

티스토리 뷰
Paper/TTS
[Paper 리뷰] FedSpeech: Federated Text-to-Speech with Continual Learning
feVeRin 2024. 2. 22. 11:21반응형
FedSpeech: Federated Text-to-Speech with Continual Learning
- Federated text-to-speech는 여러 사용자의 음성을 device에 locally store 된 few audio sample과 합성하는 것을 목표로 함
- Federated text-to-speech는 각 speaker에 대한 training sample이 거의 없고, sample이 각 local device에만 store 되어 있고, global model이 다양한 공격에 취약하다는 어려움이 있음
- FedSpeech
- Gradual pruning mask를 사용하여 speaker tone을 preserving 하기 위해 parameter를 isolate 함
- Task에서 얻은 knowledge를 reusing 하기 위해 selective mask를 활용
- Privacy를 위해 private speaker embedding을 도입
- 논문 (ICASSP 2023) : Paper Link
1. Introduction
- Federated learning은 data island 문제로 인해 최근 많은 관심을 받고 있음
- 특히 federated Text-to-Speech (TTS)는 각 user의 local device에 store 된 few audio sample을 사용하여 multiple user의 음성을 합성하는 것을 목표로 함
- 이때 federated TTS에는 아래와 같은 어려움들이 있음
- Training data의 부족
- Neural TTS 모델은 robustness가 부족하여 training dataset이 적으면 상당한 품질 저하가 발생
- Federated TTS 환경에서는 각 user가 사용할 수 있는 audio sample의 수가 제한되어 있는 경우가 많음 - Data privacy restriciton
- Federated 환경에서 sample은 각 local device에 store 되므로 multi-speaker training이 불가능함
- 특히 일반적인 federated aggregation training 방식은 작은 gradient로도 catastrophic forgetting을 발생시켜 다른 speaker의 tone을 손상시킴
- 결과적으로 federated TTS는 각 speaker의 tone을 유지하는 것이 어려움 - Global model은 다양한 공격에 취약함
- Communicatino architecture는 gradient나 model parameter를 aggregate하여 global model을 training 함
- 이때 local data는 노출되지 않지만, global model은 sensitive information을 유출할 가능성이 높음
- Training data의 부족
- 따라서 일반적인 federated learning 방식으로는 위의 문제를 쉽게 해결할 수 없음
- 이때 continual lifelong learning을 활용하면 catastophic forgetting 문제를 극복할 수 있음
-> 그래서 continual learning을 활용한 federated TTS 모델인 FedSpeech를 제안
- FedSpeech
- Gradual pruning mask를 통해 parameter를 isolate 하여, speaker의 tone을 preserving 함
- Privacy restriction하에서 얻은 knowledge를 효과적으로 reuse 하기 위해 selective mask를 도입
- Additional information을 활용하고 privacy를 보장하기 위해 private speaker embedding을 활용
- Transformer-based TTS model을 기반으로 previous / later task 모두에서 weight를 select 하여 모든 speaker에 대해 equitable 하도록 구성함
< Overall of FedSpeech >
- Selective mask를 통해 제한된 training data로 인한 한계를 극복하고 collaborative training의 장점을 극대화
- Gradual pruning mask는 catastrophic forgetting 문제를 해결하고, 다양한 speaker에 대한 parameter를 isolate 할 수 있음
- 결과적으로 FedSpeech는 모든 speaker에 대한 tone change 문제를 해결할 수 있음 - Privare speaker embedding은 privacy를 보호하고 speaker에 대한 공격을 방지할 수 있음
2. FedSpeech
- FedSpeech architecture는 FastSpeech의 feed-forward transformer를 기반으로 구성됨
- 이후 additional information을 적용하고 user privacy를 보호하기 위해 private speaker embedding을 도입
- Latent space에서 speaker feature를 capture 하고, 추론 시 indispensable sensitive information을 store 하도록 학습
- Private speaker embedding은 각 user device에서 locally preserve 되고, privacy를 위해 다른 user가 접근할 수 없음 - 이때 data 부족과 federated TTS의 privacy 문제를 추가적으로 해결하기 위해, continual learning에서 활용하는 two-round sequential training process를 도입
- 두 종류의 mask와 speaker module을 사용하여 parameter를 isolate 하고, privacy를 보호하면서 다양한 speaker의 knowledge를 효과적으로 reuse 가능
- 이후 additional information을 적용하고 user privacy를 보호하기 위해 private speaker embedding을 도입
- FedSpeech Architecture
- FedSpeech의 architecture를 보면,
- Encoder는 phoneme embedding sequence를 phoneme hidden sequence로 convert 한 다음, duration/pitch와 같은 variance information을 hidden sequence에 추가
- Mel-spectrogram decoder는 adapted hidden sequence를 mel-spectrogram sequence로 convert
- Encoder와 Mel-spectrogram decoder 모두 구조적으로는 FastSpeech의 feed-forward transformer block으로 구성됨
- 이때 feed-forward transformer block은 self-attention layer와 1D convolution feed-forward network를 stack 한 구조 - 추가적으로 FedSpeech는 pitch predictor, duration predictor를 사용
- 각각 ReLU activation이 포함된 2-layer 1D convolution network, layer normalization, dropout, projection layer로 구성
- 학습 시에는 recording에서 추출된 duration과 pitch의 ground-truth value를 hidden sequence에 대한 input으로 사용하여 target speech를 예측
- Encoder는 phoneme embedding sequence를 phoneme hidden sequence로 convert 한 다음, duration/pitch와 같은 variance information을 hidden sequence에 추가

- Speaker Module
- Latent space에서 speaker feature를 추정하여 음성을 제어하고 privacy를 보호하기 위해, private speaker module을 도입
- Trainable lookup table은 speaker identity number $S_{id}$를 input으로 사용하여 speaker representation $R = \{ r_{1}, r_{2}, ..., r_{n} \}$을 생성
- $n$ : 모델의 hidden size - Speaker representation $R$은 tone characteristic을 제어하기 위한 additional key information으로 encoder output에 전달됨
- 이때 각 speaker는 privacy를 고려하여 각자의 module parameter를 training 하므로, 다른 user가 자신의 $S_{id}$를 사용해서 음성을 합성할 수 없음
- Trainable lookup table은 speaker identity number $S_{id}$를 input으로 사용하여 speaker representation $R = \{ r_{1}, r_{2}, ..., r_{n} \}$을 생성
- Two Rounds of Sequential Training
- Catastrophic forgetting으로 인해 federated aggregation training을 사용할 수 없음
- 따라서 continual learning에서 사용하는 sequential training을 채택함
- 이때 previous speaker에 대한 knowledge 만이 current speaker에 의해 사용될 수 있음 - 대신 FedSpeech는 two round sequential training 방식을 제시
- First round에서, 모델은 각 speaker에 대한 weight의 일부를 개별적으로 학습하고 fix 함
- 이후 second round에서, previous / later speaker 모두에 대한 knowledge를 selectively reuse 함
- 따라서 continual learning에서 사용하는 sequential training을 채택함
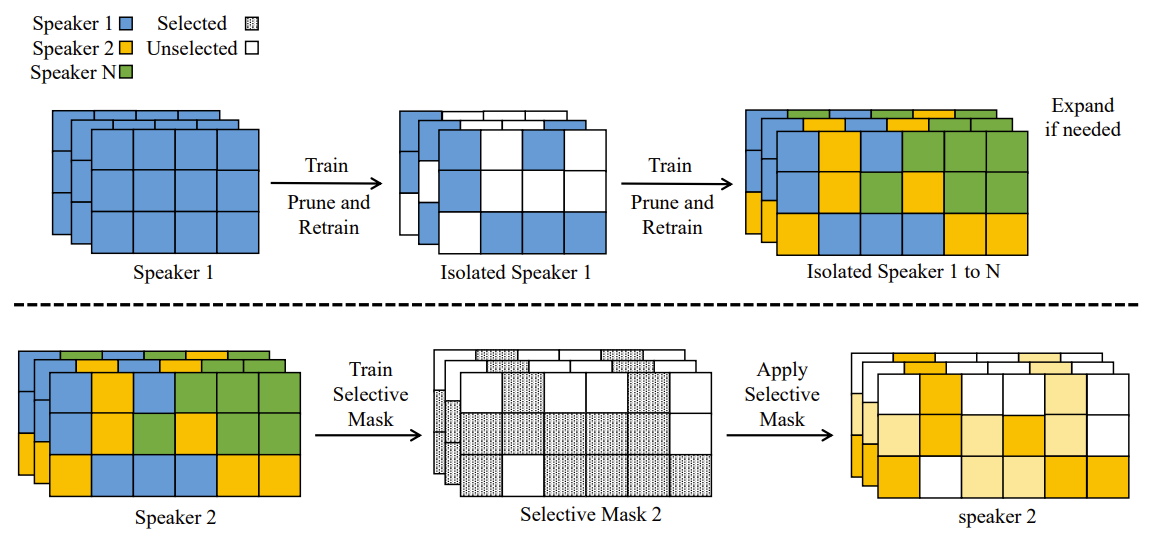
- First Round - Gradual Pruning Masks
- First round에서는 gradual pruning mask를 계산하고 각 speaker의 parameter를 isolate 함
- 1부터 $N$까지의 speaker를 $S_{1:N}$이라고 하면, $S_{1:N}$에 대한 task는 $T_{1:N}$이고, sequential 하게 시작됨 - $S_{t}$를 예로 들면,
- $T_{t}$가 시작되면 global model $M_{g}$가 $S_{t}$로 전달되고 수렴할 때까지 $S_{t}$의 private data를 통해 학습됨
- 이때 layer $i$에 대해 learned weight matrix는 $W_{1}^{l_{i}}$ - 이후 각 layer에 대해 $W_{1}^{l_{i}}$에서 가장 작은 weight를 gradually prune 하여 0으로 설정하고, 다른 weight를 re-train 하여 성능을 restore 함
- 여기서 weight는 세 부분으로 나누어짐:
- Later speaker $S_{t+1:N}$에 대해 release 된 zero-valued weight
- Previous speaker $S_{1:t-1}$에 의해 preserve 된 fixed weight $W^{1:t-1}_{S}$
- $S_{t}$에 의해 preserve된 weight $W^{t}_{S}$ - Later speaker $S_{t+1:N}$에 대해 release 된 weight가 threshold $\lambda$ 보다 작으면, 모델의 hidden size를 $\mu$만큼 expand함
- Pruning state는 $m_{p}$로 표현되는 gradual pruning mask에 store 됨 - 이후 $W_{S}^{t}$를 fix 하고 $m_{p}$와 $M_{g}$를 next speaker $S_{t+1}$로 보내 sequential training을 계속 수행
- $T_{t}$가 시작되면 global model $M_{g}$가 $S_{t}$로 전달되고 수렴할 때까지 $S_{t}$의 private data를 통해 학습됨
- First round가 끝나면, 각 speaker는 $m_{p}$로 represent 되는 weight의 특정 부분 $W^{1:N}_{S}$를 preserve 함
- 각 task의 weight가 fix 되어 있으므로, 각 speaker는 추론 시 자신의 tone을 perfectly retain 할 수 있음 - 최종적으로 $m_{p}$와 $M_{g}$는 $S_{1:N}$의 device로 전달됨
- 따라서 각 speaker는 $m_{p}, M_{g}$, private speaker module로 preserve 된 parameter를 가짐
- First round에서는 gradual pruning mask를 계산하고 각 speaker의 parameter를 isolate 함
- Second Round - Selective Masks
- Second round에서는 data 부족 문제를 해결하기 위해 speaker로부터 knowledge transfer를 수행하는 selective mask를 도입
- Selective mask는 speaker에 의해 preserve 된 useful weight를 자동적으로 select 하도록 학습됨
- 이를 위해 모든 speaker에 대해 equitable 하게 weight를 select 하는 modified selection procedure를 도입
- Second round에서 특정 speaker $S_{t}$에 대해 $W_{S}^{t}$와 selective mask의 joint training을 수행하지 않으면 성능 저하가 발생하기 때문
- First round가 종료되면, $M_{g}$의 weight가 $S_{1:N}$에 의해 preserve 되는 $W_{S}^{1:N}$으로 divide 된다고 가정하자
- 이때 privacy를 보호하면서 collaborative training을 활용하기 위해, learnable mask $m_{b} \in \{ 0,1\}$을 도입하여 다른 speaker가 preserve 한 parameter의 knowledge를 transfer
- Real-valued mask $m_{s}$를 학습하고 binarization에 대한 threshold를 적용하여 $m_{b}$를 구성하는 piggyback approach를 사용
- 여기서 특정 speaker $S_{t}$에 대해 mask $m^{t}_{b}$는 $m_{b}^{t}\odot W_{S}^{1:t-1}\cup W_{S}^{t+1:N}$에 의해 다른 speaker로부터 weight를 선택하도록 해당 local dataset으로 학습됨 - 1D convolution layer에서 selective mask의 training 과정을 예시로 들면,
- Task $t$에서 $M_{g}$ (i.e., $W_{S}^{1:N}$)가 fix 되고 binary mask를 $m^{t}_{b}$라고 하자
- 이때 input-output relationship에 대한 equation은:
(Eq. 1) $\tilde{W}=m_{b}^{t}\odot W$
(Eq. 2) $y(N_{i},C_{out_{j}})=b(C_{out_{j}})+\sum_{k=0}^{C_{in}-1}\tilde{W}(C_{out_{j}},k) \star x(N_{i},k)$
- $\star$ : valid cross-correlation operator, $N$ : batch size, $C_{in}$/$C_{out}$ : 각각 in/output channel
- Backpropagation 과정에서 $m_{b}^{t}$는 non-differentiable 함
- 따라서 real-valued selective mask $m_{s}^{t}$를 도입하고 $\sigma$를 selection threshold로 나타내자
- Binary mask $m_{b}^{t}$를 training 할 때 backward pass에서 real-valued mask $m_{s}^{t}$를 업데이트함
- 이를 통해 $m_{b}^{t}$는 $m_{s}^{t}$에 적용된 binarizer function $\beta$로 quantize 되고 forward pass에서 사용됨 - Training 이후에는 $m_{s}^{t}$를 discard 하고 추론을 위해 $m_{b}^{t}$만 store 함
- 결과적으로 $m_{s}^{t}$에 대한 equation은:
(Eq. 3) $m_{b}^{t}=\beta(m_{s}^{t})\left\{\begin{matrix} 1, & \textrm{if}\,\,\, m_{s}^{t}>\sigma \\ 0, & \textrm{else} \\ \end{matrix}\right.$
(Eq. 4) $\delta m_{s}^{t}(C_{out_{j}},k)=\frac{\partial L}{\partial m_{b}^{t}(C_{out_{j}},k)}=\frac{\partial L}{\partial y (N_{i},C_{out_{j}})}\cdot \frac{\partial y (N_{i},C_{out_{j}})}{\partial m_{b}^{t}(C_{out_{j}},k)}$ $\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, = \delta y (N_{i},C_{out_{j}})\cdot \sum_{k=0}^{C_{in}-1}\tilde{W}(C_{out_{j}},k)\star x(N_{i},k)$
- (Eq. 3), (Eq. 4)를 통해 각 speaker에 유용한 weight를 select 하도록 selective mask를 학습할 수 있음
- Second round에서는 data 부족 문제를 해결하기 위해 speaker로부터 knowledge transfer를 수행하는 selective mask를 도입
- Model Inference
- $S_{t}$를 예로 들면, $S_{t}$는 $m_{p}, m_{b}^{t}, M_{g}$와 speaker module의 locally preserved parameter를 가짐
- 이때 $m_{p}$를 사용하여 weight $W_{S}^{t}$를 pick 하고, $m_{b}^{t}$를 사용하여 $W_{S}^{1:t-1} \cup W_{S}^{t+1:N}$의 weight를 selectively reuse 함
- Unused weight는 $S_{t}$의 tone을 손상하지 않도록 0으로 fix 됨

3. Experiments
- Settings
- Dataset : VCTK
- Comparisons : FedAvg, CPG
- Results
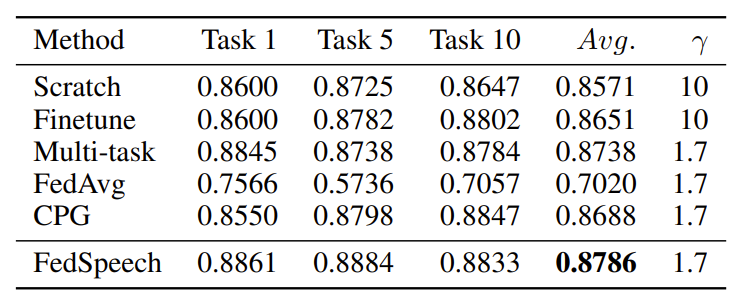
- MOS 측면에서 합성 품질을 비교해 보면, FedSpeech가 가장 우수한 성능을 보임
- 특히 FedAvg는 가장 나쁜 성능을 보이는데, 다른 speaker의 gardient가 각 speaker의 tone에 큰 영향을 미치기 때문

- Speaker similarity를 비교해 보면, 마찬가지로 FedSpeech가 가장 우수한 성능을 보임
- FedSpeech는 parameter isolation을 통해 추론 단계에서 각 speaker의 음성을 더 잘 유지할 수 있기 때문
- Knowledge를 selectively reusing 함으로써 federated multi-speaker TTS의 모든 speaker가 더 나은 음성을 얻을 수 있음
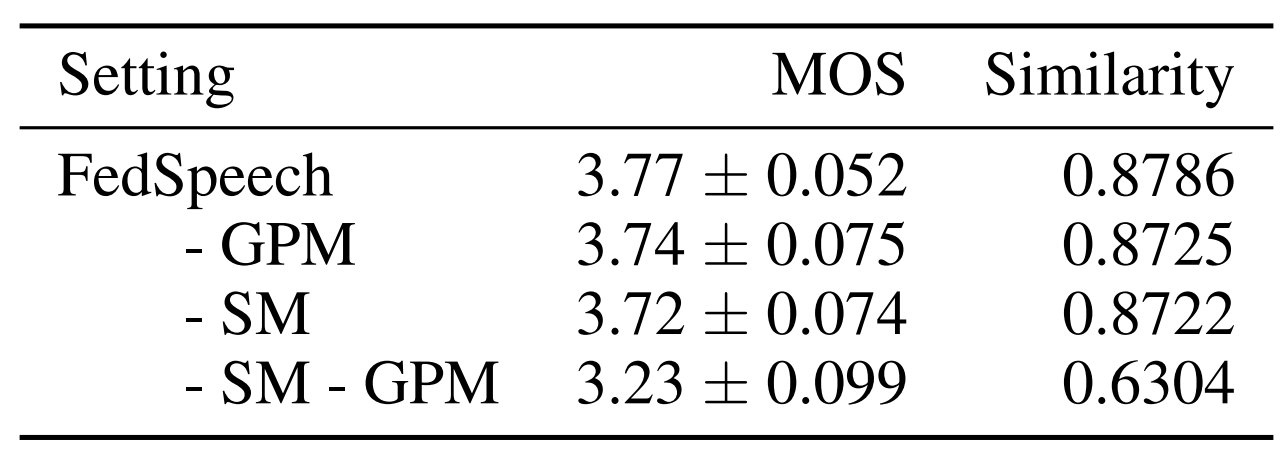
- FedSpeech에 대해 ablation study를 수행한 결과를 보면,
- Gradual Pruning Mask나 Selective Mask를 각각 제거해도 합성 품질과 similarity는 크게 떨어지지 않음
- 대신 두 가지 mask를 모두 제거하는 경우 품질과 similarity 저하가 크게 나타남
반응형
'Paper > TTS' 카테고리의 다른 글
댓글