

티스토리 뷰
Paper/TTS
[Paper 리뷰] STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech
feVeRin 2024. 1. 31. 13:02반응형
STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech
- Text-to-Speech는 어려운 합성 condition에 대한 robustness와 expressiveness, controllability를 요구함
- STYLER
- Mel-Calibrator를 통한 audio-text aligning을 도입하여 unseen data에 대한 robust 한 추론을 가능하게 함
- Supervision 하에서 disentangled style factor modeling을 통해 controllability를 향상
- Domain adversarial training, Residual decoding을 활용하여 noise-robust style transfer를 지원하고 additional label 없이 noise를 decompose
- 논문 (INTERSPEECH 2021) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 많은 발전이 있었지만 여전히 expressiveness와 controllability가 부족함
- 합성된 음성의 style은 training data에 대한 평균적인 style로 결정되므로 TTS의 expressiveness가 제한됨
- BUT, 이를 해결하기 위한 expressive TTS 모델은 autoregressive architecture로 인해 속도와 robustness의 한계가 존재
- 각 frame은 예측을 위해 이전의 모든 time step을 반복해야 하기 때문에 상당한 overhead가 발생
- Unsupervised style modeling은 학습이 어렵고 feature를 disentangle 하기 어려움 - Non-autoregressive 방식은 이러한 문제를 해결할 수 있음
- Autoregressive decoder를 supervision이 있는 duration predictor로 대체하면 stability가 향상되고 속도도 빨라짐
- BUT, 이러한 방식도 single text가 아닌 input에 대한 expressiveness와 contorllability는 부족함 - 결과적으로 TTS 모델에서 속도와 robustness, expressiveness, controllability를 모두 만족하기 위해서는,
- 속도와 robustness에 약점이 있는 autoregressive architecture를 대체해야 함
- Expressiveness, controllability를 위해 style factor modeling이 필요함
- Single text 외의 input variation을 제공
- 속도와 robustness에 약점이 있는 autoregressive architecture를 대체해야 함
-> 그래서 빠르고 robust 하면서 expressive, controllable 한 TTS를 지원하는 STYLER를 제안
- STYLER
- Non-autoregressive decoding시 각 style factor를 control 하는 style factor modeling을 도입
- Source audio를 text input 외에도 duration, pitch, energy, content, noise의 5개 component로 split
- 각 style factor를 개별적으로 encoding 한 다음, 음성으로 decoding - Noise modeling은 label 없이 reference의 noise를 decompose
< Overall of STYLER >
- Audio-text aligning을 통해 unseen data에서 더 빠르고 robust 한 합성이 가능
- Disentangled style factor를 통해 높은 expressivity와 controllability를 달성
- Noise modeling pipeline을 통해 additional label 없이 noise를 style factor로 decompose 가능
2. Method
- Supervised Speech Decomposition
- STYLER는 Style factor modeling과 Non-autoregressive TTS, 2가지에 대해 고려
- Voice conversion과 달리 output speech의 content는 text이므로 audio content와 match 되지 않을 수 있음
- 최신 non-autoregressive 모델은 supervision을 활용할 수 있지만, speech decomposition은 unsupervised condition에서 수행됨
- 결과적으로 이를 위해 STYLER는 Mel Calibrator를 도입하고 supervision 하에서의 speech decomposition을 수행
- Mel Calibrator
- Text와 audio의 length mismatch는 attention mechanism을 통해 해결될 수 있음
- BUT, unseen data에 대해서는 unstable 하다는 단점이 있음 - 따라서 unseen data에 대한 robustness를 향상하기 위해 Mel Calibrator를 도입
- Mel Calibrator는 input text와 audio의 total length를 사용하여 frame의 평균을 구하거나 frame을 반복하여,
- Audio frame length에 대한 phoneme sequence size의 raito를 기준으로 single phoneme에 할당 - 이러한 scaling 과정에서 aligning process는 frame-wise bottleneck이 되므로 attention이나 forced alignment의 사용이 필요 없음
- 결과적으로 Mel Calibrator를 사용하면 non-autoregressive에 대한 robustness 문제를 해결하고, audio-related style이 text에 expose 되지 않음
- Text와 audio의 length mismatch는 attention mechanism을 통해 해결될 수 있음
- Information Bottleneck under Supervision
- Unsupervised speech decomposition은 source audio에서 필요한 information을 전달하기 위해 channel-wise, frame-wise 모두에 대한 bottleneck을 필요로 함
- 결과적으로 TTS 모델의 학습을 어렵고 time-consuming 하게 만듦 - Supervision 하에서 decomposition을 적용하면 pitch contour나 energy 같은 pre-obtained feature를 활용할 수 있음
- 이때 forced feature selection을 통한 과도한 regularization은 information shortage와 성능 저하를 발생시킴
- 따라서, STYLER는 style factor modeling 중 supervision에 대한 information flow에 맞게 bottleneck을 적절하게 mitigate 함
- Unsupervised speech decomposition은 source audio에서 필요한 information을 전달하기 위해 channel-wise, frame-wise 모두에 대한 bottleneck을 필요로 함
- Model Architecture
- STYLER는 text $Z_{t}$, duration $Z_{d}$, pitch $Z_{p}$, speaker $Z_{s}$, energy $Z_{e}$, noise $Z_{n}$ 6가지의 style factor를 활용함
- Text는 다른 audio-related factor와 동일한 style factor로 취급하고,
- Non-autoregressive TTS와 speech decomposition approach를 도입
- Encoders
- Text encoder는 2개의 Feed-Forward Transformer (FFT) block으로 구성
- Phoneme sequence로 input text를 사용
- 이때 text는 text encoder에 의해서만 encoding 되므로 audio content는 다른 encoder의 bottleneck을 통해 제거됨 - Duration, pitch, energy, noise encoder는 group normalization이 포함된 3개의 $5 \times 1$ convolution layer, 2개의 bidirectional LSTM을 통한 bottleneck으로 구성
- Mel Calibrator는 convolution stack 다음에 추가됨
- Encoder output은 linear layer로 예측하기 전에 ReLU activation을 통하여 channel-wise upsample 되고 duration predictor의 경우, frame-wise upsampling이 적용됨 - Duration, noise encoder는 mel-spectrogram을 input으로 사용하고, pitch encoder는 speaker normalized pitch contour (mean = 0.5, std = 0.25)를 사용
- Energy encoder는 0에서 1로 scale 된 energy를 사용 - Speaker encoding은 pre-trained speaker embedding으로부터 얻어짐
- 이를 위해 DeepSpeaker 모델을 활용
- Text encoder는 2개의 Feed-Forward Transformer (FFT) block으로 구성
- Decoders
- STYLER에는 duration, pitch, energy에 대한 3개의 predictor가 존재
- Predictor는 latent code가 아닌 real value를 예측하므로 모든 information을 사용해야 함
- 이를 위해 input에는 해당하는 encoding과 text encoding의 합이 포함되고, 이때 text encoding은 dependency를 맞추기 위해 4차원 공간으로 projection 됨 - Pitch predictor는 최종적인 pitch contour를 예측하기 위해 speaker encoding을 추가적으로 사용
- 이때 downsampled / upsampled pitch encoding 모두에 speaker encoding을 추가하면 speaker identity decomposition 성능이 향상됨 - Disentangled style factor로부터 최종적인 mel-spectrogram을 예측하는 decoder는 4개의 FFT block으로 구성됨
- 해당 decoder의 input은 text encoding, pitch predictor ouptut, energy predictor output, speaker encoding으로 구성
- STYLER에는 duration, pitch, energy에 대한 3개의 predictor가 존재

- Noise Modeling
- STYLER의 noise robustness를 향상하기 위해 additional label 없이 audio에서 noise를 decompose 할 수 있음
- STYLER에서 noise는 모델 encoder에서 explicitly encoding 된 remaining factor 중 하나이고, 다른 style factor를 제외한 residual property를 기반으로 정의할 수 있음
- 이에 따라 noise를 modeling 하기 위해서는, 다른 encoder가 noisy input에 대해서 noise information을 포함하지 않도록 해야 함
- Domain Adversarial Training
- Noise information을 포함하지 않는다는 것은 noise-independent feature를 추출한다는 것과 동일함
- 이를 위해 Domain Adversarial Training (DAT)를 활용할 수 있음 - 따라서 STYLER는 jointly trainable 한 augmentation label과 Gradient Reversal Layer (GRL)을 도입
- 이때 각 predictor의 label은 class label의 역할을 수행
- Noise encoder를 제외한 모든 audio-related encoding에는 DAT가 적용됨
- GRL을 통과한 각 encoding은 augmentation classifier를 통해 augmentation posterior (original / augmented)를 예측하는 데 사용됨 - Augmentation classifier는 256 hidden size의 2개의 fully-connected layer로 구성되고, layer noramlization, ReLU activation이 사용됨
- Noise encoder를 제외한 각 encoder는 noise-independent 하므로 clean label과 비교됨
- Noise information을 포함하지 않는다는 것은 noise-independent feature를 추출한다는 것과 동일함
- Residual Decoding
- Residual decoding은 clean decoding, noisy decoding 두 phase로 구성됨
- Clean decoding은:
모든 noise-independent encoding을 사용하여 clean mel-spectrogram을 예측 - Noisy decoding은:
Noise encoder output을 noise-independent encoding에 추가하여 noise가 있는 mel-spectrogram을 예측
- Clean decoding은:
- Noisy decoding에서는 noise encoder만 업데이트하면 되기 때문에, gradient가 다른 encoder를 통해 흐르지 않음
- 결과적으로 residual decoding은 explicit label 없이 audio의 leftover part에 noise가 집중되도록 하는 implicit supervision으로 볼 수 있음
- Residual decoding은 clean decoding, noisy decoding 두 phase로 구성됨
- Loss Calculation
- Noise modeling이 없는 모델의 total loss는:
$Loss_{clean} = l_{mel-clean} + l_{duration} + l_{pitch} + l_{energy}$
- $l_{mel-clean}$ : 예측된 mel-spectrogram과 target 사이의 mean squared error
- $l_{duration}, l_{pitch}, l_{energy}$ : FastSpeech2와 동일한 predictor loss - Noise modeling을 포함한 모델의 total loss는:
$Loss_{total} = Loss_{clean} + l_{mel-noisy} + l_{aug}$
- $l_{mel-noisy}$ : $l_{mel-clean}$과 동일하게 계산된 noisy decoding 값
- $l_{aug}$ : augmentation classifier loss
3. Experiments
- Settings
- Dataset : VCTK, WHAM!
- Comparisons : FastSpeech2, Mellotron
- Results
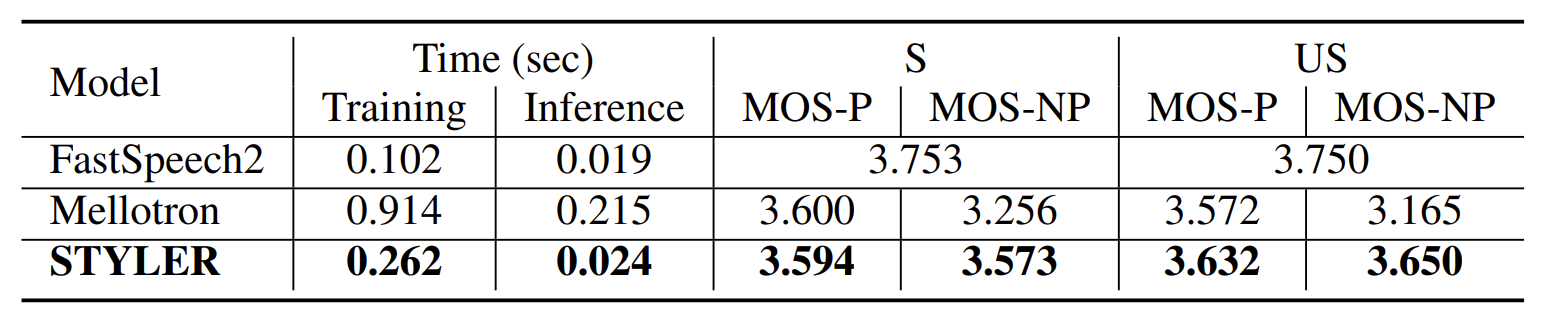
- Rapidity and Naturalness
- STYLER는 style factor modeling으로 인해 FastSpeech2에 비해서는 다소 느린 속도를 보였지만, Mellotron에 비해 3.49배의 학습 속도와 8.96배의 추론 속도 향상을 보임
- MOS 측면에서 STYLER는 Unseen (US), Non-parallel (NP) condition에서 비교 모델들보다 더 나은 naturalness를 보임
- Style Transfer
- STYLER는 CMOS 측면에서도 FastSpeech2, Mellotron 보다 더 나은 expressiveness를 보임
- 특히 STYLER는 Unseen (US), Non-Parallel (NP) 환경에서 성능이 크게 저하되지 않아 robust 함

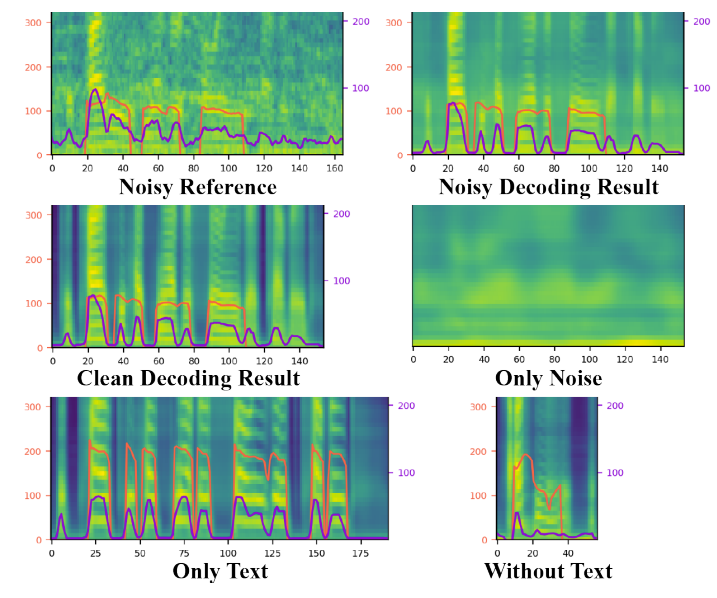
- Style Factor Modeling
- 합성된 audio의 mel-spectrogram을 비교해 보면, STYLER는 noisy reference audio에서도 clean audio를 생성할 수 있음
- 특히 noise modeling의 경우 input audio에 대한 다양한 noise level을 예측하는 것으로 나타남
- Noise-independent style이 무시되면 해당하는 encoding은 fixed style로 나타남
- Text encoder가 비활성 되면, audio-related style factor는 올바르게 사용되어도 unintelligible한 음성을 합성함 - 결과적으로 STYLER에 사용된 noise modeling은 reference audio의 noise를 decompose 함
반응형
'Paper > TTS' 카테고리의 다른 글
댓글