

 [Paper 리뷰] FastSpeech: Fast, Robust and Controllable Text to Speech
[Paper 리뷰] FastSpeech: Fast, Robust and Controllable Text to Speech
FastSpeech: Fast, Robust and Controllable Text to Speech 기존의 Text-to-Speech (TTS) 모델은 text에서 mel-spectrogram을 생성한 다음, WaveNet과 같은 vocoder를 사용해 mel-spectrogram에서 음성을 합성함 End-to-end TTS 모델은 추론 속도가 느리고 합성된 음성이 robust 하지 않고, controllability (voice speed, prosody control)가 떨어짐 FastSpeech Mel-spectrogram을 병렬로 생성하는 transformer 기반 feed-forward network Phoneme duration 예측을 위해 encoder-decoder 기반 teacher 모..
 [Paper 리뷰] FastSpeech2: Fast and High-Quality End-to-End Text to Speech
[Paper 리뷰] FastSpeech2: Fast and High-Quality End-to-End Text to Speech
FastSpeech2: Fast and High-Quality End-to-End Text to Speech FastSpeech와 같은 non-autoregressive Text-to-Speech (TTS) 모델은 빠르게 음성합성이 가능함 FastSpeech는 duration prediction과 knowledge distillation을 위해 autoregressive teacher 모델에 의존적임 Teacher-student distillation 과정이 복잡하고 시간 소모적임 Teacher 모델에서 추출한 duration이 정확하지 않고 target mel-spectrogram의 단순함으로 인해 정보 손실이 발생함 FastSpeech 2 Teacher의 단순화된 output 대신 ground-tru..
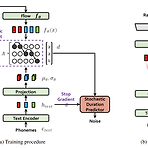 [Paper 리뷰] Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
[Paper 리뷰] Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech Single-stage 학습을 가능하게 하는 end-to-end 방식의 text-to-speech (TTS) 모델이 제안되었지만 여전히 two-stage TTS 모델들보다 음성 품질이 낮음 Two-stage TTS 모델보다 더 자연스러운 음성을 생성하는 병렬 end-to-end TTS 모델이 필요 VITS (Variational Inference with adversarial learning for end-to-end Text-to-Speech) Normalizing flow와 적대적 학습 방식을 사용한 variational 추론을 통한 생성..