

 [Paper 리뷰] EmoDiff: Intensity Controllable Emotional Text-to-Speech with Soft-Label Guidance
[Paper 리뷰] EmoDiff: Intensity Controllable Emotional Text-to-Speech with Soft-Label Guidance
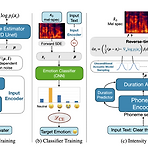
EmoDiff: Intensity Controllable Emotional Text-to-Speech with Soft-Label Guidance 최신 Text-to-Speech 모델들은 고품질 음성을 합성할 수 있지만, emotion에 대한 intensity controllability는 떨어짐 - Intensity 계산을 위한 external optimization이 필요하기 때문 EmoDiff Classifier guidance에서 파생된 soft-label guidance를 diffusion 기반 text-to-speech 모델에 적용 Specified emotion과 Neutral을 emotion intensity $\alpha, 1-\alpha$로 나타내는 soft-label을 활용 논문 (I..
 [Paper 리뷰] EfficientTTS: An Efficient and High-Quality Text-to-Speech Architecture
[Paper 리뷰] EfficientTTS: An Efficient and High-Quality Text-to-Speech Architecture
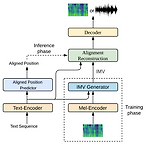
EfficientTTS: An Efficient and High-Quality Text-to-Speech Architecture Text-to-Speech를 위해 non-autoregressive architecture는 많은 이점을 가지고 있음 EfficientTTS External aligner를 필요로 하는 autoregressive 모델과 달리, 안정적인 end-to-end 학습을 지원하여 효율적이면서 고품질의 음성 합성이 가능 연산량을 증가시키지 않고, sequence alignment에 monotonic constraint를 반영할 수 있는 monotonic alignment modeling을 제시 EfficientTTS를 다양한 feed-forward network 구조와 결합하여 Text-..
 [Paper 리뷰] Grad-StyleSpeech: Any-Speaker Adaptive Text-to-Speech Synthesis with Diffusion Models
[Paper 리뷰] Grad-StyleSpeech: Any-Speaker Adaptive Text-to-Speech Synthesis with Diffusion Models
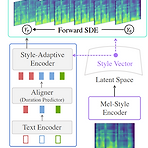
Grad-StyleSpeech: Any-Speaker Adaptive Text-to-Speech Synthesis with Diffusion Models Any-speaker adaptive Text-to-Speech 작업은 여전히 target speaker의 style을 모방하기에 만족스럽지 못함 Grad-StyleSpeech Diffusion model을 기반으로 하는 any-speaker adaptive Text-to-Speech model Few-second reference speech가 주어지면 target speaker와 유사한 음성을 생성하는 것을 목표로 함 논문 (ICASSP 2023) : Paper Link 1. Introduction Text-to-Speech (TTS)는 single..
 [Paper 리뷰] Flow-TTS: A Non-Autoregressive Network for Text to Speech Based on Flow
[Paper 리뷰] Flow-TTS: A Non-Autoregressive Network for Text to Speech Based on Flow
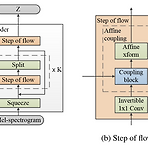
Flow-TTS: A Non-Autoregressive Network for Text to Speech Based on Flow Non-autoregressive Text-to-Speech를 위해 generative flow를 활용할 수 있음 Flow-TTS Single feed-forward network 만을 사용하여 고품질의 음성을 합성 Spectrum 생성을 위해 flow를 활용하고 single network를 통해 alignment와 spectrogram 생성을 jointly learn 논문 (ICASSP 2020) : Paper Link 1. Introduction Text-to-Speech (TTS)는 input text sequence $\{ x_{1}, x_{2}, ..., x_{N}\}..
 [Paper 리뷰] YourTTS: Toward Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for Everyone
[Paper 리뷰] YourTTS: Toward Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for Everyone
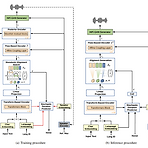
YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for Everyone Zero-Shot multi-speaker Text-to-Speech를 위해 multilingual approach가 필요 YourTTS VITS를 기반으로 multi-speaker, multilingual task로 확장 Low-resource zero-shot 환경에서 우수한 합성 품질을 달성하고 1분 미만으로 fine-tuning이 가능 논문 (ICML 2022) : Paper Link 1. Introduction 대부분의 Text-to-Speech (TTS) 모델은 single speaker의 음성에만 특화되어 있음 이때 Zero-Shot ..
 [Paper 리뷰] STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech
[Paper 리뷰] STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech
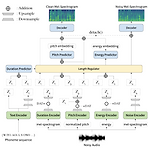
STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech Text-to-Speech는 어려운 합성 condition에 대한 robustness와 expressiveness, controllability를 요구함 STYLER Mel-Calibrator를 통한 audio-text aligning을 도입하여 unseen data에 대한 robust 한 추론을 가능하게 함 Supervision 하에서 disentangled style factor modeling을 통해 controllability를 향상 Domain adve..