하기 위해 BERT를 채택하고,
- 이후 speaker ID를 추가하여 speaker identitiy를 reserve 하고 sinusoidal position을 통해 conversation order를 나타냄 - Fine-grained textual encoder에서는 contextualization을 위해 1D convolutional layer를 사용함
- 그런 다음 TTS encoder의 output은 historical fine-grained representation sequence를 key와 value로 사용하는 multi-head cross-attention에 대한 query로 사용됨 - 결과적으로 weighted context representation은 residual design과 함께 TTS encoder의 output에 추가됨
- 이를 통해 text 측면에서 중요한 keyword나 phrase를 고려할 수 있음
- Textual Context Module에는 TPM과 TUM이 포함되고, TPM은 feature extractor와 fine-grained texutal encoder로 구성됨
- Acoustic Context Modeling
- Acoustic Context Module에는 WPM과 WUM이 포함되고 WPM은 feature extractor와 fine-grained acoustic encoder로 구성됨
- 이때 mel-spectrogram을 acoustic input으로 사용하지 않고 wav2vec 2.0을 채택하여 raw audio로부터 hidden feature sequence를 추출함
- 이를 통해 acoustic 측면에서 local expression을 강조할 수 있음
- Constraint of Prosody
- Multi-modal global context embedding $H_{t}^{T}$와 $H_{t}^{A}$에서 current utterance $E_{t}^{A}$의 prosody embedding을 예측하기 위해 Prosody Predictor Module (PPM)을 도입
- 이때 history를 기반으로 current utterance의 prosody expression을 예측하기 위해 coarse-grained context module을 constraint 하는 additional MSE loss가 사용됨:
(Eq. 2) $\hat{E}_{t}^{A}=\text{PPM}(H_{t}^{T},H_{t}^{A}),\,\,\, \text{Loss}=||\hat{E}_{t}^{A},E_{t}^{A}||$
- $\hat{E}_{t}^{A}$ : 예측된 prosody embedding
- $E_{t}^{A}$ : fine-tuned wav2vec을 통해 추출된 ground-truth prosody embedding - 해당 PPM과 loss 계산은 training 중에만 사용됨
- 이때 history를 기반으로 current utterance의 prosody expression을 예측하기 위해 coarse-grained context module을 constraint 하는 additional MSE loss가 사용됨:
3. Experiments
- Settings
- Dataset : DailyTalk
- Comparisons
- M1 : FastSpeech2
- M2~M7 : 아래 표 참고

- Results
- MOS 측면에서 모든 component를 적용한 M7 (M2-CTTS)가 가장 높은 품질을 보임
- 특히 TUM이나 WUM을 사용하여 text/acoustic 측면에서 utterance-level의 dialogue history를 모델링하면 expressiveness가 향상되는 것으로 나타남

반응형
'Paper > TTS' 카테고리의 다른 글
댓글