

 [Paper 리뷰] Mixer-TTS: Non-autoregressive, Fast and Compact Text-to-Speech Model Conditioned on Language Model Embeddings
[Paper 리뷰] Mixer-TTS: Non-autoregressive, Fast and Compact Text-to-Speech Model Conditioned on Language Model Embeddings
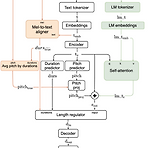
Mixer-TTS: Non-autoregressive, Fast and Compact Text-to-Speech Model Conditioned on Language Model EmbeddingsMel-spectrogram generation에서는 non-autoregressive 모델이 유용함Mixer-TTSMLP-Mixer architecture를 기반으로 pitch/duration predictor를 활용Pre-trained language model의 token embedding을 추가적으로 도입하여 Mixer-TTS를 extend논문 (ICASSP 2022) : Paper Link1. IntroductionText-to-Speech (TTS)에서는 속도 향상을 위해서는 non-autoregres..
 [Paper 리뷰] Meta-StyleSpeech: Multi-Speaker Adaptive Text-to-Speech Generation
[Paper 리뷰] Meta-StyleSpeech: Multi-Speaker Adaptive Text-to-Speech Generation
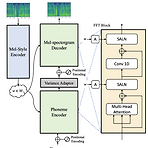
Meta-StyleSpeech: Multi-Speaker Adaptive Text-to-Speech Generation Text-to-Speech 모델은 주어진 speaker에서 나온 few audio sample 만을 사용하여 고품질 음성을 합성할 수 있어야 함 StyleSpeech 고품질 합성이 가능하고 새로운 speaker에 대해 효과적으로 adaptaion 하는 TTS 모델 Reference에서 추출된 style에 따라 text input의 gain과 bias를 align 하는 Style-Adaptive Layer Normalization을 도입 Meta-StyleSpeech 새로운 speaker에 대한 StyleSpeech의 adaptation을 향상하기 위해 style prototype으로 학..
 [Paper 리뷰] FedSpeech: Federated Text-to-Speech with Continual Learning
[Paper 리뷰] FedSpeech: Federated Text-to-Speech with Continual Learning
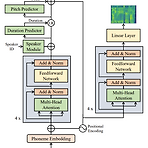
FedSpeech: Federated Text-to-Speech with Continual Learning Federated text-to-speech는 여러 사용자의 음성을 device에 locally store 된 few audio sample과 합성하는 것을 목표로 함 Federated text-to-speech는 각 speaker에 대한 training sample이 거의 없고, sample이 각 local device에만 store 되어 있고, global model이 다양한 공격에 취약하다는 어려움이 있음 FedSpeech Gradual pruning mask를 사용하여 speaker tone을 preserving 하기 위해 parameter를 isolate 함 Task에서 얻은 knowled..
 [Paper 리뷰] ProsoSpeech: Enhancing Prosody with Quantized Vector Pre-training in Text-to-Speech
[Paper 리뷰] ProsoSpeech: Enhancing Prosody with Quantized Vector Pre-training in Text-to-Speech
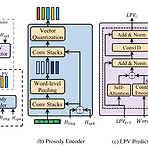
ProsoSpeech: Enhancing Prosody with Quantized Vector Pre-training in Text-to-Speech Text-to-Speech에서 prosody 모델링을 위해서는 몇 가지 어려움이 있음 - 추출된 pitch에는 inevitable error가 포함되어 있어 prosody 모델링을 저해함 - Pitch, duration, energy와 같은 prosody의 다양한 특성은 서로 dependent 함 - Prosody의 high variability로 인해 prosody 분포를 fully shape 하기 어려움 ProsoSpeech Low-quality text와 speech data에 대해 pre-train 된 quantized latent vector를 도..
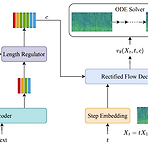 [Paper 리뷰] ReFlow-TTS: A Rectified Flow Model for High-Fidelity Text-to-Speech
[Paper 리뷰] ReFlow-TTS: A Rectified Flow Model for High-Fidelity Text-to-Speech
ReFlow-TTS: A Rectified Flow Model for High-Fidelity Text-to-SpeechDiffusion model이 음성 합성에서 우수한 성능을 보이고 있지만, 고품질 음성 합성을 위해서는 여전히 많은 sampling step이 필요함 ReFlow-TTSRectified Flow를 활용한 Text-to-Speech 모델Gaussian 분포를 straight line을 통해 ground-truth mel-spectrogram 분포로 transport 하는 Ordinary Differential Equation을 활용논문 (ICASSP 2024) : Paper Link1. IntroductionText-to-Speech (TTS)는 acoustic model과 vocoder..
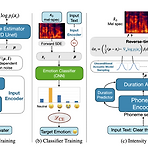 [Paper 리뷰] EmoDiff: Intensity Controllable Emotional Text-to-Speech with Soft-Label Guidance
[Paper 리뷰] EmoDiff: Intensity Controllable Emotional Text-to-Speech with Soft-Label Guidance
EmoDiff: Intensity Controllable Emotional Text-to-Speech with Soft-Label Guidance 최신 Text-to-Speech 모델들은 고품질 음성을 합성할 수 있지만, emotion에 대한 intensity controllability는 떨어짐 - Intensity 계산을 위한 external optimization이 필요하기 때문 EmoDiff Classifier guidance에서 파생된 soft-label guidance를 diffusion 기반 text-to-speech 모델에 적용 Specified emotion과 Neutral을 emotion intensity $\alpha, 1-\alpha$로 나타내는 soft-label을 활용 논문 (I..